
Abstract
本文提出了一个开源的可拓展的知识抽取工具包——DeepKE,支持多场景(少资源、文档级别、多模态)下的知识数据库填充。
Introduction
KBP的提出是为了从文本语料库中抽取知识来补充知识库(KBs)中缺失的元素,即对知识图谱进行补充。
DeepKE支持标准监督设置和三种复杂场景下的知识抽取任务(命名实体识别、关系抽取和属性提取)。
Core Functions
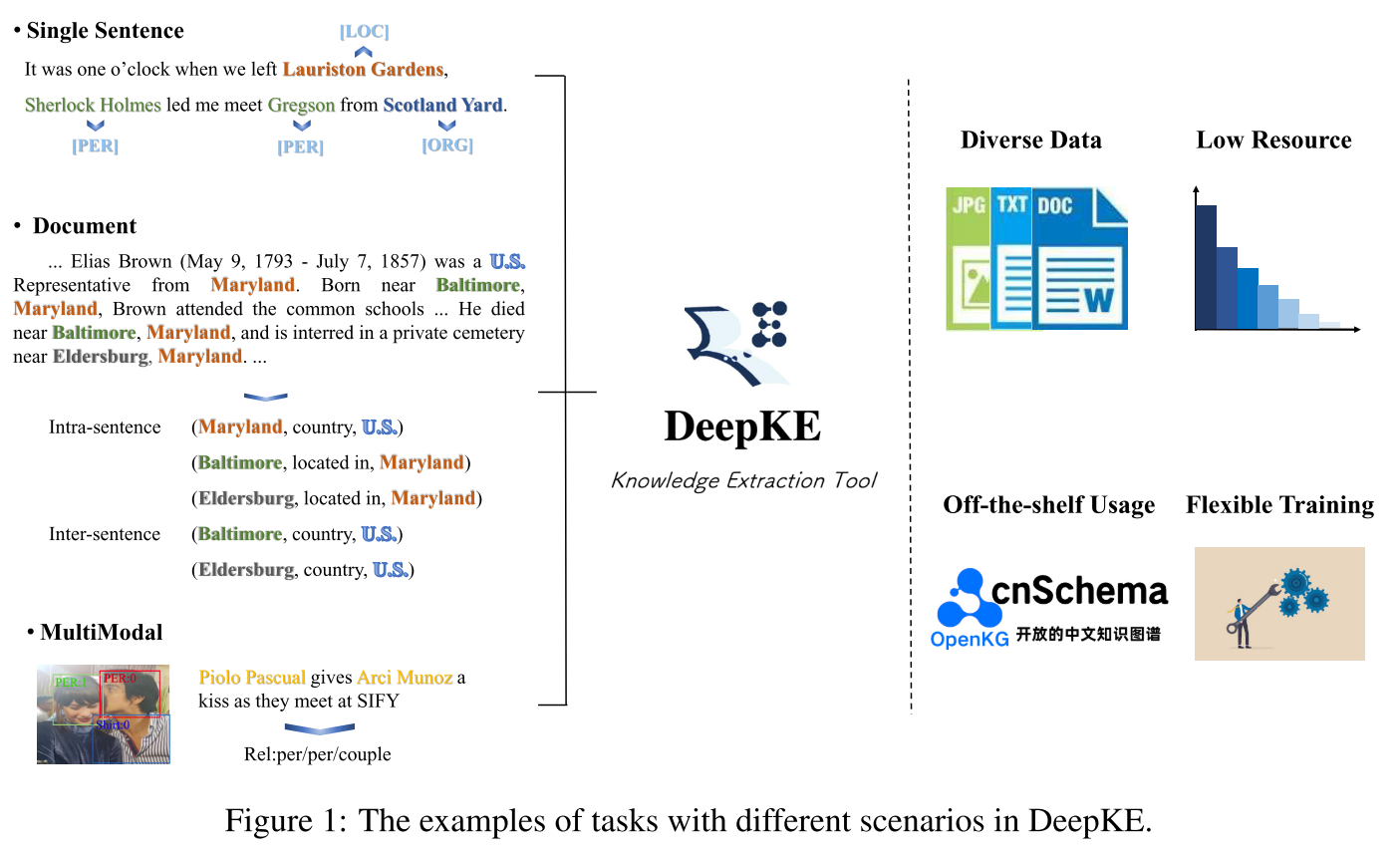
这一节简要介绍了一下三种知识抽取任务的概念和效果。略。
Toolkit Design and Implementation
DeepKE的三大特性:
- 统一框架,在数据、模型和核心组件方面,不同的任务对象使用相同的框架。
- 灵活使用,提供自动超参数调整等工具,提高工作效率
- 现成模型,提供预训练的语言模型。
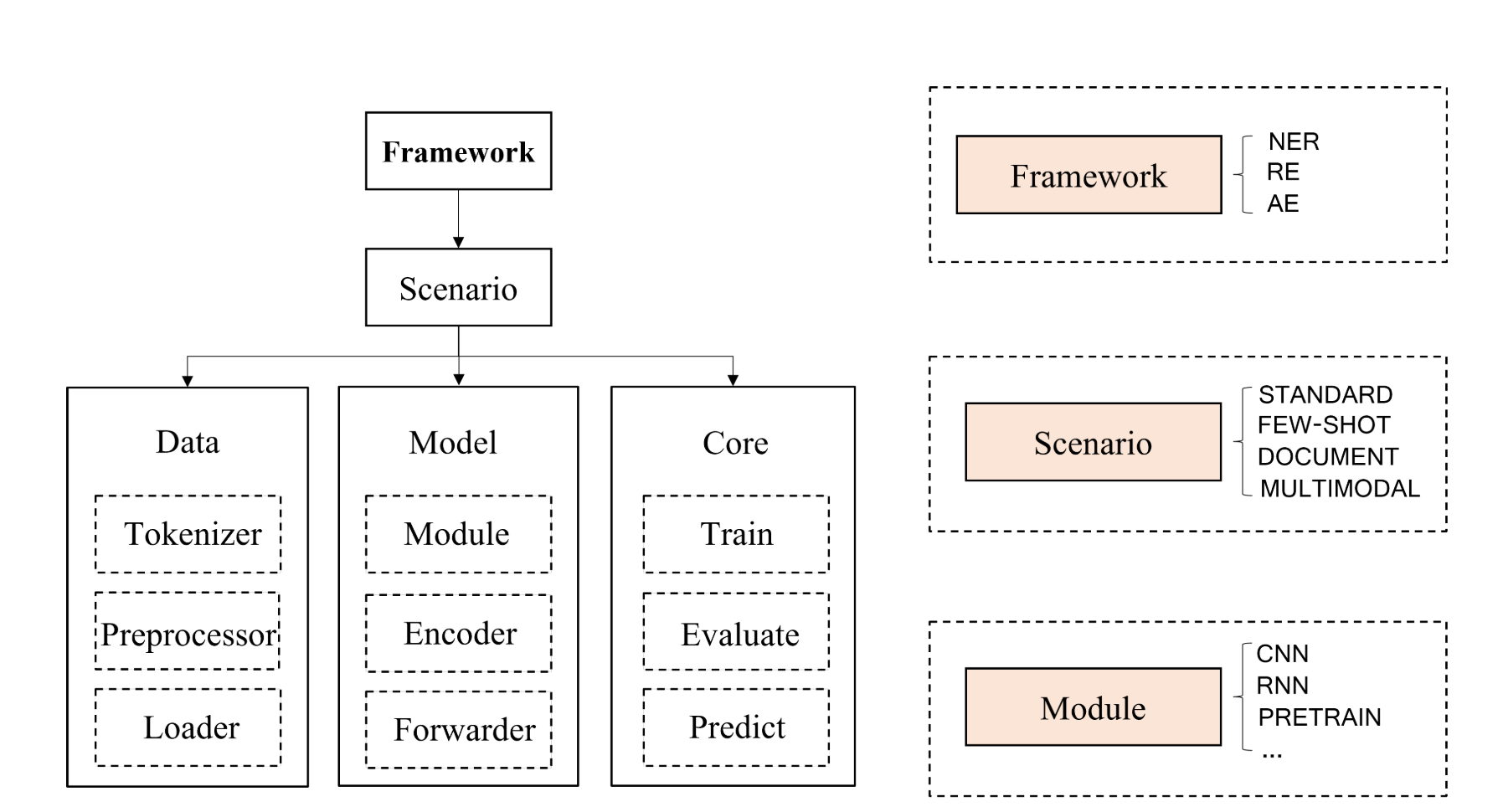
Data Module
数据模块主要完成数据的预处理和加载。其中的Tokenizer负责实现中文/英文的标记化。图像等其他视觉对象在多模态设置下先转化成视觉信息如标记或image patch。
Model Module
模型模块包含了三个核心任务需要用到的主要神经网络,如CNN/RNN/Transformer。DeepKE使用统一的Model Loader和saver实现BasicModel类,以此集成多种网络模型。
Core Module
核心模块主要包括了train/validate/predict方面的代码。train/predict中的各种参数(epoch/data/optimizer)可以具体指定。
Framework Module
框架模块整合了上述三个模块和不同的场景,支持多种功能实现,包括数据处理/模型构建/模型实现。通过修改yaml文件也可以对任务进一步客制化。
Toolkit Usage
本节介绍了不同场景下DeepKE用到的一些技术。
针对多模态场景,使用基于Transformer的识别抽取方法——IFAformer。具体来说,IFAformer同时将文本信息和视觉特征放在每个注意力层的key-value对中,隐式融合了文本和视觉特征。
其他场景略。
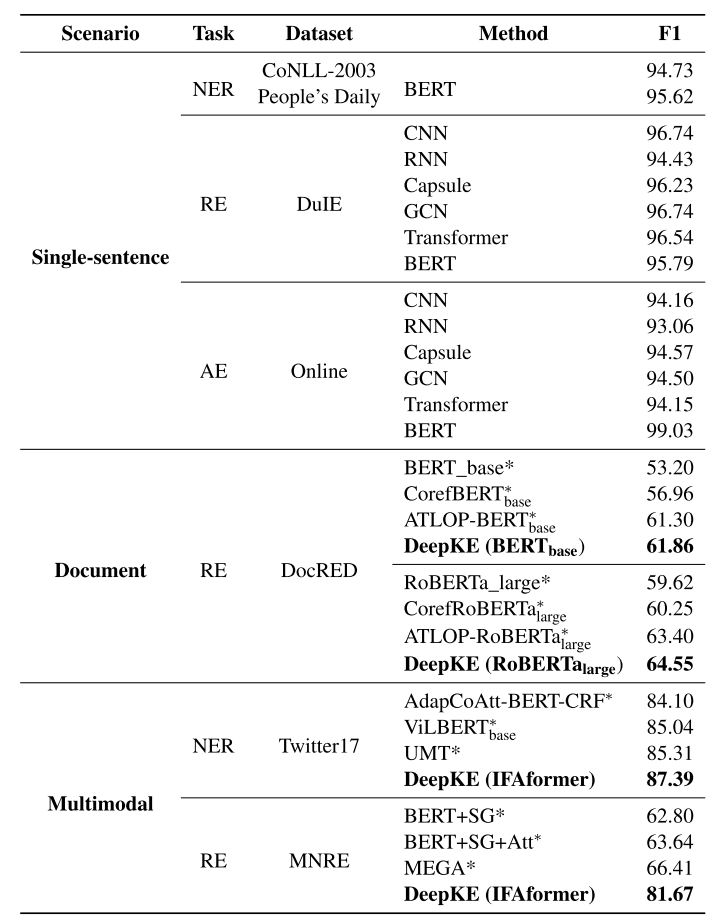
Experiment and Evaluation
将DeepKE和其他现有的KBP进行对比。略。
Conclusion
在实际应用中,知识库的填充需要处理低资源、文档级和多模态的场景。为此,文章提出了一个开源的可扩展知识抽取工具DeepKE。他们进行了广泛的实验,证明通过DeepKE实现的模型可以实现与一些最先进的方法相当的性能。此外,我们提供了一个在线系统,支持实时抽取(与预定义的模式),无需训练。我们将提供长期的维护来修复错误,解决问题,添加文档(教程)和满足新的要求。
Toolkit Usage Details
本节主要介绍了一下DeepKE的使用。包括各个任务的数据生成,源码修改等。
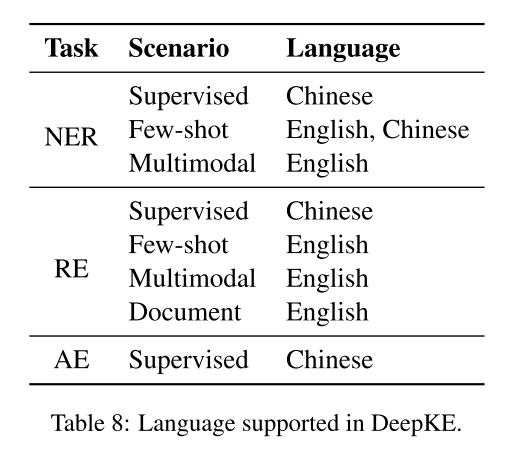
不同任务/场景支持的语言如下表。
自动超参调整使用了Weight&Biases这个工具。
评论