序言
在2016年的CVPR会议上,继YOLOv1工作后,原作者再次推出YOLOv2(YOLO9000)。相较于上一代的YOLOv1,YOLOv2在其基础之上做了大量的改进和优化,不仅仅是对模型本身做了优化,同时还引入了由Faster R-CNN工作提出的anchor box机制,并且使用了kmeans聚类方法来获得更好的anchor box,边界框的回归方法也因此做了调整。在VOC2007数据集上,YOLOv2超越了同年发表在ECCV会议上的SSD工作,是那个年代当之无愧的最强目标检测器之一。那么,接下来就让我们去看看YOLOv2究竟做了哪些改进吧。
较之先前工作的改进
添加Batch Normalization
在YOLOv1中,每一层卷积的结构都是线性卷积和激活函数,并没有使用诸如批归一化(batch normalization,简称BN)、层归一化(layer,normalization,简称LN)、实例归一化(instance normalization,简称IN)等任何归一化层。
这一点是受限于那个年代的相关技术的发展,而以现在的眼光来看,这些归一化层几乎是搭建网络的标配,尤其是在计算机视觉领域中,BN层几乎随处可见。

这项改进使YOLO在VOC2007测试集上的mAP从63.4%提升到了65.8%
高分辨率的主干网络
在YOLOv1中,其backbone先在ImageNet上进行预训练,预训练时所输入的图像尺寸是224×224,而做检测任务时,YOLOv1所接收的输入图像尺寸是448×448。因此在训练过程中,网络必须要先克服由分辨率尺寸的剧变所带来的问题。直觉上来说,backbone网络在ImageNet上看得都是224×224的低分辨率图像,突然看到448×448的高分辨率图像,难免会“眼晕”。
为了缓解这一问题,作者将已经在224×224的低分辨率图像上训练好的分类网络又在448×448的高分辨率图像上进行微调(fine tuning),共微调10个轮次。微调完毕后,再去掉最后的全局平均池化层和softmax层,作为最终的backbone网络。
YOLOv1网络获得了第二次性能提升:从65.8% mAP提升到69.5% mAP。
这一技巧并未成为主流训练技巧,可能这个问题并不算严重,稍微延长训练时间便可以了。
锚框(anchor box)机制
anchor box,字面翻译为“锚框”。锚框的意思是将一堆边界框放置在特征图网格的每一处位置(每个像素),通常每个位置都放置相同数量的相同尺寸的锚框,如下图。
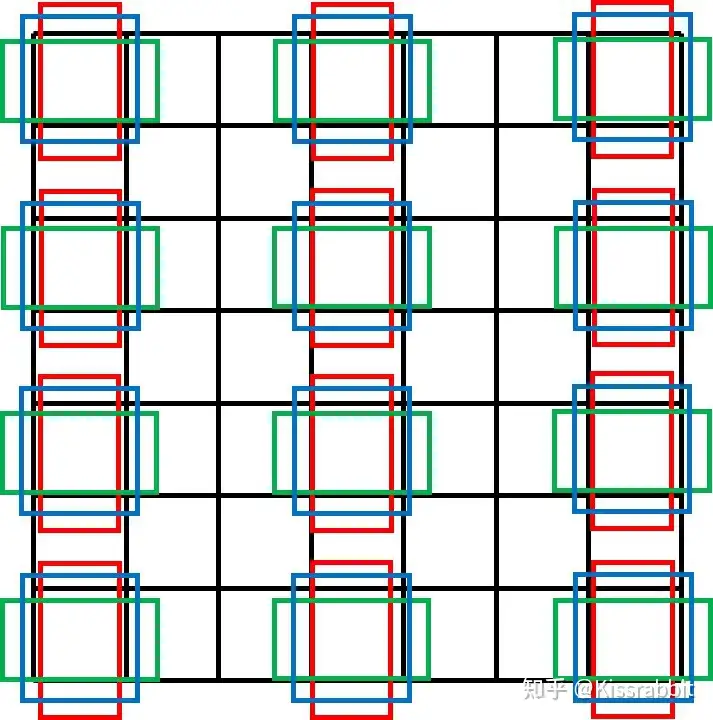
该图并不完整 每两个pixel才绘制一次锚框
这一机制最早是在Faster R-CNN工作中提出的,用在RPN网络中,RPN网络在这些预先放置好的锚框上去为后续的预测提供感兴趣区域(Region of Interest,RoI)。每个网格处设定了k个不同尺寸、不同宽高比的anchor box,RPN网络会为每一个anchor box学习若干偏移量:中心点的偏移量和宽高的偏移量。用这些偏移量去调整每一个anchor box,得到最终的边界框。由此可见,anchor box的本质是提供边界框的尺寸先验,网络使用偏移量在这些先验值上进行调整,从而得到最终的尺寸,对于边界框的学习,不再是之前的“无中生有”了。因此,anchor box与其直接翻译成“锚框”,不如翻译成“先验框”更加贴切。加入先验框的目标检测网络,后来都被称为“Anchor-based”模型。
设计先验框的一个难点在于设计多少个先验框,且每个先验框的尺寸(宽高比和面积)又是多少。对于宽高比,研究者们通常采取的配置是1 : 1、1 : 3以及3 : 1;对于面积,常用的配置是32、64、128、256以及512。
以上述两个配置为例,每一个面积都使用3个长宽比,因此,不难算出共有15个先验框,即k=15。对于一个13×13的网格,每一处的网格都要放置15个先验框,因此,这张网格上共有13×13×15=2535个先验框。如果我们用更多的网格,这个数量会更多。先验框越多,所需的参数量就越大,自然就会带来更多的计算量上的压力。
论文里权衡了Average IOU后选择了k=5 兼顾了运算效率
总之,先验框的作用就是提供边界框的尺寸先验信息,让网络只需学习偏移量来调整先验框去获得最终的边界框,相较于YOLOv1的直接回归边界框的宽高,基于先验框的方法表现得往往更好。
全卷积网络结构
在YOLOv1中,有一个很显著的问题就是网络在最后阶段使用了全连接层,这不仅破坏了先前的特征图所包含的空间信息结构,同时也导致参数量爆炸。为了解决这一问题,作者便将其改成了全卷积结构,并且添加了Faster R-CNN工作所提出的anchor box机制。具体来说,首先,网络的输入图像尺寸从448改为416,去掉了YOLOv1网络中的最后一个池化层和所有的全连接层,修改后的网络的最大降采样倍数为32,最终得到的也就是13×13的网格,不再是7×7。每个网格处都预设了k个的anchor box。网络只需要学习将先验框映射到真实框的尺寸的偏移量即可,无需再学习整个真实框的尺寸信息,这使得训练变得更加容易。
其实,在之前的YOLOv1中,我们已经知道每个网格处会有1个边界框输出,而现在变成了预测k个先验框的偏移量。原先的YOLOv1中,每个网格处的B个边界框都有一个置信度,但是类别是共享的,因此每个网格处最终只会有一个输出,而不是B个输出(置信度最高的那一个),倘若一个网格包含了两个以上的物体,那必然会出现漏检问题。加入先验框后,YOLOv2改为每一个先验框都预测一个类别和置信度,即每个网格处会有多个边界框的预测输出。因此,现在的YOLOv1的输出张量大小是S×S×k×(1+4+C),每个边界框的预测都包含1个置信度、4个边界框的位置参数和C个类别预测。

尽管网络结构变成了全卷积网络,并使用了anchor box机制,但网络的精度并没有提升,反倒是略有所下降,69.5% mAP降为69.2% mAP,但召回率却从81%提升到88%。召回率的提升意味着YOLO可以找出更多的目标了,尽管精度下降了一点点。由此可见,每个网格输出多个检测结果确实有助于网络检测更多的物体。因此,作者并没有因为这微小的精度损失而放弃掉这一改进。
backbone
主干网络从类GoogLenet换成了Darknet19,Darknet19网络结构如下图。
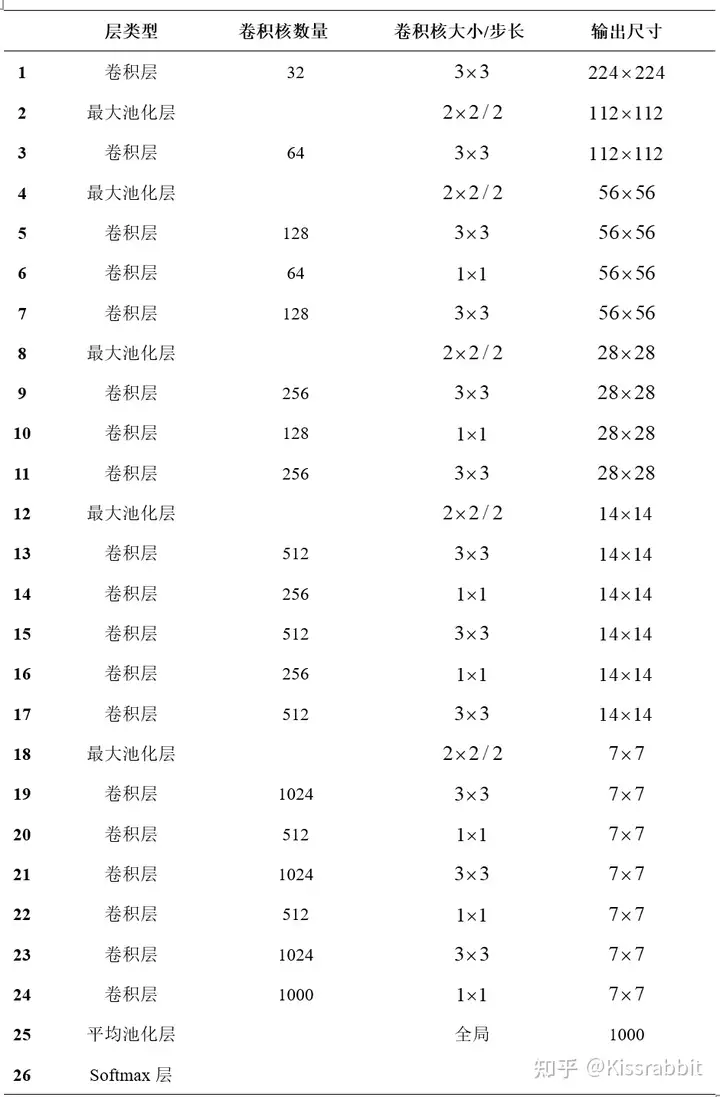
这里的卷积层由之前提到的三部分组成——线性卷积、BN、LeakyRelu。
The 19 of Darknet19 means the network has 19 conv layers.
作者首先将DarkNet19在ImageNet上进行预训练,获得了72.9%的top1准确率和91.2%的top5准确率。在精度上,DarkNet19网络达到了VGG网络的水平,但前者模型更小。
预训练完毕后,去掉表最后第24层的卷积层、第25层的平池化层以及第26层的softmax层,然后换掉原先的backbone网络。于是,YOLOv1网络从上一次的69.2% mAP提升到69.6% mAP。
kmeans聚类先验框
在之前说到的anchor box机制中,这些先验框(即anchor box)的一些参数需要人工设计,包括先验框的数量和大小。在Faster R-CNN中,这些参数都是由人工设定的,然而YOLO作者认为人工设定的不一定好。为了去人工化,作者采用kmeans方法在VOC数据集上进行聚类,一共聚类出k个先验框,通过实验,作者最终设定 。聚类的目标是数据集中所有检测框的宽和高,与类别无关。为了能够实现这样的聚类,作者使用IoU作为聚类的衡量指标,$d(box,centroid)=1-IoU(box,centroid)$
通过kmeans聚类的方法所获得的先验框显然会更适合于所使用的数据集,但这也会带来一个问题:从A数据集聚类出的先验框显然难以适应新的B数据集。尤其A和B两个数据集中所包含的数据相差甚远时,这一问题会更加的严重。因此,当我们换一个数据集,如COCO数据集,则需要重新进行一次聚类,如果样本不够充分,这种聚类出来的先验框也就不够好,这也是YOLOv2以及后续的YOLO版本的潜在问题之一。另外,由聚类所获得的先验框严重依赖于数据集本身,倘若数据集规模过小、样本不够丰富,那么由聚类得到的先验框也未必会提供足够好的尺寸先验信息。当然,即便是人工设计的先验框也有着类似的问题,甚至整个anchor-based模型都有这一类问题,所以才有了后来的anchor free工作,
在YOLOv2工作中,换上新的先验框后,对边界框的预测也发生了变化。
首先,对每一个边界框,YOLO仍旧去学习中心点偏移量tx和ty 。我们知道,这个中心点偏移量是介于01范围之间的数,在YOLOv1时,作者没有在意这一点,直接使用线性函数输出,这显然是有问题的,在训练初期,模型很有可能会输出数值极大的中心点偏移量,导致训练不稳定甚至发散。于是,作者使用sigmoid函数使得网络对偏移量的预测是处在01范围中。我们的YOLOv1+正是借鉴了这一点。
其次,对每一个边界框,由于有了边界框的尺寸先验信息,故网络不必再去学习整个边界框的宽高了。假设某个先验框的宽和高分别为pw和pℎ,网络输出宽高的偏移量为tw和tℎ,则使用以下公式即可解算出边界框的宽和高。
$$
w = p_w e^{t_w} \quad h = p_h e^{t_h}
$$

这种边界框预测方法,在论文中被命名为“location prediction”。
使用kmeans聚类方法获得先验框,再配合“location prediction”的边界框预测方法,YOLOv1的性能得到了显著的提升:从69.6% mAP提升到74.4% mAP。不难想到,性能提升的主要来源在于kmeans聚类,更好的先验信息自然会有效提升网络的检测性能。只不过,这种先验信息是依赖于数据集的。
聚类具体代码实现见K-means 计算 anchor boxes_hrsstudy的博客-CSDN博客_kmeans-anchor-boxes
Passthrough
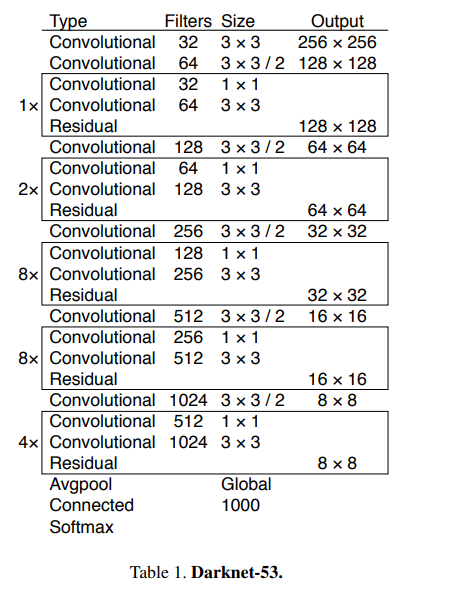
随后,YOLO作者又借鉴了同年的SSD工作:使用更高分辨的特征。在SSD工作中,检测是在多张特征图上进行的,不同的特征图的分辨率也不同。可以理解为,特征图的分辨率越高,所划分的网格也就越精细,能够更好地捕捉目标的细节信息。相较于YOLOv1只在一张7×7的过于粗糙的网格上做检测,使用多种不同分辨率的特征图自然会更好。
于是,YOLO作者借鉴了这一思想。具体来说,之前的改进中,YOLOv1都是在最后一张大小为13×13×1024的特征图上进行检测,为了引入更多的细节信息,作者将backbone的第17层卷积输出的26×26×512特征图拿出来,做一次特殊的降采样操作,得到一个13×13×2048特征图,然后将二者在通道的维度上进行拼接,最后在这张融合了更多信息的特征图上去做检测。

这里的特殊降采样操作并不是常用的步长为2的池化层或步长为2的卷积操作,而是一种类似于在图像分割任务中常用到的pixelshuffle操作的逆操作,如图7所示。依据YOLO官方配置文件中的命名方式,我们暂且称之为reorg操作。

特征图在经过reorg操作的处理后,特征图的宽高会减半,而通道则扩充至4倍,因此,从backbone拿出来的26×26×512特征图就变成了13×13×2048特征图。这种特殊降采样操作的好处就在于降低分辨率的同时,没丢掉任何细节信息,信息总量保持不变。
这一改进在论文中被命名为“passthrough”。加上该操作后,在VOC 2007测试集上的mAP从74.4%再次涨到了75.4%。由此可见,引入更多的细节信息,确实有助于提升模型的检测性能
多尺度训练
cv中有一个十分常见的图像处理操作是图像金字塔,即将一张图像缩放到不同的尺寸,同一目的,在不同分辨率的图像中,所包含的信息量也不一样,直观的体现便是分辨率越高,构成目标所需要的像素量就越多,目标本身的大小(或像素面积)也就越大。通过使用图像金字塔的操作,网络能够在不同尺寸下去感知同一目标,从而增强了其本身对目标尺寸变化的鲁棒性,如下图所示。YOLO作者便将这一思想用到了模型训练中,以提升YOLO对物体的尺度变化的适应能力。

该方法在myYOLOv1也使用到 具体YOLOv1.md
最终网络结构

DarkNet网络结构如下,使用全卷积代替了全连接层

Anchor box匹配
该部分和损失函数并没有在论文中提及,参考(60条消息) 论文笔记1 --(YOLOv2)YOLO9000:Better,Faster,Stronger_零尾的博客-CSDN博客_yolov2论文和源码可以得到以下信息。
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与ground truth的IOU最大的边界框预测它,而剩余的4个边界框不与该ground truth匹配。YOLOv2同样需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的先验框计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的边界框只计算置信度误差(此时target为0)。
对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。
损失函数
损失函数与yolov1相差不大,主要修改了引入锚框的几项,如下图所示。


- (1)W,H分别指的是特征图(13*13)的宽与高
- (2)A指的是先验框数目(这里是5)
- (3)各个λ值是各个loss的权重系数,参考YOLOv1的loss
- (4)第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差
- (5)第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状
- (6)第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。
尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。
另外需要注意的一点是,在计算boxes的和误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale (2 - truth.wtruth.h),这样对于尺度较小的boxes其权重系数会更大一些,起到和YOLOv1计算平方根相似的效果。
"语义歧义"问题
理想情况下,每个真实样本都会匹配到一个先验框,作为正样本,其余的先验框要么成为负样本,要么被忽略。但是,稍加思考,不难发现这其中有个问题,那就是倘若有两个目标的中心点都落在同一个网格,有没有可能原本分配给目标A的先验框后来又分配给了目标B,导致目标A就没有匹配上的先验框,从而丢失了正样本,这种问题有时被称为“语义歧义(semantic ambiguity)”。
复现
代码主要框架与myYOLOv1一致。主要修改了模型文件yolov2.py/骨干网络backbone/正样本制作方法matcher.py/损失函数loss.py
测试
测试效果如下。


python eval.py --cuda -d voc --weight ./weights/yolov2_voc.pth --save
评估
yolov2+在voc2007测试集上的mAP达到了0.785

python eval.py --cuda -d voc --weight ./weights/yolov2_voc.pth -size 608
代码
详见JJJYmmm/MyYOLOv2 (github.com)



























-解读YOLOv3")