
pix2seq implement by Pytorch
source code : moein-shariatnia/Pix2Seq
paper : http://arxiv.org/abs/2109.10852
这次解析的源码是非官方实现的Pix2Seq,项目地址如上。教程直接看作者的Readme或者Object Detection w/ Transformers Pix2Seq in Pytorch | Towards AI,总体还是比较详细的。
模型即训练源码基本没什么问题,不过推荐先看完原始论文,不然可能在一些细节方面卡住。代码问题主要出现在测试文件中,问题如下。
Issue 1
2023.8.30
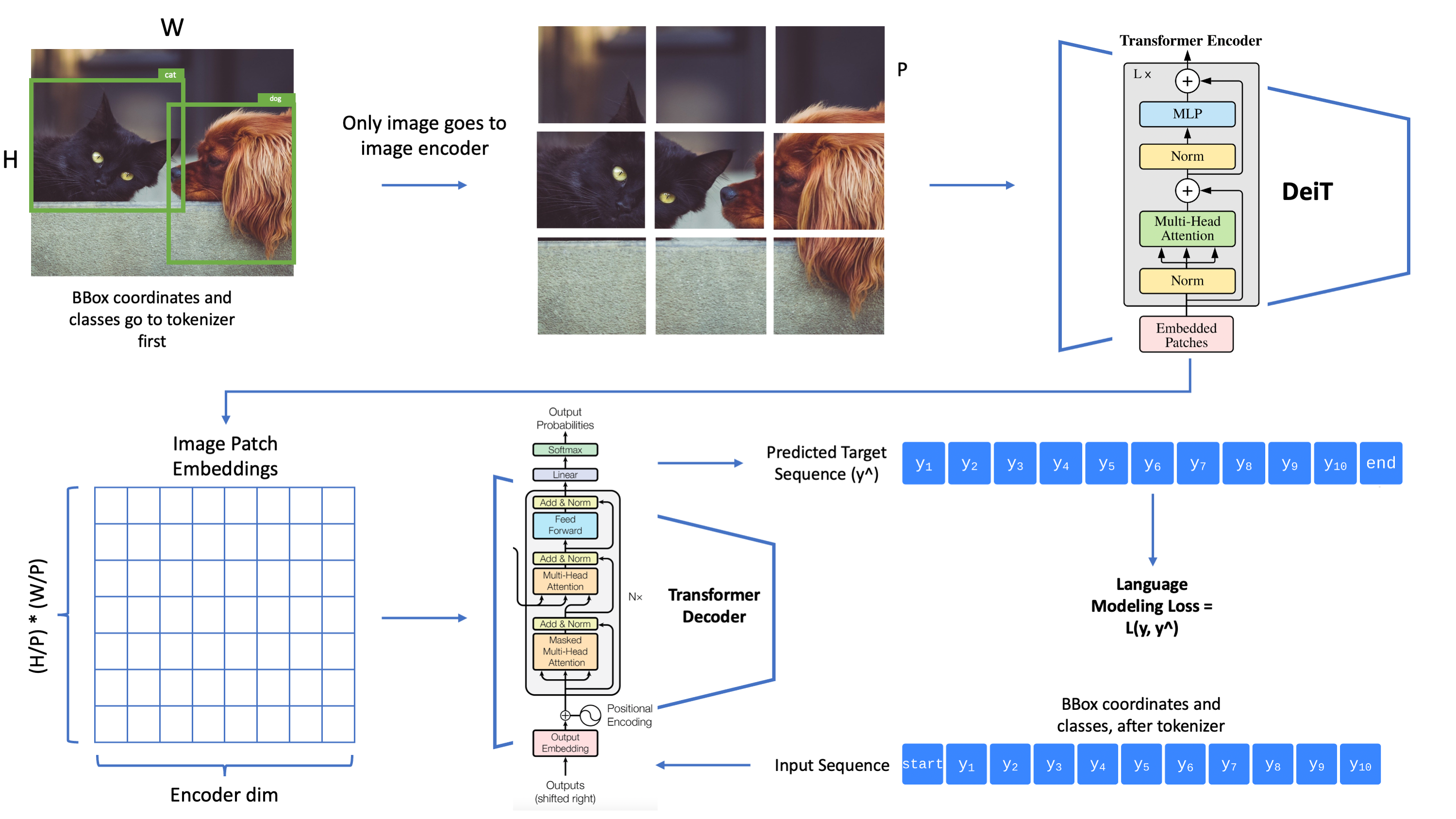
Tokenizer类的max_len参数用于限制单张图片的Obejct个数
labels = labels.astype('int')[:self.max_len]
bboxes = self.quantize(bboxes)[:self.max_len]而get_loaders中的collate_fn,把max_len作为输入序列的最大长度,这两处地方出现了矛盾(因为一个Object对应5个token,[x1, y1, x2, y2, class] )
if max_len: # [B,max_seq_len,dim] -> [B,max_len,dim]
pad = torch.ones(seq_batch.size(0), max_len -
seq_batch.size(1)).fill_(pad_idx).long()
seq_batch = torch.cat([seq_batch, pad], dim=1)Issue 2
2023.8.31
test.py中的postprocess函数存在问题,没有考虑model未检出object的情况。导致会将一个空序列(即\<EOS>\<BOS>)输入tokenizer的decoder方法,从而引发错误
for i, EOS_idx in enumerate(EOS_idxs.tolist()):
if EOS_idx == 0:
all_bboxes.append(None)
all_labels.append(None)
all_confs.append(None)
continue修正如下,考虑空序列的情况
for i, EOS_idx in enumerate(EOS_idxs.tolist()):
if EOS_idx == 0 or EOS_idx ==1: # invalid idx which EOS_idx = 0 or the model detect nothing when EOS_idx = 1
all_bboxes.append(None)
all_labels.append(None)
all_confs.append(None)
continueIssue 3
2023.8.31
test.py 中的第125行,发生类型判断错误。这里是剔除没有检测出物体的图片,但是此时lambda表达式中的x是array类型,所以isinstance函数参数不应该是list。否则过滤后preds_df会是空表
# preds_df = preds_df[preds_df['bbox'].map(lambda x: isinstance(x, list))].reset_index(drop=True)
# fix : list -> np.ndarray
preds_df = preds_df[preds_df['bbox'].map(lambda x: isinstance(x, np.ndarray))].reset_index(drop=True)Issue 4
2023.9.1 按道理这个很影响结果啊,毕竟图片之间的映射都错了。加上Issue 3,感觉作者写完教程,整理源码后,并没有再测试test.py这个文件了。
test.py第117行开始,保存预测结果。这里的原意应该是把预测结果对应回每张图片的id,但是源码直接对valid_df做了截断,这里很明显导致了部分图片的id被trunc了(这是因为valid_df将同一图片中的不同物体分成了若干行,如果直接按照总的图片数目进行截断,后面的一些图片id就会被截掉)。使用valid_df['id'].unique()进行修改,正好与133行代码对应。能这么做也是因为data loader的shuffle=False。
# preds_df = pd.DataFrame()
# valid_df = valid_df.iloc[:len(all_bboxes)]
# preds_df['id'] = valid_df['id'].copy()
# preds_df['bbox'] = all_bboxes
# preds_df['label'] = all_labels
# preds_df['conf'] = all_confs
# I think there is some bug above, because the code \
# do not consider the corresponding id of image, \
# it just trunc the valid_df with len(all_bboxes)!!!
preds_df = pd.DataFrame()
preds_df['id'] = valid_df['id'].unique().copy()
preds_df['bbox'] = all_bboxes
preds_df['label'] = all_labels
preds_df['conf'] = all_confs
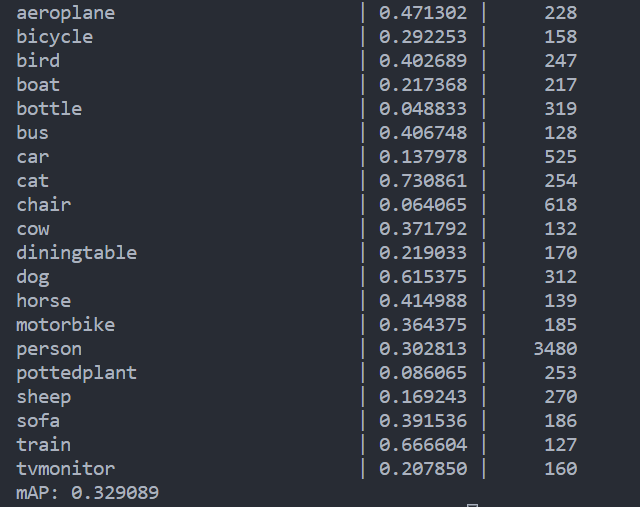
# line_133 : valid_df = df[df['id'].isin(preds_df['id'].unique())].reset_index(drop=True)使用作者提供的权重文件,跑出来的结果确实比原作者给出的结果(mAP=0.264399)高出7%左右,而且由于上述逻辑错误,作者的结果其实只在基本一半数量的box做了mAP的计算(因为测试图片就少了快一半),如果使用全量数据,他的效果应该会更差。
Issue 5
2023.9.1
TODO : 之后把这些问题跟作者反馈一下,下一步考虑使用DDP,方便以后多卡训练。
Issues and PR
https://github.com/moein-shariatnia/Pix2Seq/issues/6
评论