
网络
原始网络结构
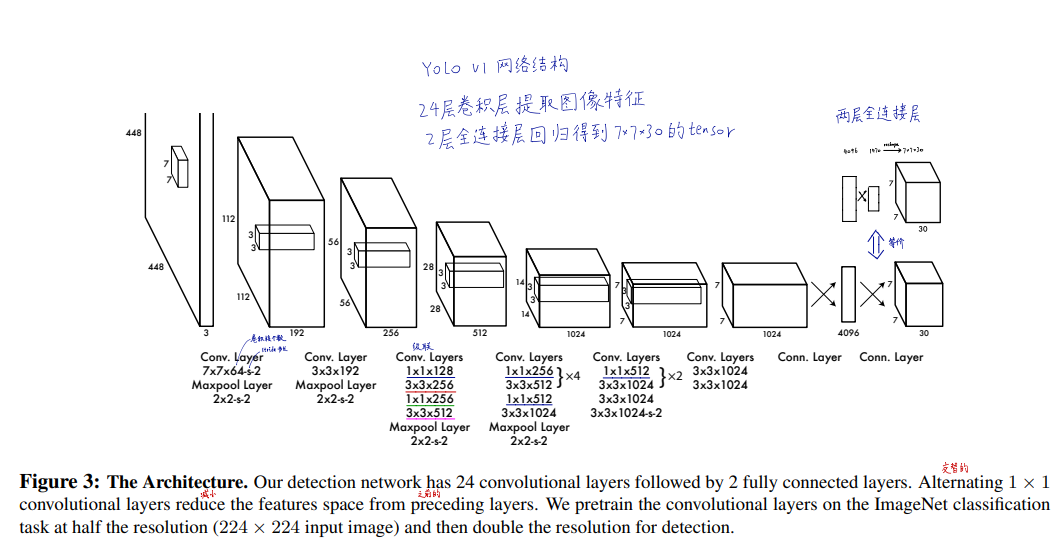
原始网络采用24层卷积层进行特征的抽取,这部分参数在ImageNet数据集上预训练来初始化。
Head部分采用两个全连接层实现,首先将7*7*1024的Tensor Flatten,并送入输出为4096的全连接层;再接一个输出为1470的全连接层。
最后将1470的向量reshape成7*7*30.
输出解析
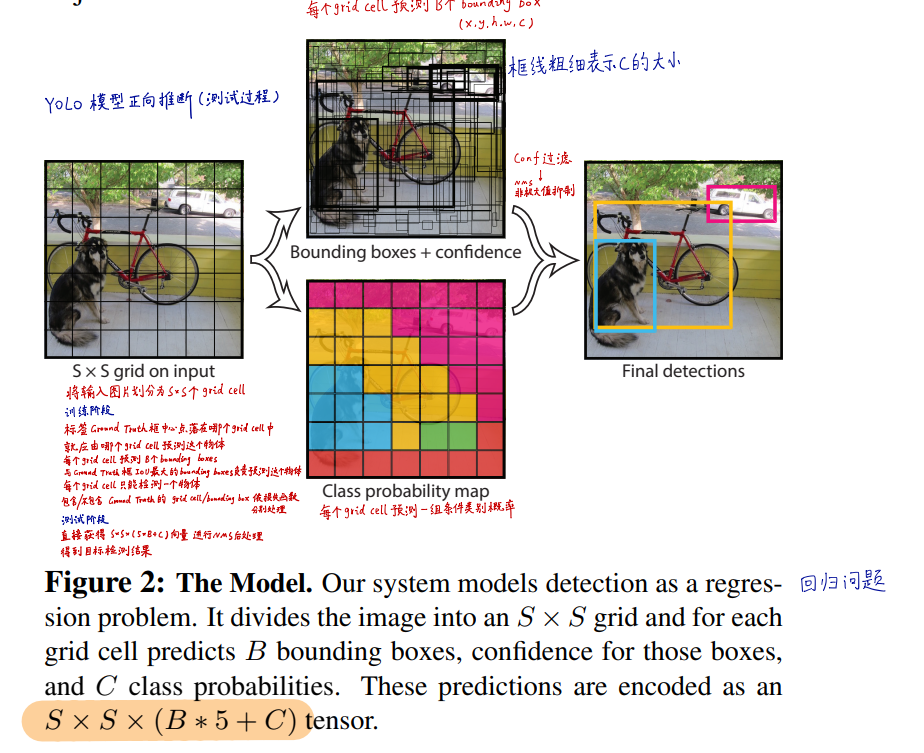
输出为SxSx(B*5+C)的tensor,其中SxS为grid cell的个数.
每个grid cell预测B个bounding box.每个bounding box有5个参数----中心点的坐标x和y,box的宽w和高h以及这个box包含物体的置信度confidence.
C是物体各个类别的概率(这里是20),这里的概率是条件概率,即在这个grid cell预测的某个bounding box预测物体时,各个类别的概率.
$$
P(class)=P(class|obj)*confidence
$$
损失函数
损失函数loss共分为五个部分:
- 第一部分是负责检测物体的bounding box的中心点定位误差
如何确认负责检测物体的box?
对于训练数据,确定gtbox的中心点,由这些中心点落在的grid cell负责预测该物体.而一个grid cell将预测B个box,将从这B个box中选出与gtbox IOU值最大的那个box作为预测框.
这个cell的其他B-1个box和那些不预测物体的cell产生的box一样,不计入xywh的损失,只计算他们的置信度误差(c=0)
- 第二部分是负责检测物体的bounding box的宽高定位误差
这里开根号是为了降低大框的loss权重,让网络更关注小框
- 三四部分都是置信度回归误差.计算预测值C与标签值的平方和误差
对于预测物体的bounding box,标签值这里取得是 C = Pr(obj)*IOU 其实对于预测物体的bouding box Pr(obj)=1 所以标签值就是IOU
对于其他的box,标签值就是0.
- 最后一部分是类别预测的误差.对于那些预测物体的grid cell 计算各个概率的平方和误差

loss中$\lambda$是各个损失的权值,比如应该更关注预测物体的box的误差 $\lambda_{coord}$而相对忽略不预测物体的box误差$\lambda_{noobj}$
网络改进
网络改进主要有以下几点:
①改进骨干网络
官方的YOLOv1的主干网络是参考了GoogLeNet设计的(没有inception结构),这里我们直接替换成ResNet18。关于ResNet18的网络结构,如下图所示
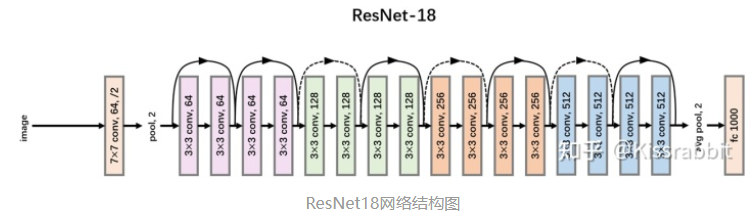
ResNet18网络更轻,使用了诸如residual connection、batch normalization等结构,性能上要更强于原先的backbone网络。这里,我们没必要换更大的ResNet网络,如ResNet50、101等,18即可满足要求。
②增加Neck
对于给定输入的416x416x3的图像,经过ResNet18网络处理后,最后会输出一张13x13x512的特征图。这里,我们添加一个Neck结构,对特征图中的信息进行更好地处理,这里,我们选择性价比极高的SPP
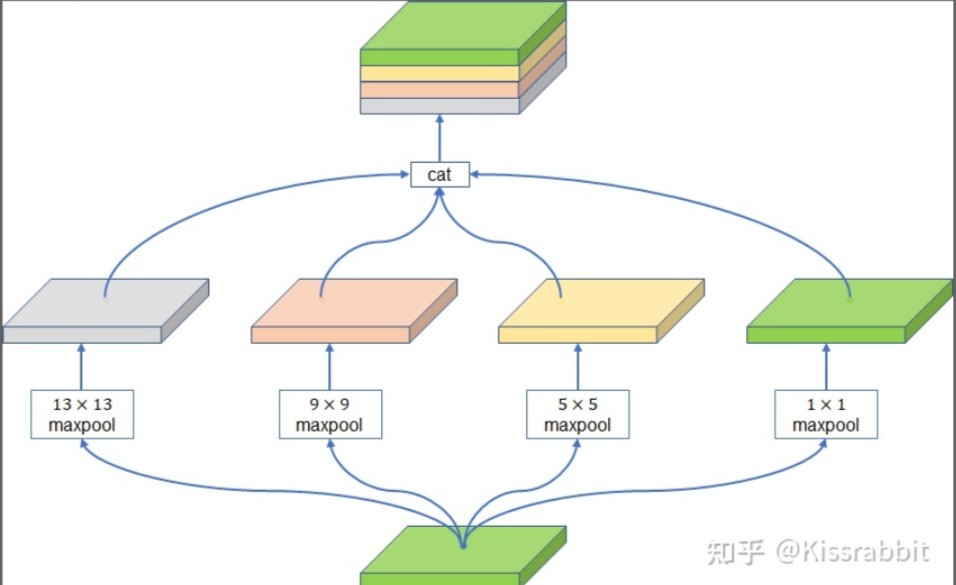
注意,SPP接受的输入特征图大小是13x13x512,经过四个maxpooling分支处理后,再汇合到一起,那么得到的是一个13x13x2048的特征图,这里,我们会再接一个1x1的卷积层(conv1x1+BN+LeakyReLU)将通道压缩一下,这个1x1的卷积层没有在图中体现出来。
最终Neck部分的输出同样是13x13x512的特征图。
③改进Detection head
官方的YOLOv1中这一部分使用了全连接层,也就是先将特征图flatten成一维向量,然后接全连接层得到4096维的一维向量。这里,我们抛掉flatten操作,而是在SPP输出的13x13x512的特征图上使用若干层卷积来处理,类似于RetinaNet那样。这里,我们使用非常简单的1x1卷积和3x3卷积重复堆叠的方式,如下图所示:
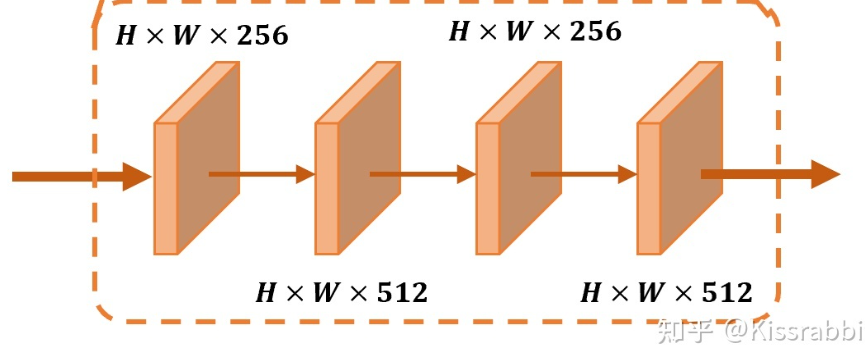
④改进prediction层
官方的YOLOv1最后使用全连接层来做预测,我们直接替换成当下主流的做法:用1x1卷积在特征图上去做预测,具体来说,head输出一个13x13x512大小的特征图,然后用1x1卷积(不接BN层,不接激活函数)去得到一个13x13x(1+C+4)的特征图,其中1对应YOLO中的objectness预测,C对应类别预测(PASCAL VOC上,C=20;COCO上,C=80),4则是bbox预测.
注意!!! 这里,每个grid处只预测一个bbox,而不是B个
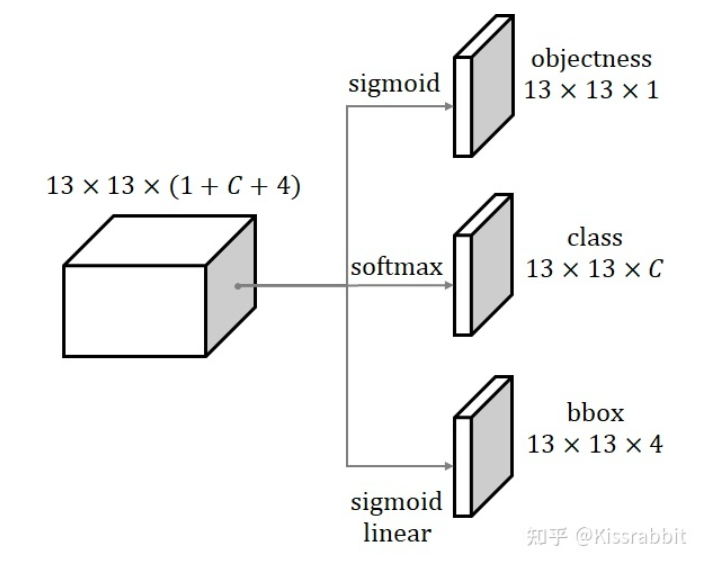
如上图所示,objectness分支我们使用sigmoid来输出,class分支则用softmax来输出,这三个预测,我们稍微展开讲一下。
objectness预测
不同于官方YOLOv1中的使用预测框和真实框之间的IoU作为优化目标,我们直接采用最简单的01标签即可。无需在训练过程中计算IoU。
class预测
不同于官方YOLOv1的线性输出,我们使用更为合理的softmax来输出。
bbox预测
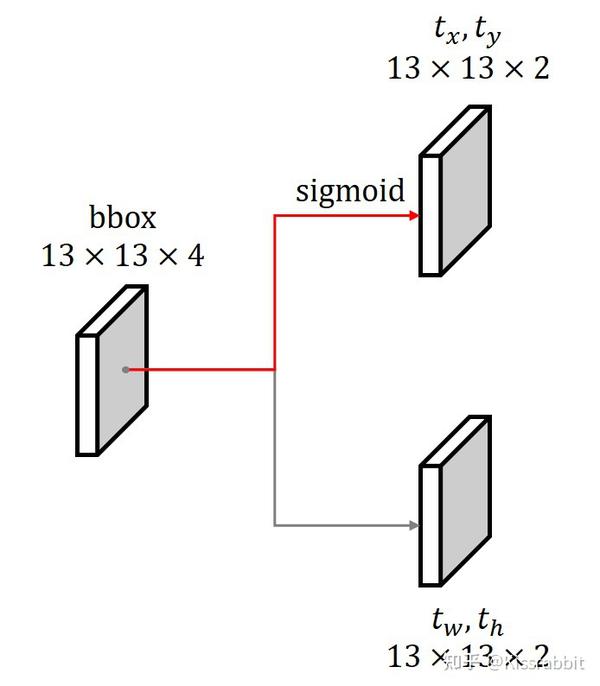
在YOLOv1中,bbox分支就是学习中心点的偏移量 $c_x,c_y$ 和归一化的边界框的宽高w,h ,但是不论是哪个量,YOLOv1均使用线性函数来输出,未加任何约束限制,很明显会有以下两点问题:
a) 由于偏移量$c_x,c_y$是介于01范围内的数,因此,其本身就是有上下界的,而线性输出并没有上下界,这就容易导致在学习的初期,网络可能预测的值非常大,导致bbox分支学习不稳定。因此,在YOLOv2的时候,作者就添加了sigmoid函数来将其映射到01范围内。
这里,我们也采用同样的办法,对于偏移量部分,我们使用sigmoid来输出,并将其符号改为 $t_x,t_y$
b) 边界框的宽高显然是个非负数,而线性输出不能保证这一点,输出一个负数,是没有意义的。一种解决办法是约束输出为非负,如用ReLU函数,但这种办法就会隐含一个约束条件,这并不利于优化,而且ReLU的0区间无法回传梯度;另一个办法就是使用exp-log方法,具体来说,就是将 w,h 用log函数来处理一下:
$tw=log(w)$
$t_h=log(h) $
网络去学习 $t_w,t_h$ ,由于这两个量的值域是实数全域,没有上下界,因此就无需担心约束条件对优化带来的影响。然后,网络对于预测的$t_w,t_h$ 使用exp函数即可得到
$w=exp(t_w) $
$h=exp(t_h) $
⑤损失函数

除此之外还使用了Batch norm (卷积+BN+激活函数)
最终网络
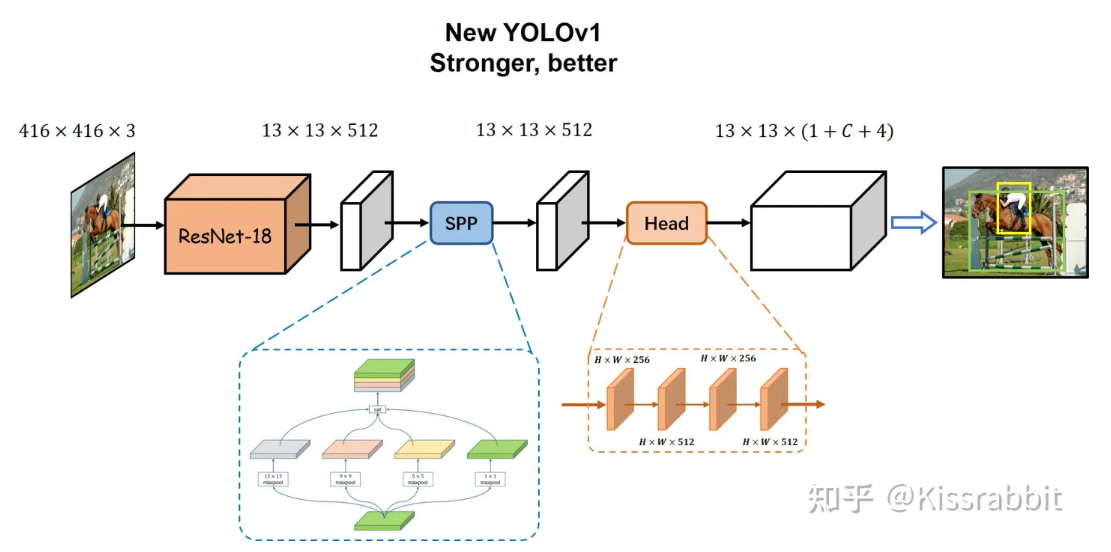
这里B=1,S=13
复现
项目结构
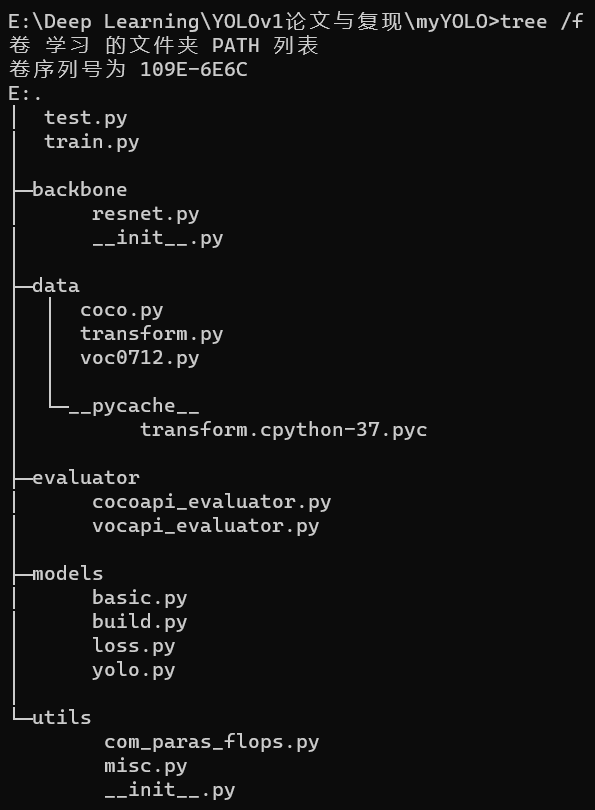
项目结构如下图,其中:
-
根目录下的test.py/train.py分别用于模型的测试与训练
-
backbone文件夹存放了骨干网络resnet的网络结构,并提供了预训练选项。网络结构见resnet论文精读
-
data文件夹存放了VOC数据集和COCO数据集的DataSet实现,其中tranform.py保存了一些比较常见的数据增广函数,如随机剪裁、随机翻转、HSV调节等
-
evaluator文件夹下主要是评估模型的evaluator,通过mAP衡量模型的accu
-
models文件夹存放了yolov1的网络实现,loss.py存放了损失函数的实现
-
utils文件夹存放了计算模型参数容量的工具
项目依赖
-
torch
-
torchvision
-
opencv-python
-
thop
-
scipy
-
matplotlib
-
numpy
-
pycocotools
开源代码
运行效果
训练:train.py
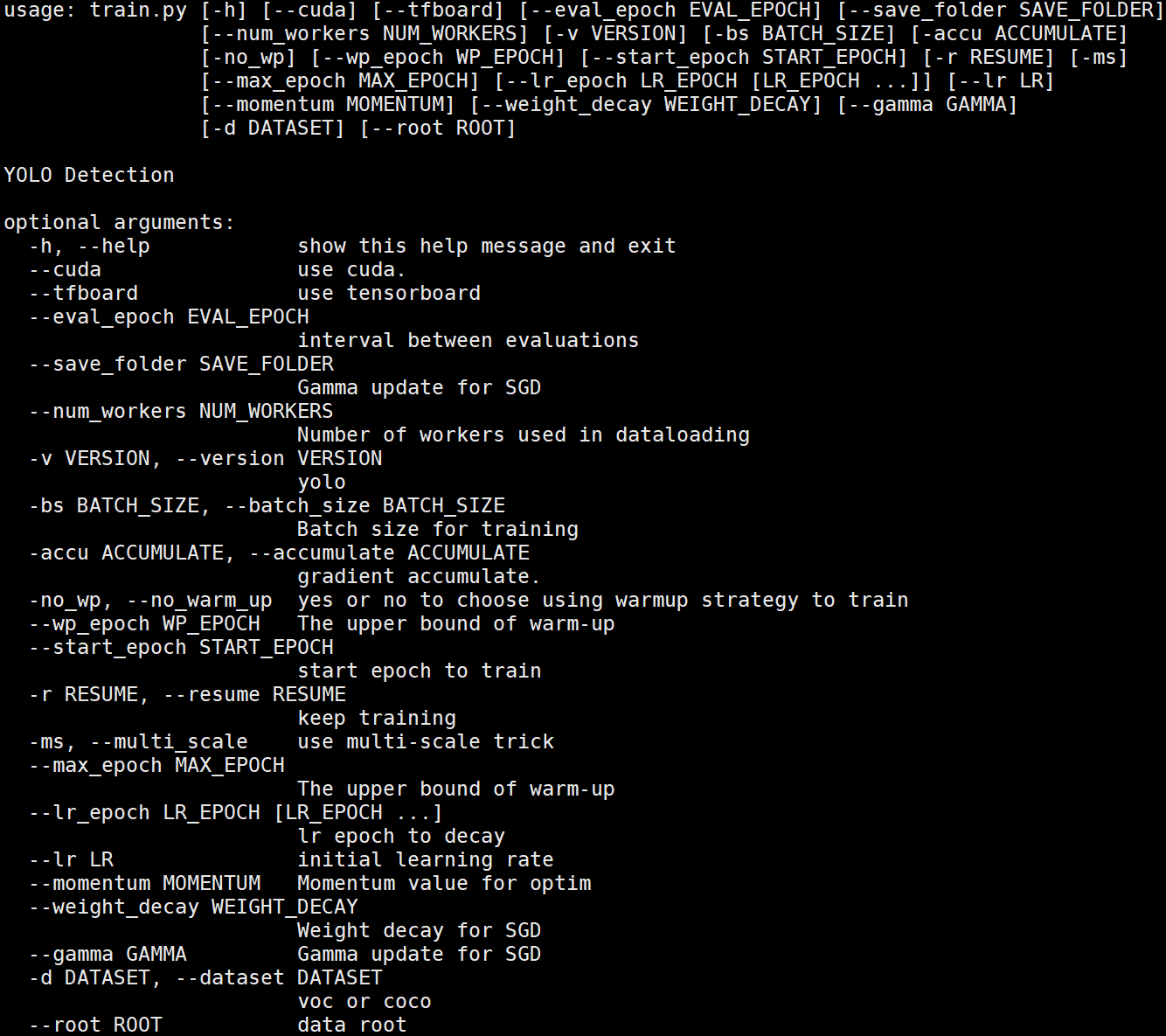
1.可选参数
2.训练过程

从头开始训练
python train.py --cuda -d voc -ms -bs 64 -accu 4 --lr 0.001 --max_epoch 150 --lr_epoch 90 120
keep-training(继续训练)
python train.py --cuda -d voc -ms -bs 64 -accu 4 --lr 0.001 --max_epoch 150 --lr_epoch 90 120 --start_epoch 120 -r ~/d2l/myYOLO/weights/voc/yolo/yolo_epoch_111_64.3.pth
测试:test.py
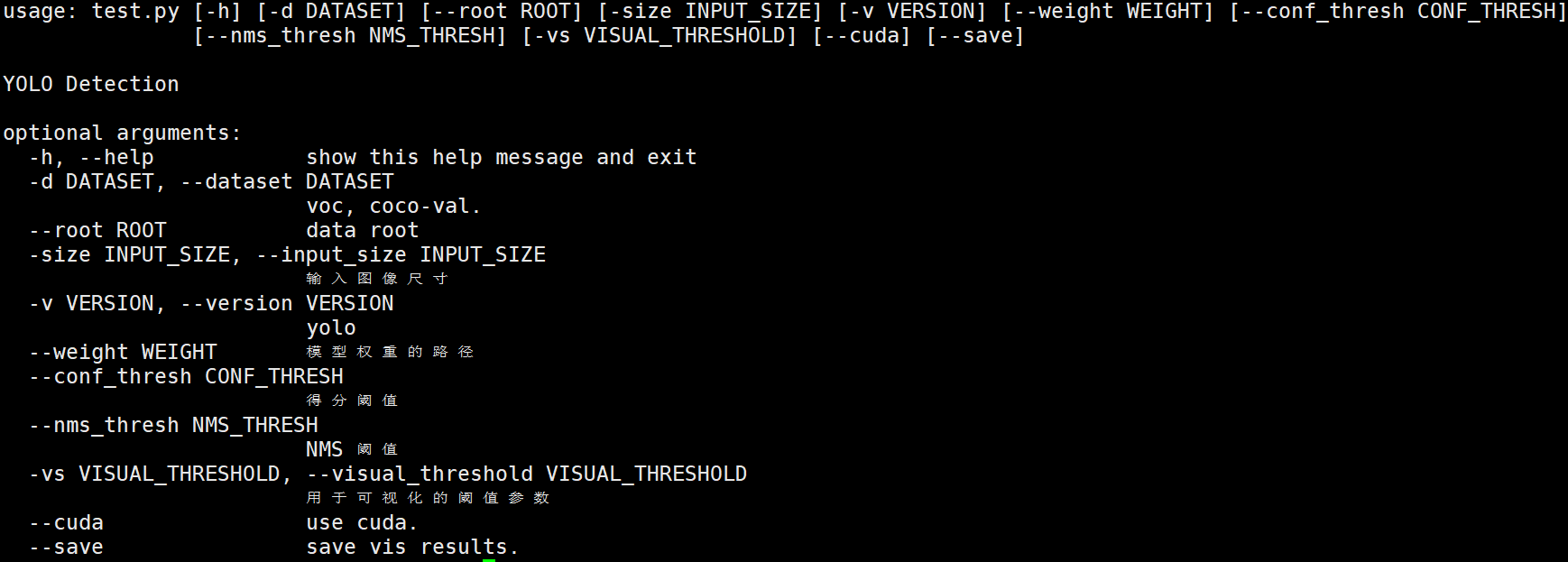
1.可选参数如下
2.预测效果


python test.py --cuda -d voc --weight weights/voc/yolo/yolo.pt
评估:eval.py
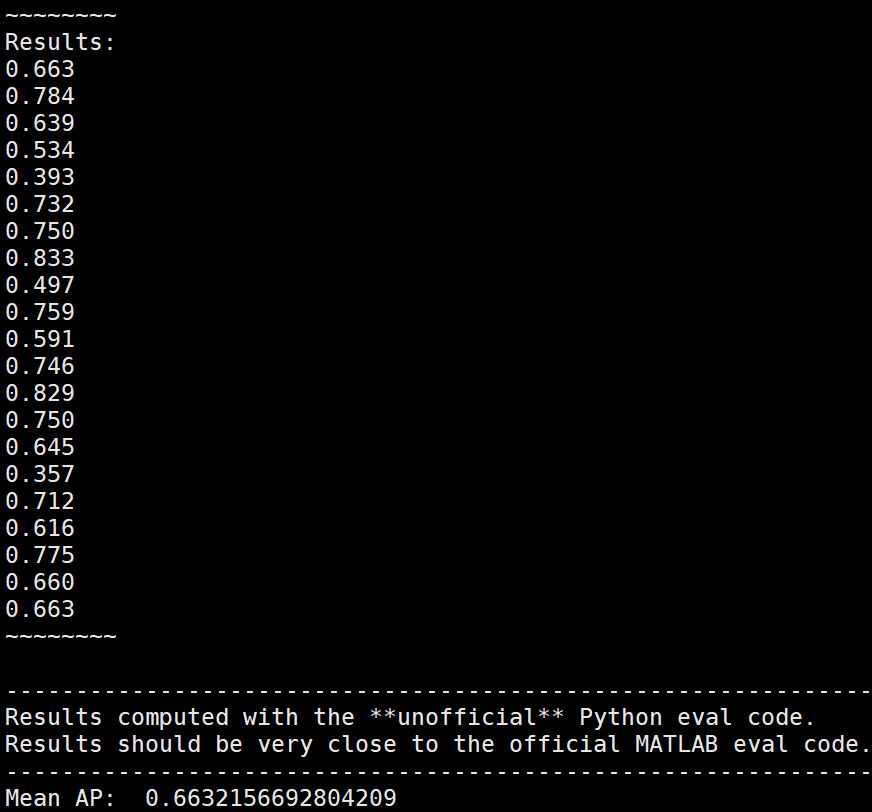
1.评估结果如下,在voc2007测试集上mAP=0.6632,大于原论文yolov1的mAP=0.634
python eval.py --cuda -d voc --weight 权重文件路径 -size 输入图像尺寸
评论