
摘要
本篇主要介绍目标检测的一些基本概念,以及一个人脸检测的实例来加深印象,最后还谈了以下HOG特征的提取。
简单介绍(非常简单)
目标检测就是在负责在一幅图中检测出感兴趣的物体,一般采用滑动窗口来实现。但是实际应用中,检测效果依赖于光照、物体姿态、视角等影响。具体来说,目标检测需要考虑以下几个问题:
- 如何选择滑动窗口的大小,从而克服检测物体的尺度变化
- 如何建模图片的特征
- 如何找到物体对应的特征
- 如何克服不同摄影角度的问题(最原始的方法是训练多个视角的模型)

人脸检测
本次介绍基于adaboost的人脸检测模型,它广泛用在相机、手机摄影的人脸检测器。
boosting模型
首先介绍boosting模型,它是一种投票式的判别模型,相比于直接训练一个强分类模型,它的思想是训练多个弱分类器,取长补短达到强分类的效果。
训练过程如下,最终目的是训练一个分类器可以分辨红蓝数据点。刚开始所有数据点的权重为1。
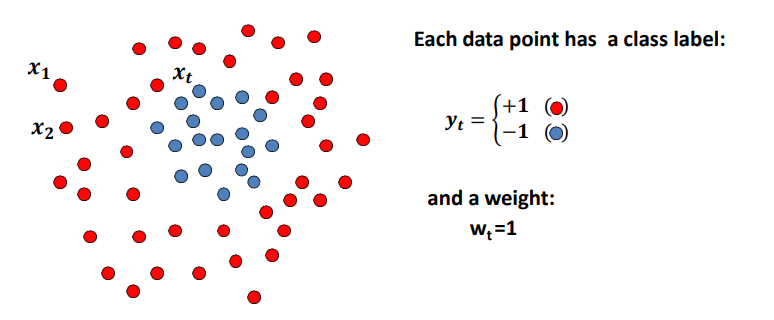
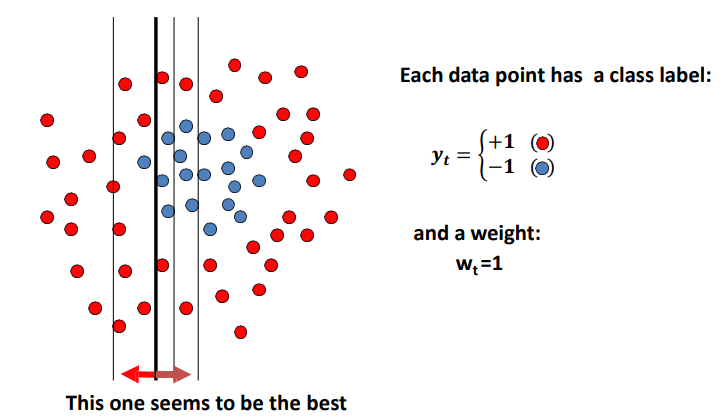
接下来训练多个弱分类器,例如线性分类器组。找到一个正确率最高的分类器,将其保留。
这里有个先验假设,我们总能找到一个正确率大于50%的分类器。原因是如果所有分类器的准确率都小于50%,那我们只需要选正确率最低的那个分类器,然后跟他反着预测即可。
我们选出来的分类器性能并不高,他会有一些分类错误的数据点,对于这些数据点,我们扩大它们的权重。(在代码中,我们选择缩小正确预测的数据点的权重,这里方便观察使用另外一种思路)
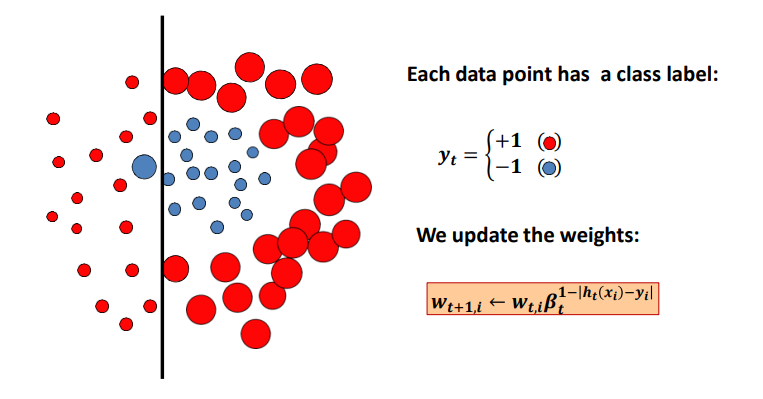
在新的权重比例下,我们再次训练多个线性分类器,得到一个表现最好的分类器,将其保留。因为我们扩大了第一个分类器分类错误的那些数据点的权重,所以第二个分类器会更加关注这些点的分类。通俗的来说,第二个分类器可以解决第一个分类器没有解决的错误。
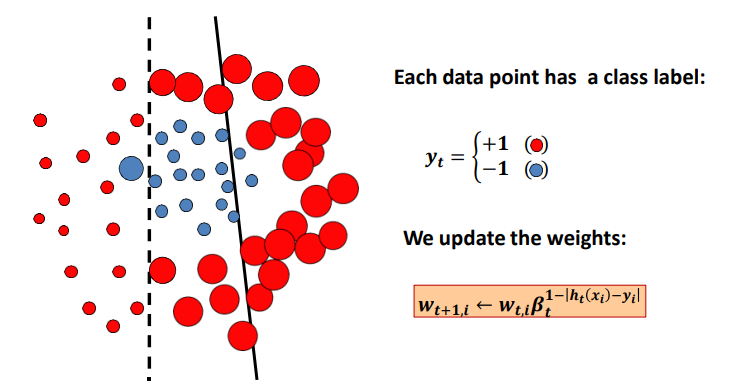
同理,我们扩大第二个分类器的分类错误点的权重,并训练第三个分类器。
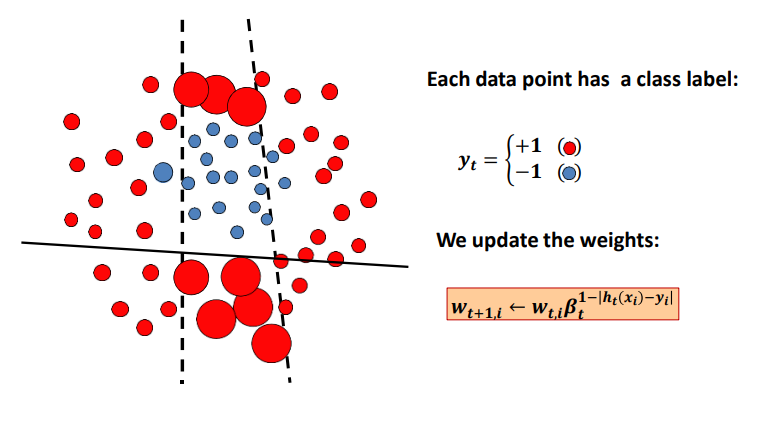
最后,我们通过多个弱分类器得到一个强分类器。这就是boosting的思想。
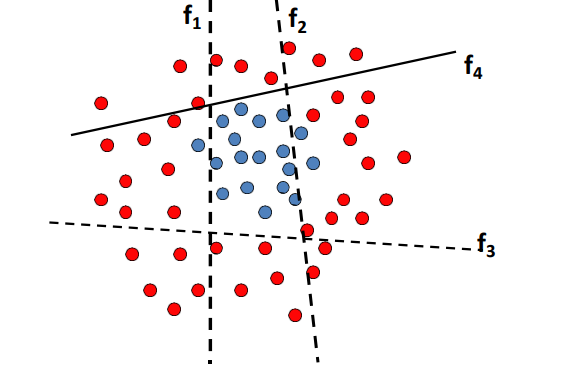
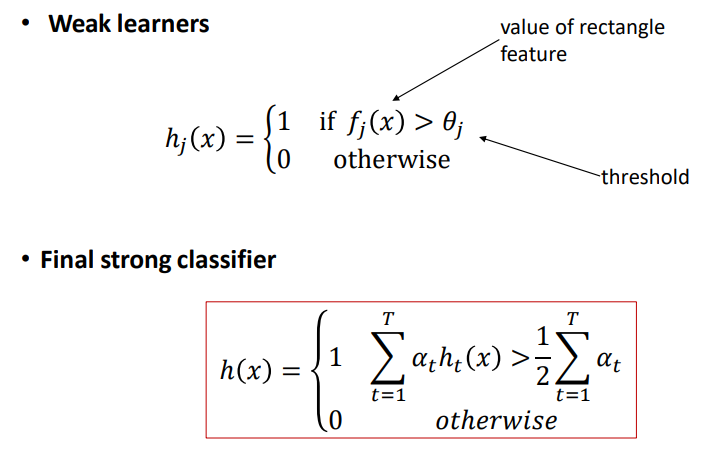
当对一个测试图像分类时,使用投票的方式进行预测,如果投票分数大于全局分数的半数,那么就将其分类为真。
人脸检测
回到人脸检测领域,我们选择的弱分类器非常简单,其实就是一个卷积模板。如下图所示,选择一个固定位置的卷积核,卷积核分为白色区域和黑色区域,卷积结果就是白色区域的像素值和与黑色区域的像素值和的差。这个也叫harr-like算子。

例如人脸鼻翼区域的卷积核,因为光照的原因,鼻翼下方的像素值普遍比鼻翼位置的像素值低,因此对于人脸来说,整个模板的值往往小于0,这就组成了一个Weak Classifier。

在实际运算中,为了解决运算成本,我们一般使用二维前缀和对图像的区域值计算进行加速。
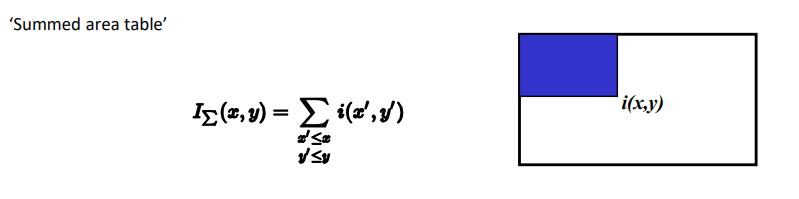
接下来的思路就和boosting一致,我们寻找多个模板构成多个弱分类器。然后参考boosting的训练机制得到一个人脸的强分类器。



不过对于一个准确率达到95%的强分类器,还是需要200个弱分类器参与运算。这效率还是不高,因为实际检测还需要通过滑动窗口确定人脸范围。
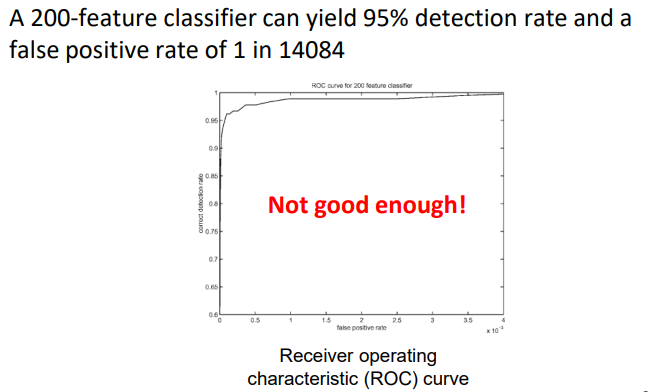
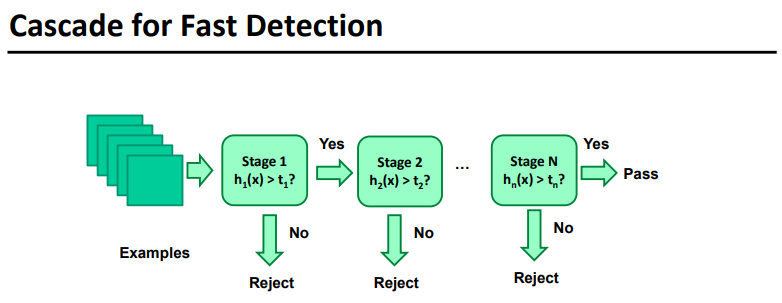
因此为了加快速率,采用强分类器的级联结构。具体来说,就是训练多个强分类器(每个强分类器里面都有多个弱分类器)。第一个强分类器的准确率不需要太高,比50%高一点就可以;第二个强分类器则处理第一个强分类器无法解决的错误;第三个分类器则解决第二个分类器无法解决的问题.....(这个思想也很像boosting)。最后通过多个强分类器检测的滑动窗口区域才认为存在人脸,否则直接pass。
这里为什么可以加快效率呢,因为强分类器不要求有很高的准确率,他只要保证可以让绝大部分正样本都通过,让部分负样本通过即可。通过多个强分类器的级联可以逐步过滤假阳样本。
假如第一个强分类器的准确率只需要50%,那么它大概只需要两个弱分类器就可以达到目的,这个远远低于95%准确率分类器的200个弱分类器。并且在检测过程中,大部分非人脸都会在这里被拒绝。所以可以提高检测效率。
以上级联特点也启示我们,对于越明显的特征检测器(比如刚刚提到的鼻翼位置的harr-like算子),放在越前面,将进一步提高检测效率。
说白了,强分类器的级联,其实可以理解成强分类器组的boosting
行人检测
行人检测主要介绍一个HOG特征。行人检测一般就是给定窗口,通过计算窗口中的HOG特征,利用SVM判断窗口中是否包含行人。

HOG的计算过程如下:
- 首先计算图像的梯度大小和方向图。
- 将图像分为若干个8x8大小的小单元,对于每个单元,统计其梯度直方图。统计直方图分成9份,即一个小单元对应一个9维向量。
- 四个小单元为一个block,那么一个block对应一个36维向量。对于每个block中的36维向量进行归一化,这一步可以降低光照等环境影响。
- 滑动窗口大小为一个blcok,步长为一个cell,所以对于一个8x16小单元的图像,最后可以得到$(8-1)*(16-1)=105$个block,那么这张图片的HOG特征长度就为$105*36=3780$。
评论