
找到一个Github star比较多的CLIP跑起来玩一下。结果发现挺多坑的......(我发现Shariatnia好像很喜欢在Jupyter改代码,却不把改动更新到源文件)
项目地址:https://github.com/moein-shariatnia/OpenAI-CLIP
关于Loss的一些问题
CLIP网络的输入是一个个图像-文本对,对于一个batch_size=8的输入,总共有8个正样本对和56个负样本对。于是我们可以使用torch.eye来创建标签值。在这个项目中,由于Flicker-8k数据集较小,而且一张图片对应5个caption,所以作者使用文本(图像)之间的相似度作为标签,如下代码块。
targets = F.softmax(
(images_similarity + texts_similarity) / 2 * self.temperature,
dim=-1)
texts_loss = cross_entropy(logits, targets, reduction='none')
images_loss = cross_entropy(logits.T, targets.T, reduction='none')这引发了我几个问题:
-
images_loss和texts_loss好像写反了?(虽然这并不影响模型的训练,因为最终的loss是两者的平均) 在原论文中,images_loss指的是针对某个文本,images的分类损失 -
使用图像(文本)的embeddings之间的相似度来作为标签值,这确实可以处理一个batch中出现重复图片(文本)的问题,并且带有Pseudo-Labelling的味道。但是这样处理同样也会出现问题,1)如果不使用预训练模型,那么训练初期得到的图像(文本)相似度没有意义,无法作为标签值,即一定需要一个好的预训练模型;2)训练后期,出现过拟合现象,两个encoder或投影层会倾向于输出相差不大的向量,从而得到一个较低的loss,这类似于GAN中的模式坍塌(实际上, 如果将模型的学习率统一改成较大的一个值例如
lr=1e-3,那么一个epoch之后,你就会发现无论输入什么文本,模型给出的图像检索结果都是固定的,如果你问我为什么发现,其实作者的代码一开始就是这么写的555)model = CLIPModel().to(CFG.device) optimizer = torch.optim.AdamW( model.parameters(), lr=CFG.lr, weight_decay=CFG.weight_decay) lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau( optimizer, mode="min", patience=CFG.patience, factor=CFG.factor) -
我同样好奇
(images_similarity + texts_similarity) / 2这一步是否正确。对于images_loss,我们可以通过images_similarity找到重复(类似)的图像,从而给他们相同的标签值。但是texts_similarity是否可以指导images_loss? 我认为不能,因为文字具有多义性,两段文本类似,不代表对应的图片就是类似的。所以我尝试修改了loss函数,使它更符合直觉,如下。images_similarity = F.softmax(images_similarity, dim=-1) texts_similarity = F.softmax(texts_similarity, dim=-1) images_loss = cross_entropy(logits, images_similarity, reduction='none') texts_loss = cross_entropy(logits.T, texts_similarity, reduction='none')
实验结果
为了验证我的猜想,我做了一些实验。
①模式坍塌
正如上文所说,如果两个Encoder学习率过大,那么会发生模式坍塌现象。这里就不再赘述,大家可以自己试一下~
②Loss Function && Temperature
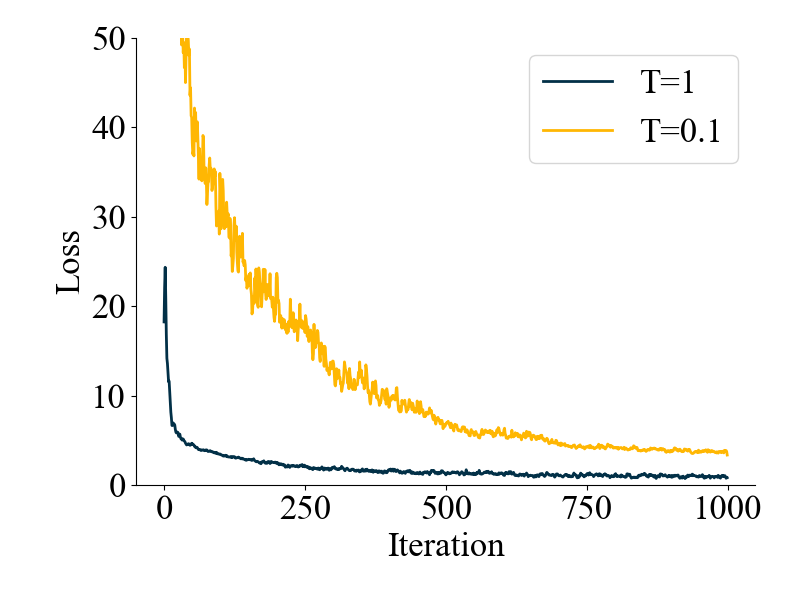
首先我修改了一下Temperature这个超参(原论文里这是一个可学习参数,数值最后稳定在100左右),motivation在于:我发现使用similarity作为label值,正负样本对之间的差距有点小(大概是2.5%),所以我想把T调小一点,增大他们之间的差距。当然,结果好像不是很好(T=0.1,可能给小了)
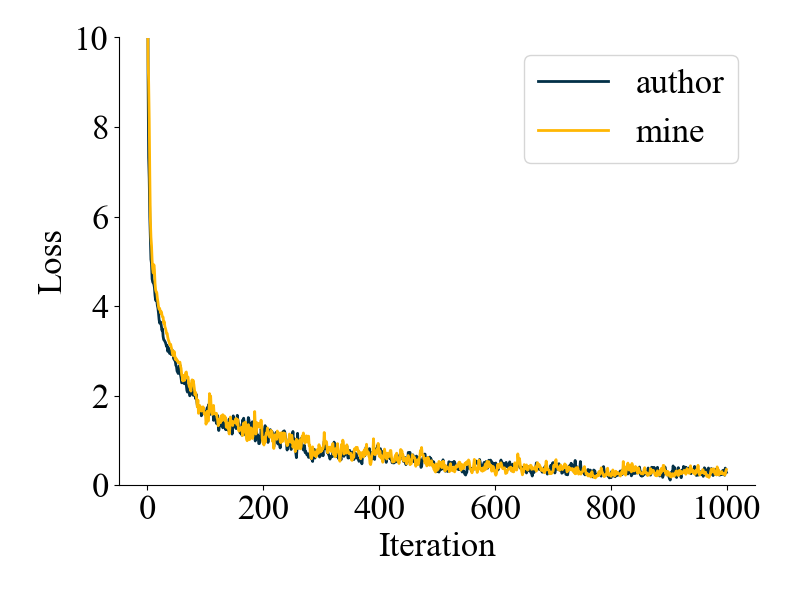
第二个实验是关于(images_similarity + texts_similarity) / 2这一步similarity平均的效果,我使用了上文提到的分别计算的方法进行对比,结果发现:没啥区别... valid_loss也几乎没差
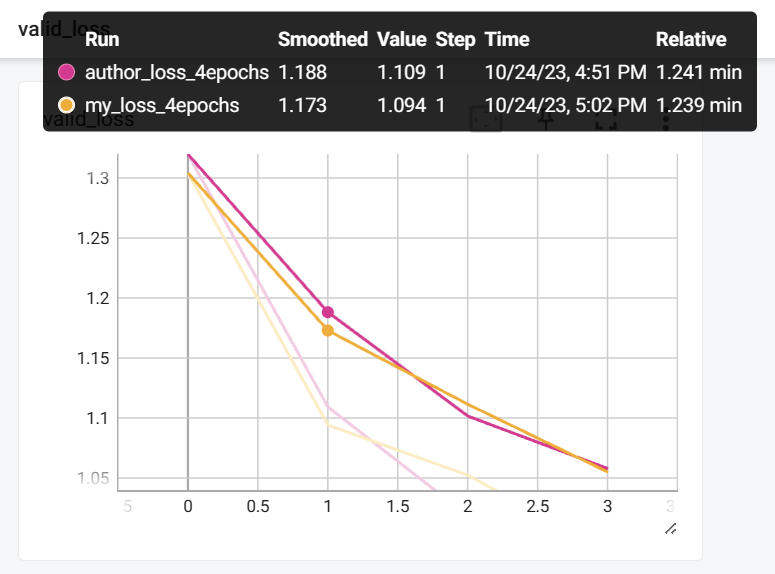
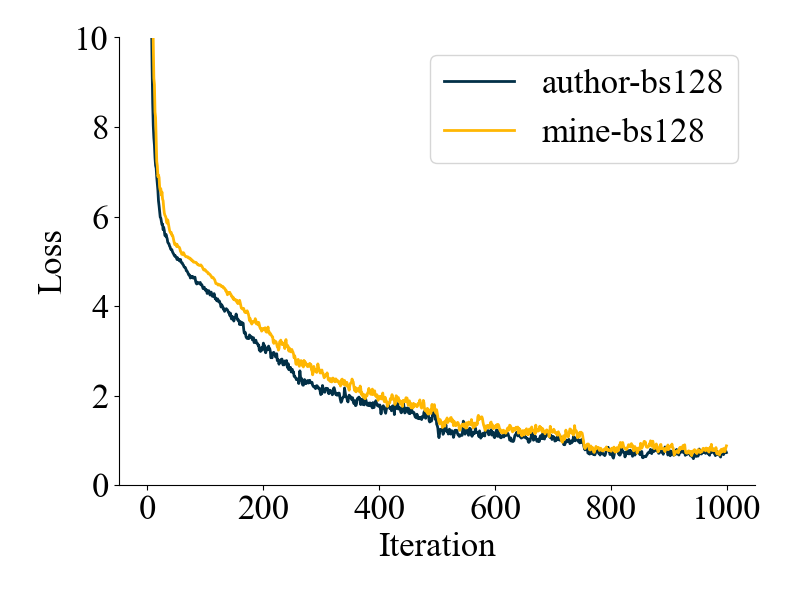
我猜测可能是因为batch_size不够大,即图片(文本)重复的概率不够大。所以我把batch_size从32调到了128,结果发现:好像平均可以加快收敛,但是为什么可以,还是有点不够intuitive...(也有可能单纯没差~)
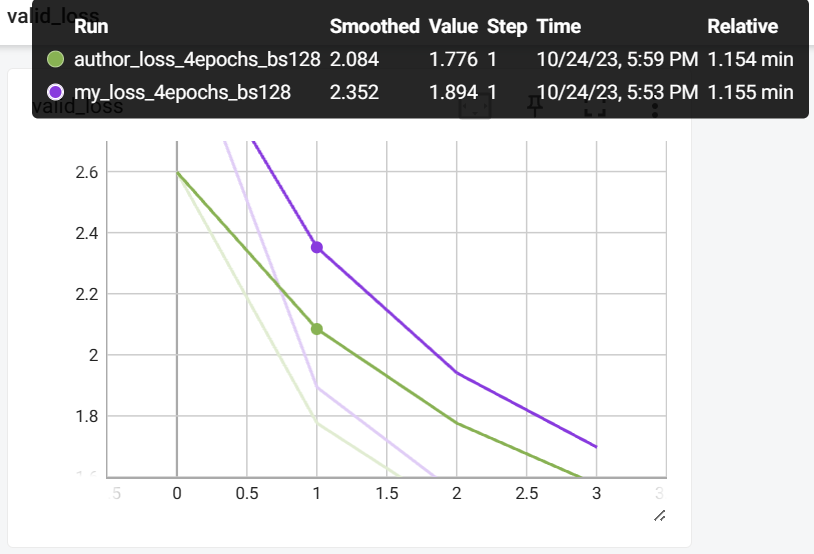
③Prompt Engineering
Prompt的好坏可以通过两幅图表示,我使用训练了5个epoch的模型权重。
当我们使用so many dogs作为query时,可以发现检索出来的图片除了狗以外,还有一些成群的鸭子或鸽子,这可能是因为text encoder同时注意到了many。

当我们使用a photo of dogs作为query时,可以发现检索出来的图片就都是狗了。

当然还可以像CLIP官方那样使用80个prompt做prompt ensembling。
总结
CLIP是一篇利用对比学习完成多模态特征对齐的工作,它的ZERO-SHOT能力非常亮眼(毕竟在400million的数据集上训练的...),同时也因为多模态的特点,可以引出很多有趣的应用,比如图像检索、编辑、生成等等。
评论