
摘要
图像分类是一个经典的视觉任务。无论是分类、识别、检测等任务,都容易受到视角变化、光照、尺度、变形、遮挡、背景、类内实体等因素的影响,所以寻找合适的图像特征表示是一个比较重要的任务。本篇主要介绍了词袋模型表示。
图像表示
图像表示有很多方法,例如之前提到的SIFT特征、纹理特征、HOG特征,甚至直接对图像分块、随机选择图像块也可以表示图像。

词袋模型
词袋模型也可以用来表示一张图像。词袋模型简单来说就是选取一些图像基元构成字典。对于一张图片,首先对其进行分割,统计这些图像块在字典中的统计直方图,根据统计直方图特征确定图片属于哪种类别。
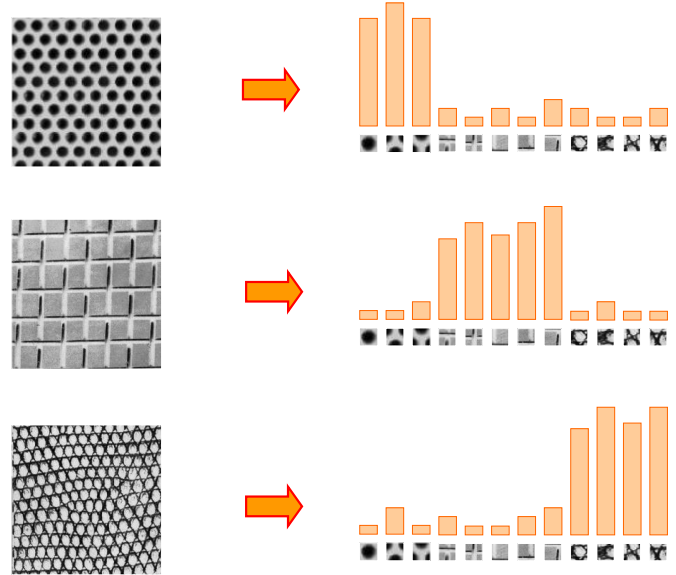
以下述三幅图为例,训练时,每幅图首先分别选出三张基元(如何选取见下文),因此得到了9个基元的词袋。

对于一张测试图像,同样提取图像块并和字典中的9个基元比较,统计其出现个数,根据统计特征进行分类。
词袋模型其实也广泛用在自然语言处理中,比如可以用它来做主题推断等等。

最后一部分是图像块(基元)的提取,这里有许多方法可以提取。例如对于一张图片,可以使用SIFT提取几个区域,并用SIFT描述符来描述。这样一张图片就表示成多个SIFT描述符形成的文档,而多张图片形成多个文档。
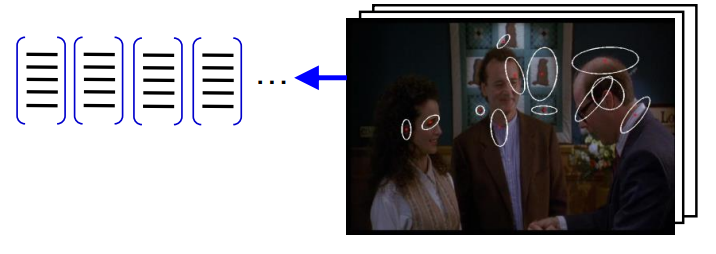
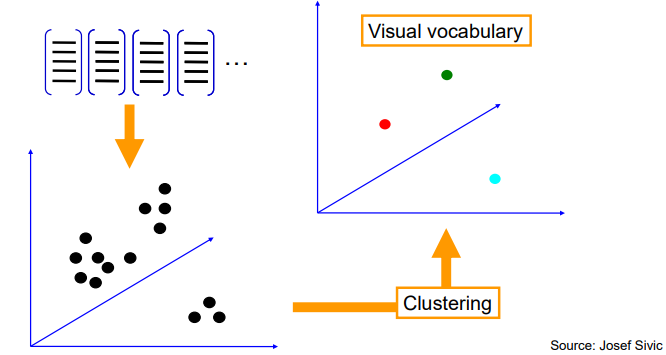
对于所有的SIFT描述符,可以做聚类操作,挑出具有代表性的几个描述符,将其作为词袋模型的单词。(这些单词会分割整个特征空间,对于任意一个SIFT描述符输入,都可以把它归类为某个单词,从而可以统计单词分布)根据这些单词,我们可以知道训练图片的单词分布。当来了一张新的图片,我们同样对其进行SIFT变换,得到文档及其单词分布,通过对比训练库中各类图片的单词分布,可以确定一个最相近的类,完成图像分类的目的。
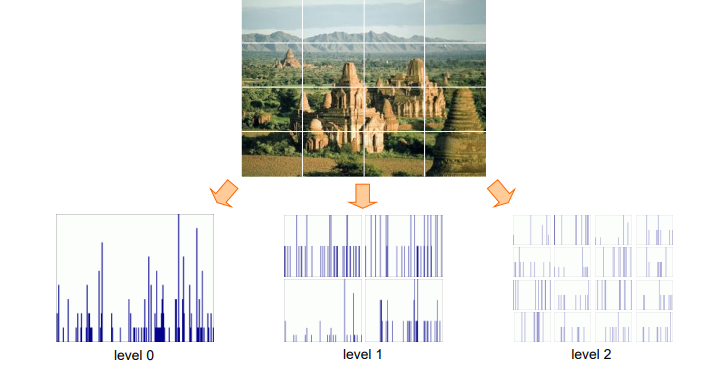
有时候,对于一整张图片使用词袋模型进行分类会存在问题。例如对于"我爱中国"和"爱我中国"两句话,它们四个字都相同,即单词分布一致,但是却表达了不同的意思。因此对于图像分类来说,我们可以使用空间金字塔表示,例如将图片分块,去比较小块图片的单词分布,从而提高分类的准确率。
生成式模型和判别式模型
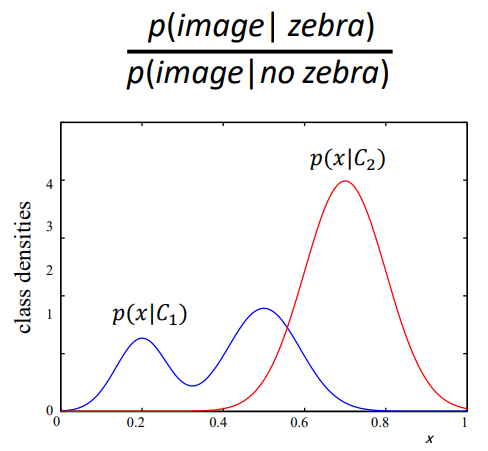
以判断一张图片中是否有斑马为例,可以通过贝叶斯公式求得一张照片中有斑马的概率。如下图所示,如果$posterior-ratio$大于1,可以认为这张图含有斑马。$posterior-ratio$通过贝叶斯公式可以表示为极大似然概率比$likelihood-ratio$与先验概率比$prior-ratio$的乘积。

对于判别式模型,它直接建模$posterior-ratio$,也就是求$P(x|y)$。
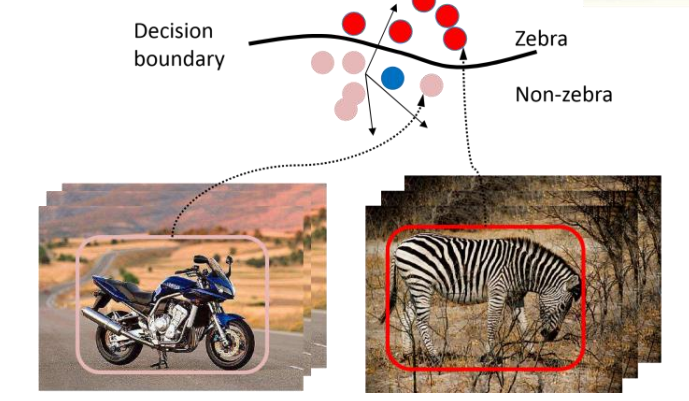
对于生成式模型,它建模极大似然比,再通过先验概率比得到最终识别结果。关于贝叶斯公式先验公式等内容的理解,可以参考这篇:理解贝叶斯定理(prior/likelihood/posterior/evidence) - 知乎 (zhihu.com)
目标识别
传统目标识别都是采用滑动窗口的搜索方法:不断移动窗口,直到窗口中检测到物体。

评论