
Repository:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
预训练结构
第一阶段
网络结构如下图。
- 对于图像特征,采用DETR类似的思路,使用Learned Queries作为输入,Image Features作为cross attention的KVs,希望通过可学习的参数来抽取与文本更相关的视觉特征
- 对于文本特征,采用传统的Bert Encoder思路
- 对于多模态特征的融合,与双流模型不同,这里两个Encoder的self attention层是共享参数的,当然与单流模型也不同,因为FFN不共享参数,且视觉特征提取时还会走cross attention层
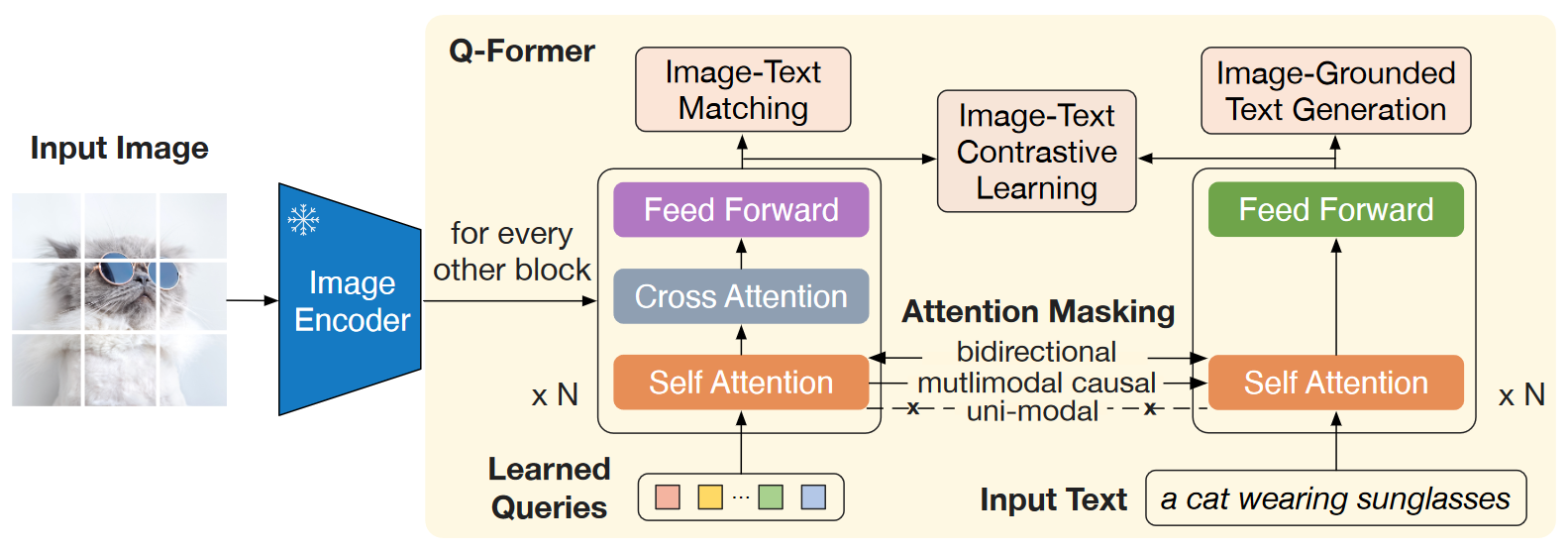
训练采用的三个Loss函数(ITG/ITM/ITC)主要参考之前的ALBEF工作。
- Image-Text Contrastive : 这部分的目的主要是对齐图像特征和文本特征的单模态特征,计算方法类似CLIP。与ALBEF不同的是,这里的negative pairs直接采用in-batc方式得到,并没有像ALBEF那样借鉴MOCO得到一个较大的Dictionary
- Image-Text Matching : 这部分的目的是学习图像特征与文本特征的细粒度对齐,通过外接二分类器计算Loss。这一阶段Query和Text可以互相关注
- Image-Grounded Text Generation : 这一部分主要是训练Queries捕获有关文本所有信息的视觉特征,因为在这一步Query是无法看到Text信息的,而Text可以通过self attention层看到Query并输出结果,所以Query只能从Image Feature中尽可能提取与文本相关的视觉特征,才能生成一个质量比较高的Text(一个直观理解的explanation)
第二阶段
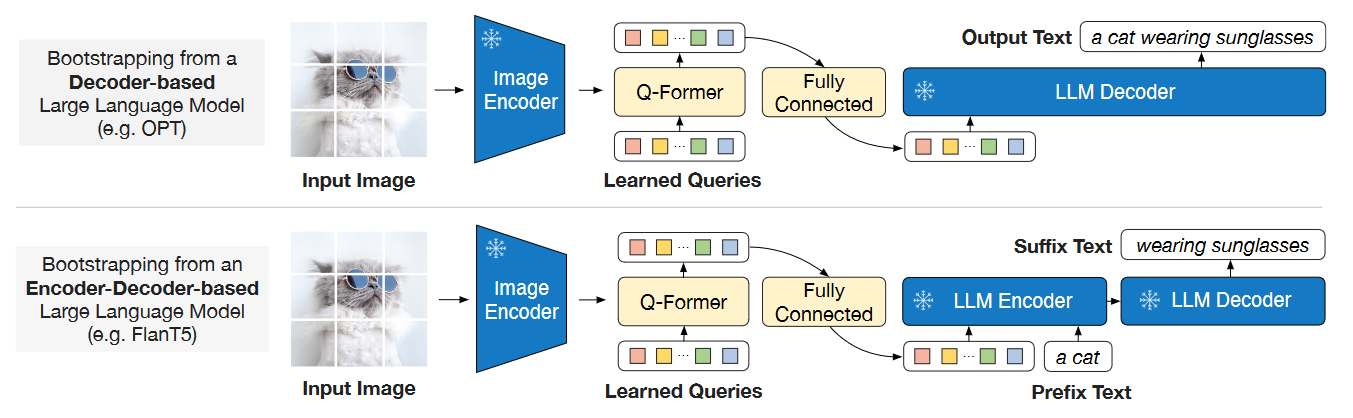
第二阶段的网络结构如下,通过一个FC对齐Qformer与LLM的维度,并对Qformer进一步微调。Qformer的输出主要作为LLM的一个soft visual prompts,提示LLM的输出。
源码
BLIP2的model文件在lavis/models/blip2_models下,之后默认以此为根目录
阅读顺序(主要类与函数)如下:
-
../base_model.py :
BaseModel(nn.Module) -
blip2.py :
Blip2Base,compute_sim_matrix -
Qformer.py :
BertEmbeddings,BertLayer,BertEncoder,BertPooler,BertModel,BertOnlyMLMHead,BertLMHeadModel -
blip2_qformer.py :
Blip2Qformer,
关注点主要是Qformer的实现,其实就是一个魔改的Bert:
- Learned Queries和Text会一起进入Encoder做attention,两者之间的交互由self-attention层的mask控制,具体mask信息参照论文Figure 2
- 魔改的Bert会每隔1个Encoder Layer()就在该层self-attention层后添加一个cross-attention层,其KVs是Image Encoder的输出即视觉特征
- 只有Query部分激活cross-attention层进行计算,会通过
input[:, :query_length, :]进行截取;同理,如果输入只有Text(Unimodal)则根本不会进行cross-attn计算 past_key_values或者说KV cache是在自回归decoder推理时加速的trick,具体来说就是decoder上一次运算各层attention的结果KVs(即当前所有token的embedding信息)会被保存,下次运算时,只需要输入新的token(seq_len=1),进行attention计算时加入之前保存的KVs即可。这样做的可行性主要来自自回归模式的无后效性,token做attention时只会和自己以及之前的token交互- 在Qformer第一阶段训练中,
past_key_values只使用一次:单模态阶段分别encode图像(Query)特征和文本特征,在encode图像(Query)特征时保存各个attn层的KVs;在计算ITG损失时,由于Query和Text都可以看到所有Query,于是这里就使用了当时单模态计算Query特征时的KVs,模型就只需要跑Text部分即可(使用past_key_values后,Query不需要也不能拼接在Text前面作为输入) - 一般来说计算ITM损失时也可以利用计算单模态Query时的产生的KVs,代码里之所以没这么做,是因为计算ITM时额外使用了hard negatives mining,输入已经发生变化
评论