
摘要
本篇文章做了以下三项工作:
- 探究高斯噪声扰动对面部提取器的影响
- 发现可以通过使用新方法生成DeepFakes来绕过现有检测器
- 发现可以利用数据毒化、后门攻击来绕过DeepFake分类器
第二点现在基本算是共识,所以接下来主要谈1、3两点。
实验设置
- 数据集来源:FaceForensics++和DFDC
- 受害模型:对于选择开源的面部提取器Dlib,deepfake检测器选择XceptionNet
面部提取器攻击
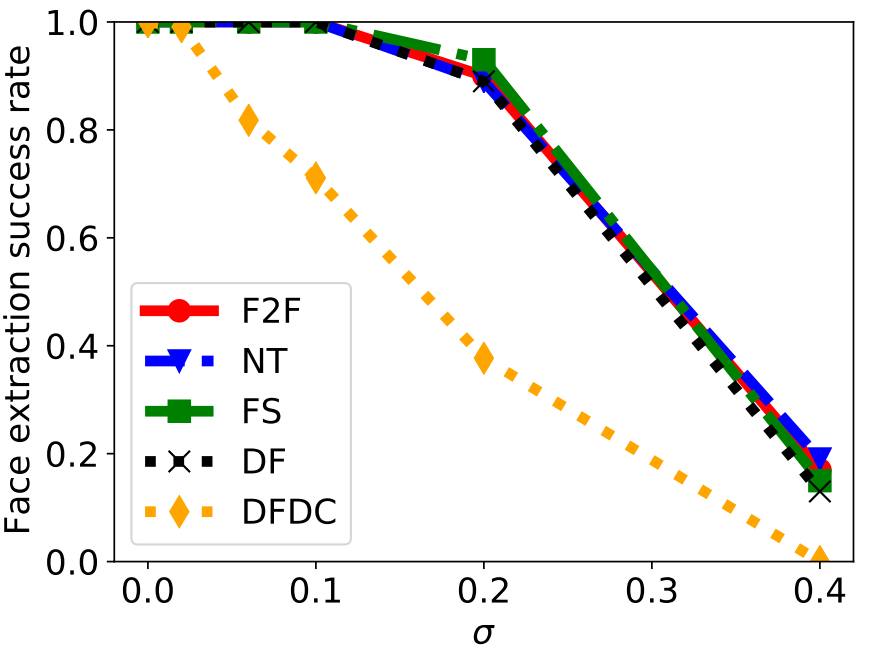
攻击方式:向图像帧中每个通道的每个像素都施加均值为0,标准差为$\sigma$的随机高斯噪声。然后通过Dlib提取器提取人脸。如果Dlib输出结果为NULL,说明攻击成功。
这个设置其实对Dlib有利,因为Dlib有可能受噪声影响从而输出不正确的图像
当随着$\sigma$的增加,Dlib的性能逐渐下降,拐点在$\sigma = 0.2$的位置。对于DFDC数据集,Dlib性能下降相比其他数据集快得多。性能下降更快的原因作者认为是FaceForensics++数据集的人脸可能更好提取。
数据毒化攻击
数据毒化攻击主要是对模型训练集进行修改,从而改变模型的性能表现。文章共提到两种数据毒化攻击:标签反转攻击与后门攻击。
标签反转攻击:顾名思义,就是修改训练样本的标签值。real->fake与fake->real。结果如下图。
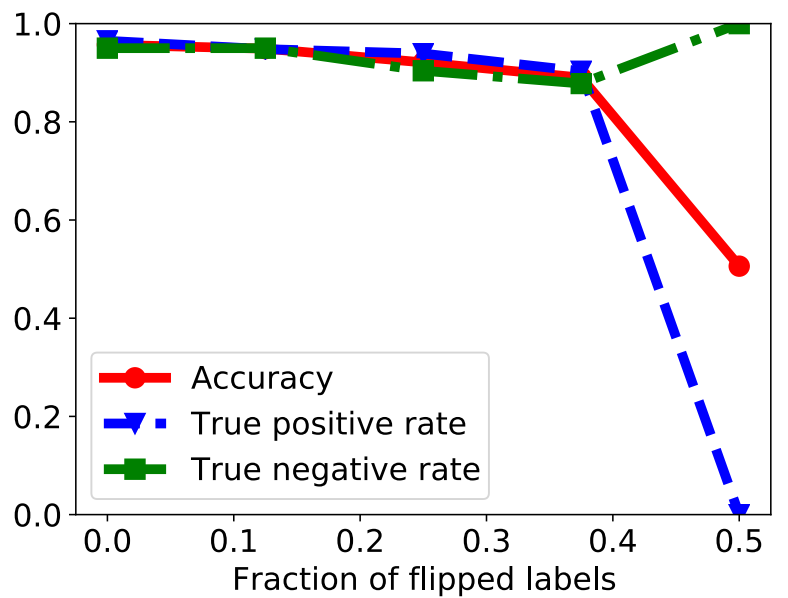
可以发现当翻转标签比例达到37.5%时,人脸分类器的准确度也仅仅下降了7%。这可能是因为训练数据集的大量冗余,只要具有正确标签的训练人脸图像比具有翻转标签的训练人脸图像足够多,就可以学习准确的人脸分类器。
当翻转比例达到50%时,分类器基本将所有输入都认为是真实图像。
后门攻击:使用棋盘网格作为触发器,嵌入到deepfake样本中,并将标签改为real。具体来说,棋盘格嵌入在图像右下角,大小占比为图像大小的0.1%,具体如下图所示。

攻击效果见下图。当毒化比例在5%时,分类器就已经将所有测试图像都认为是真实的。

讨论
本节作者讨论了几种针对对抗样本的防御以及它们各自的缺陷。
对抗训练与随机平滑可以实现对对抗样本的鲁棒性;集成模型则可以抵御后门攻击。不过随机平滑与集成模型目前来看本身准确率就不高,并且当对抗样本扰动足够大时,仍然可以逃避检测。
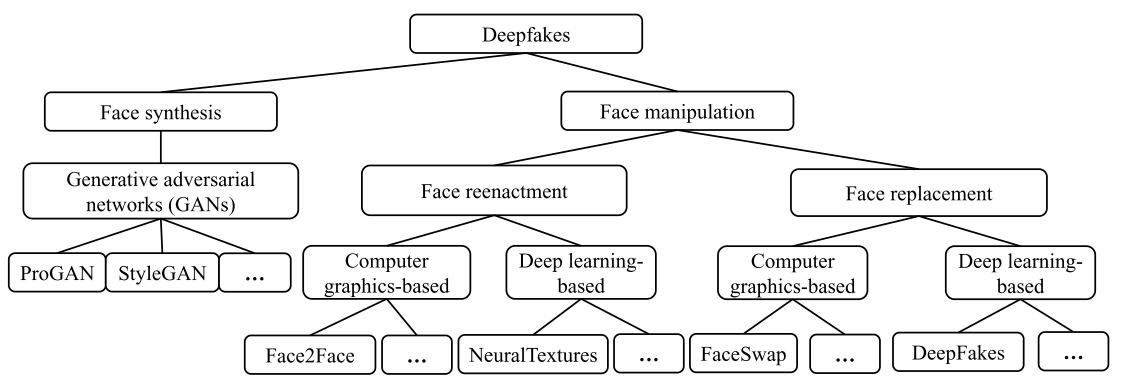
下图则是对DeepFake技术的一个分类树,个人觉得有一定参考价值就贴在这了。
总结
这篇文章个人认为亮点主要在于提出对面部提取器的攻击(虽然实验部分好像太随便了)。数据毒化也是一个思路,但是真实攻击场景下这种攻击的可行性应该不是很高。
评论