
摘要
本文对现有Deepfake视频进行对抗性修改来绕过对应的检测器,并且进一步证明这种扰动对图像和视频压缩具有鲁棒性。
攻击原理
目前关于DeepFake视频的检测可以分为两大类。
第一种是通过手工选取的特征以及自然图片的统计/物理特征进行真假区分,然而视频合成方法通过修改它们的训练目标(例如通过Loss函数指导生成器模拟这些人工/统计特征),从而绕过这种检测。
之前解析的CVPR2023的一篇文章就是采用这种方式绕过检测器
第二种是基于深度神经网络进行检测。首先将视频分解成帧,随后提取帧中的人脸特征并判断。当然现在先进的DeepFake检测器并不是以整张图片帧作为输入,而是先通过面部追踪方法从原始帧中裁剪面部,再经过归一化等变换才输入网络。事实证明这种先验输入可以使检测性能更好。
既然这种视频检测器仍然是通过单帧检测DeepFake,那么如果对视频的每一帧都施加对抗性扰动,理论上就可以欺骗到检测器。
当然现在也有检测器引入时间序列检测deepfake视频,这种检测器使用CNN+RNN架构或3-D CNN模型对帧序列进行处理。文章对这类检测器的代表3-D EfficientNet也进行了攻击。
实验设置
-
受害者模型:逐帧分析的检测器有XceptionNet和MesoNet,基于时间序列的检测器有3-D EfficientNet
-
攻击手段:使用基于梯度符号的方法进行扰动,考虑到视频需要处理的帧数较多,使用$L_\infty$对扰动进行限制。
-
攻击流程:对于任何给定的帧,首先提取脸部区域,并为裁剪后的脸制作一个对抗样本,然后将其放回原始帧中面部裁剪的边界框中。
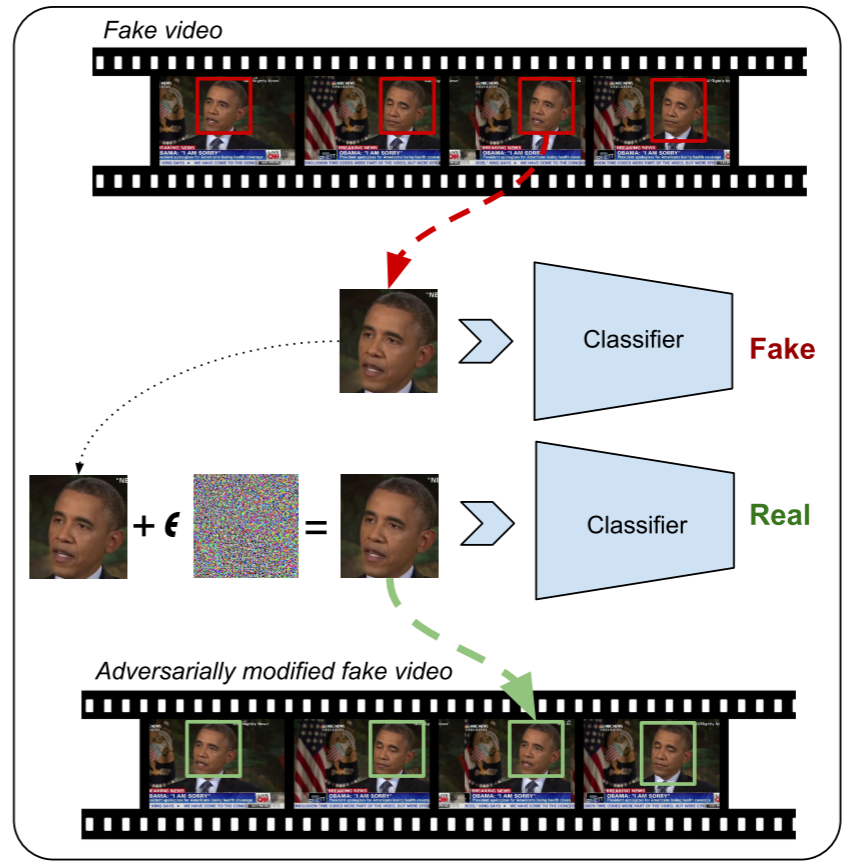
攻击类别
白盒攻击
使用基于梯度符号下降的攻击方法(如FGSM/PGD),不过损失函数采用了C&W Attack中的其中一种,即
$$
loss(x')=max(Z(x')_{Fake}-Z(x')_{Real},0)
$$
其中$Z(.)$表示模型softmax前一层的输出。那么对抗样本的迭代如下
$$
x_i = x_{i-1} - clip_{\epsilon}(\alpha·sign(\nabla loss(x_{i-1})))
$$
鲁棒的白盒攻击
通常上传到社交网络和其他媒体的视频会被压缩。已知的一些标准操作(如压缩、调整大小)都可能去除图像中的对抗性扰动。为了确保对抗性视频即使在压缩后仍然有效,引入鲁棒的白盒攻击。
首先引入$T$变化操作,这个即刚刚提到的压缩,大小调整等。
那么对于输入x,我们的最终目标是生成
$$
x_{a d v}=a r y m a x_{x}\mathbb{E}_{t\sim T}[F(t(x))_{y}]\operatorname{s.t.}||x-x_{0}||_{\infty}\lt \epsilon
$$
其中$F(t(x))_{y}$是指模型将$t(x)$判别成目标类别$y$,即Targeted Attack。
Loss函数如下,其实跟白盒攻击对比只多了一个t变换。
$$
l o s s(x)=\mathbb{E}_{t{\mathord{\sim}}T}\left[m a x(Z(t(x))_{F a k e}-Z(t(x))_{R e a l.0}\right]
$$
这里涉及到期望,根据大数定理可以转换成
$$
l o s s(x)=\frac{1}{n}\sum_{t_{i}\sim T}[m a x(Z(t_{i}(x))_{F a k e}-Z(t_{i}(x))_{R e a l},0)]
$$
关于T变化,文章提到了以下几种操作
-
高斯模糊。$t(x)=k*x$,其中k是高斯核,*是卷积算符;
-
添加高斯噪声。$t(x)=x+\Theta$,其中$\Theta \sim N(0,\sigma)$;
-
大小转换。在图像的四个边填充0值。$t(x)=x'$且$x^{\prime}[i,j,c]=x[i+t_{x},j+t_{y},c]$
-
下采样与上采样。首先将图像以因子r下采样,再通过插值上采样回原大小。
黑盒攻击
黑盒攻击采用基于查询的方法,并通过NES进行梯度估计。略去NES梯度估计的理论过程,估计梯度可以表示为
$$
\nabla \mathbb E[F(\theta)]\approx\frac{1}{\sigma n}\sum_{i=1}^{n}\delta_{i}F(\theta+\sigma\delta_{i})_{y}
$$
其中$\theta=x+\sigma\delta$且$\delta \sim N(0,I)$,关于NES梯度估计的算法流程见算法1。

估计梯度后,采用基于梯度符号的攻击进行优化。
$$
x_i = x_{i-1} + clip_{\epsilon}(\alpha·sign(\nabla F(x_{i-1})_y))
$$
注意这里是加号,与白盒攻击不同。白盒攻击因为引入了CW的Loss,所以是最小化Loss函数。
鲁棒的黑盒攻击
鲁棒的黑盒攻击同样使用NES进行梯度估计,相比于黑盒攻击同样只多了一个T变换。梯度估计如下
$$
\nabla \mathbb E[F(\theta)]\approx\frac{1}{\sigma n}\sum_{i=1,t_i \sim T}^{n}\delta_{i}F(t_i(\theta+\sigma\delta_{i}))_{y}
$$
优化过程与黑盒攻击一致。
实验结果
评估指标
- 攻击成功率SR:对抗视频中被分类成真实图片的帧的百分比。进一步地,SR-U表示以Raw形式保存的视频的攻击成功率(Raw表示视频未经过压缩),SR-C表示已MJPEG形式保存的视频的攻击成功率。
- 准确率Accuracy:视频中被检测器分类为假的帧的百分比。ACC-C表示压缩视频上检测器的准确率。
- 平均失真Mean distortion:通过$L \infty$范数衡量对抗帧和原始帧之间的失真情况
数据集
- FaceForensics++ HQ Dataset:其中包括DF、F2F、FS、NT四种DeepFake类型的视频
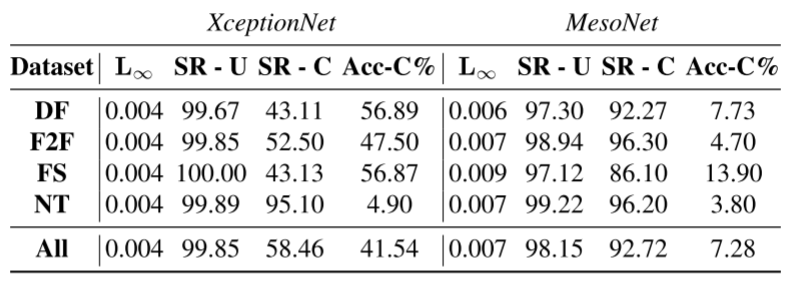
1、对于XceptionNet和MesoNet,它们在原始数据集上的准确率表现

2、白盒攻击的攻击成功率。
3、鲁棒白盒攻击的设置与结果

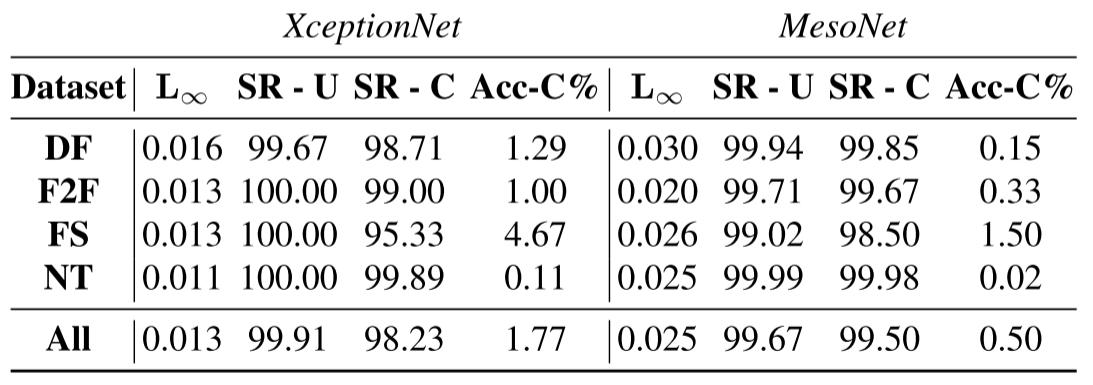
主要提升在于SR-C,即对于视频压缩的鲁棒性。
4、黑盒攻击与鲁棒黑盒攻击的攻击成功率。
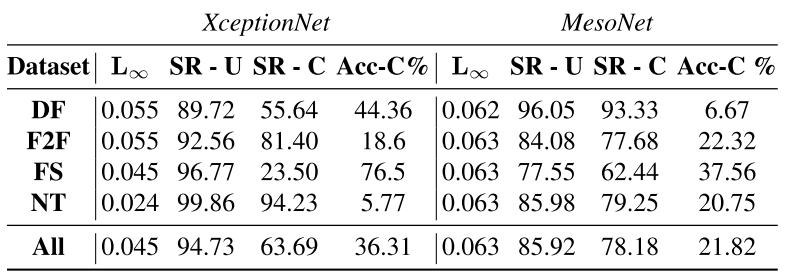
黑盒攻击中,对于每一帧图像,对受害者模型的平均查询次数为985.
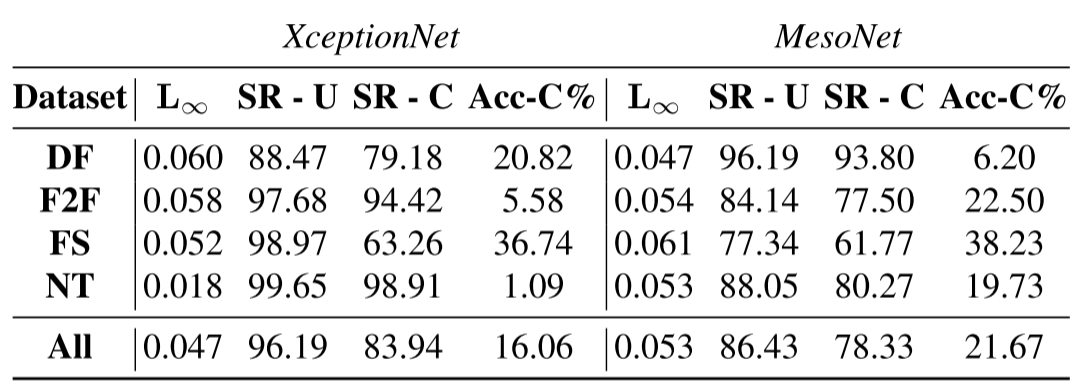
鲁棒黑盒攻击中,对于每一帧图像,对受害者模型的平均查询次数为2153.
总结
个人认为文章的亮点有两处:首先是针对deepfake视频施加扰动从而欺骗分类器;其次在白/黑盒攻击场景下考虑了对抗性攻击的鲁棒性,即考虑到物理场景下视频很可能被压缩的情况,针对这种情况对输入进行变化后再执行对抗攻击。
评论