
摘要
本篇文章采用蜕变测试(metamorphic testing)的原理来寻找可能影响DeepFake检测模型鲁棒性的潜在因素,并缓解其中的Oracle问题。作者对MesoInception-4和TwoStreamNet两种检测模型进行了评估。通过蜕变测试发现化妆应用程序是一种对抗性攻击,可以欺骗deepfake检测器。实验结果表明,MesoInception-4和TwoStreamNet模型在输入数据被施加化妆扰动时,其性能下降高达30%。
Oracle问题:程序的执行结果不能预知的现象在测试理论中称为“Oracle问题”,即无法知道输入的预期结果,导致测试人员只能选择一些可以预知结果的特殊测试用例进行测试,而不能完整有效地进行测试。例如测试sin函数时,并不知道sin(153°)的预期结果。从而无法验证输入为153°时程序的正确性。
蜕变测试:蜕变测试是软件测试中的概念,是一种特殊的黑盒测试方法。蜕变测试依据被测软件的领域知识和软件的实现方法建立蜕变关系(Metamorphic Relation, MR),利用蜕变关系来生成新的测试用例,通过验证蜕变关系是否被保持来决定测试是否通过。同样以sin函数为例,虽然不知道sin(153°)的预期结果,但是根据数学知识可以得知sin(27°)=sin(153°),这是一种蜕变关系。我们利用程序验证这种关系,如果这个关系不成立可以说明源程序存在问题。
蜕变关系(Metamorphic Relation, MR) :指多次执行目标程序时,输入与输出之间期望遵循的关系。
实验设置
- 数据集:数据集选择的是FaceForensics++,其中包括四种Deepfake方式形成的图片:Deepfakes (DF),Face2face (F2F), Face Swap (FS),Neural Textures (NT)
- 受害者模型:MesoInception-4和TwoStreamNet
蜕变测试的应用
本文关于蜕变测试的具体应用如下图。具体来说,首先将数据集中的图片进行Metamorphic Transformation,得到两部分数据集(未扰动与扰动后)。将这两部分数据集分别输入检测器中,通过比较两次的检测结果来判断Metamorphic Transformation这种变化是否是影响模型鲁棒性的潜在因素。
个人感觉就是在对抗样本检测模型鲁棒性的基础上套了一个蜕变测试的壳子
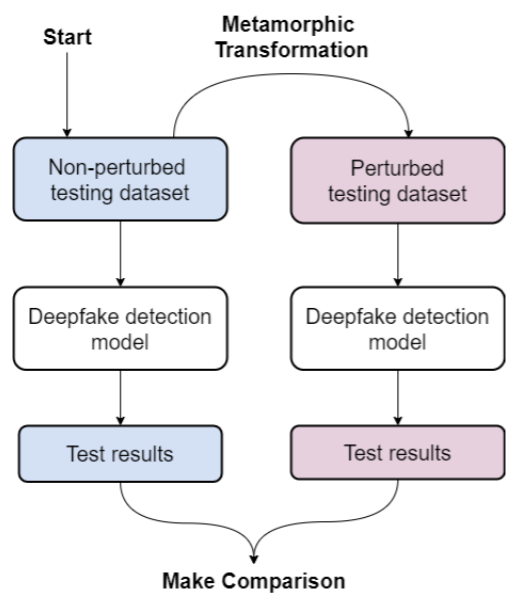
因为输入的扰动数据集是在原始数据集上通过扰动得到,如果模型具有较好的鲁棒性,那么两次测试结果应该一致。这就是蜕变测试中的蜕变关系(MR)。
关于如何衡量MR是否满足,即比较两次测试结果的方式,论文提到的方法是比较两次测试结果的Accuracy,Recall,Specificity。
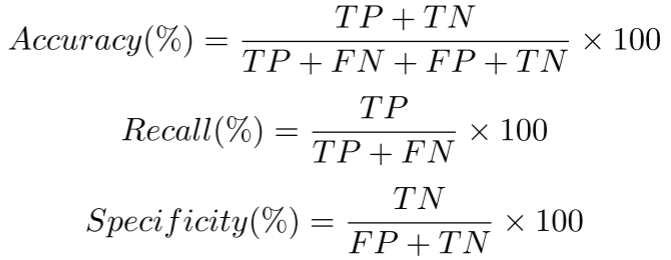
关于选择这三个指标的原因:选择Accuracy是因为它是用于DeepFake检测器的常见评估度量。它展示了模型的正确性和一致性。但是Accuracy受到准确性悖论(accuracy paradox)的影响,高准确性模型可能无法捕获分类任务中的基本信息。
因此作者还考虑了Recall和Specificity,因为FN和FP对于了解模型性能同样重要。高召回率表明模型在识别TP方面做得很好,而低召回率表明高FN。因此,Recall非常适合输出敏感的环境,例如预测deepfake或预测癌症(也就是说宁愿误判,也要找全)。同时,Specificity显示了模型在避免误报方面的表现。Specificity非常适合关注TP和FP的领域,例如推荐引擎(也就是说要减少误报)。
准确度悖论:面对非均衡数据集时,准确度这个评估指标会使模型严重偏向占比更多的类别,导致模型的预测功能失效。
对抗性扰动
本文提到的对抗性扰动(也是之前提到的Metamorphic Transformation)是给图像添加化妆效果。
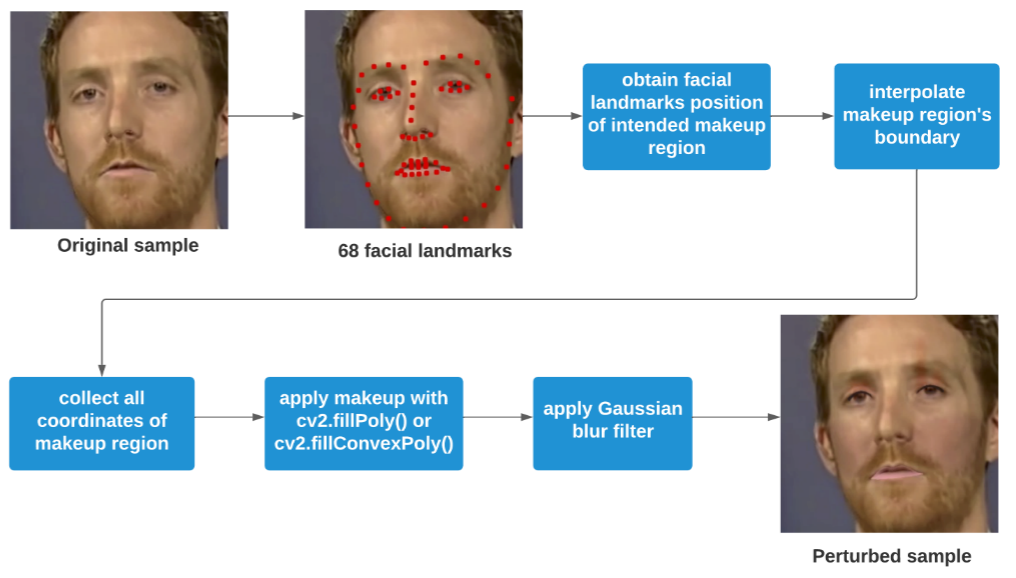
具体流程如下图,通过Dlib库识别面目的68个面部标志,并得到这些标志的坐标,调用OpenCV的方法在相应坐标绘制RGB色域的多边形,并通过高斯模糊滤镜使多边形与图像更好融合。
实验结果
文章总共展开了两个实验,主要区别在于数据集:一个是子数据集,另一个是完全数据集。参数差异如下图。
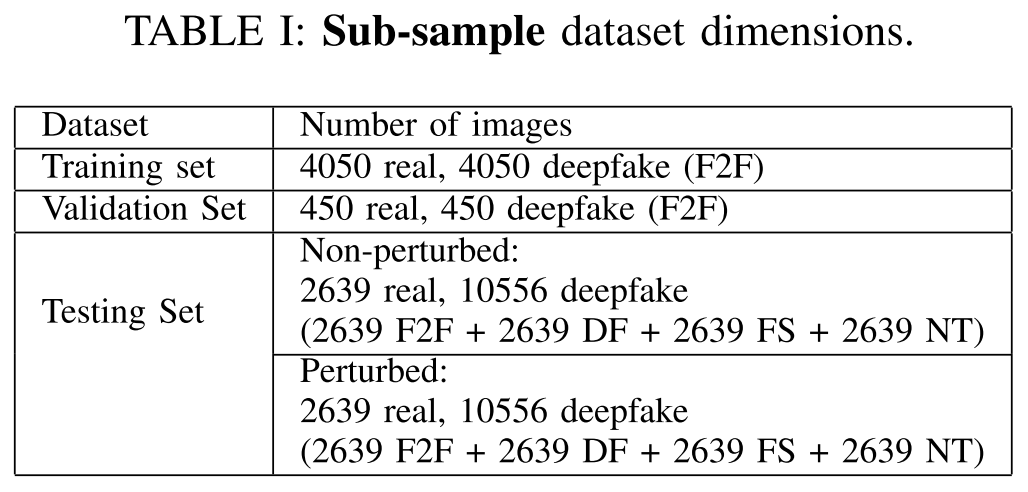
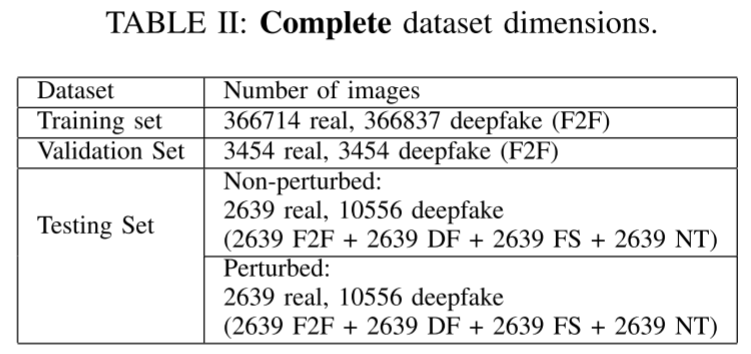
分出一个子数据集进行实验的原因是:MesoInception-4模型的主要优势之一是它能够在使用小数据集和最少的训练时间的情况下有效地检测deepfake。所以这里额外测试了小数据集下模型的鲁棒性表现。
1、子数据集上,模型的Accuracy表现
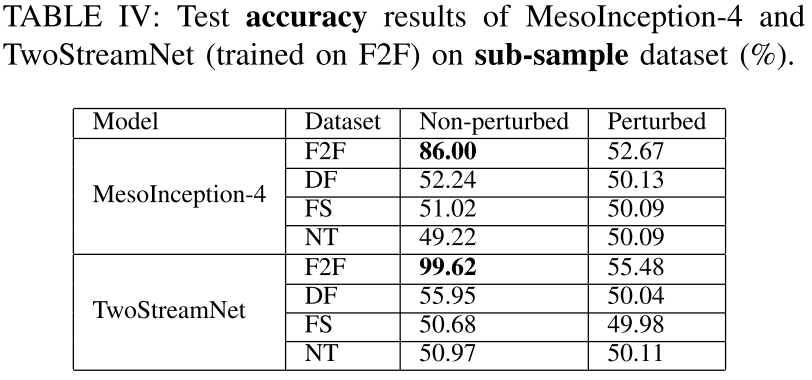
上表也表明Deepfake在跨数据集的表现很差,泛化能力不行
2、子数据集上,模型的recall和specificity表现
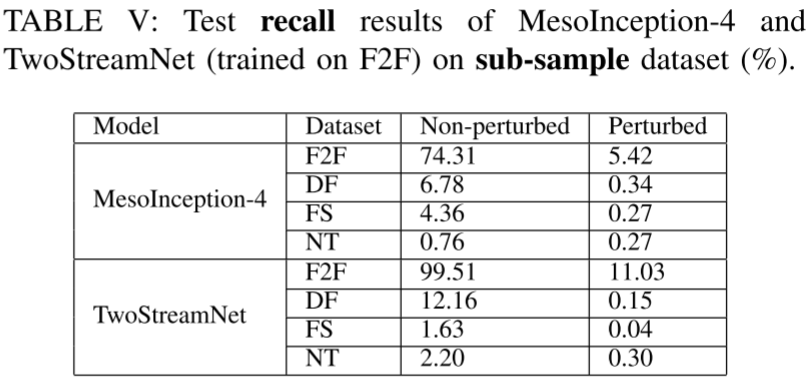
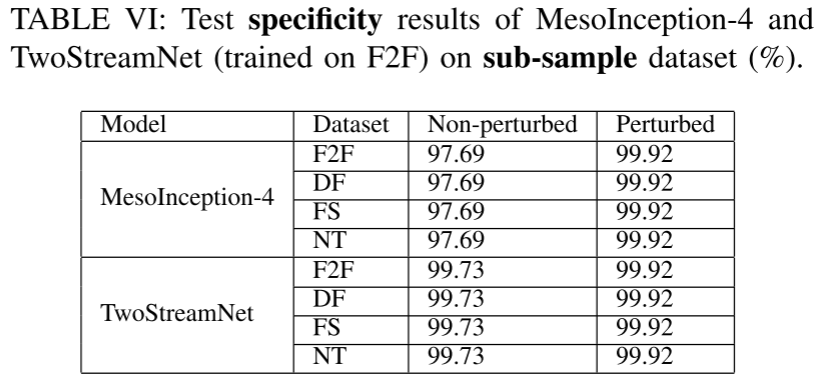
低召回率,高特异值表示模型将扰动后的图像同样认为是正常图像。说明化妆这种扰动确实对MesoInception-4和TwoStreamNet造成较大影响。
3、完整数据集上,TwoStreamNet的recall表现
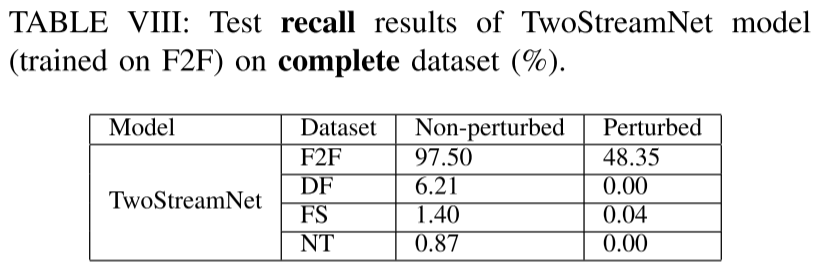
对于F2F这种方式得到的数据集,模型的recall值还保持在48.35%。说明训练数据的大小和质量的变化确实会影响深度学习模型的性能。(这是共识吧)
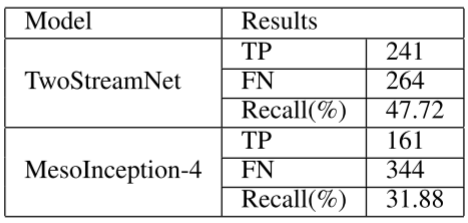
4、从原始数据集中挑选本来就化妆的DeepFake图像进行测试。发现同样会导致模型的低召回率。说明模型对于自然化妆或后处理化妆都不具备鲁棒性。
总结
文章采用蜕变测试(metamorphic testing)的原理来寻找可能影响DeepFake检测模型鲁棒性的潜在因素。并通过这种测试发现现有的部分DeepFake检测器对于化妆(无论是自然化妆或后续处理)不具备鲁棒性。
评论