
论文地址:https://dl.acm.org/doi/abs/10.5555/3495724.3496802
摘要与引言
目前针对深度神经网络对抗脆弱性的研究进展迅速(如对抗样本、鲁棒性检验等)。现有的攻击需要内部访问(如受害者模型架构,参数或训练集)或外部访问(查询受害者模型)。然而在许多场景中,这两种访问都可能是不可行的或成本昂贵的。本文研究了无框对抗的例子,其中攻击者既不能访问模型信息或训练集,也不能查询模型。相反,攻击者只能从与受害者模型相同的问题域中收集少量示例。这种更强大的威胁模型大大扩展了对抗性攻击的适用性。
实验表明,在prototypical auto-encoding models上制作的对抗样本可以很好地转移到各种图像分类和人脸验证模型中。在www.example.com拥有的商业名人识别系统上clarifai.com,此方法将系统的平均预测准确率显著降低到仅15.40%,这与从预训练的Arcface模型中转移对抗样本的攻击相当。
No-box攻击相比于现在基于查询或转移的黑盒攻击来说,攻击条件更为严格:攻击者既不能访问大规模的训练数据,也无法查询模型,只能通过从同一问题域中收集少量的辅助样本。
文章的亮点在于基于无框攻击的假设,提出了在少样本(few-shot)情况下训练"替代"模型的方法。具体来说有三种训练机制:1)估计每张旋转图像的正视图;2)估计每个拼图的正确组合;3)原型图像重建。这三种策略中,前两种属于自监督学习(Self-Supervised Learning),第三种属于监督学习。结果是第三种基于图像重建的训练方式效果最好。
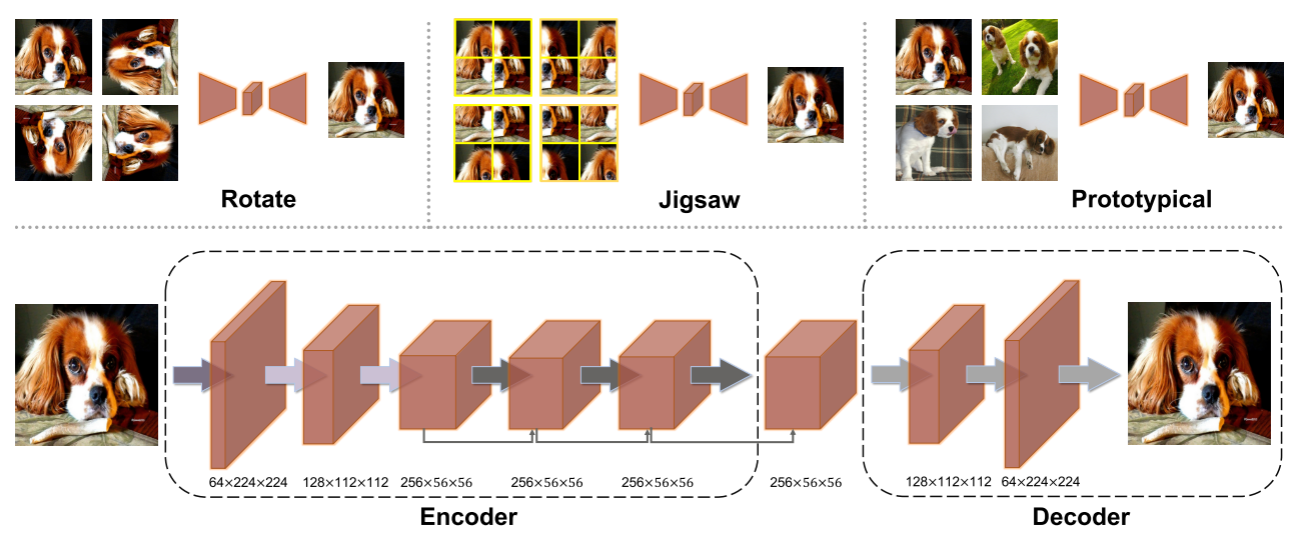
替代模型采用的是编码器-解码器架构的image-to-image auto-encoding models;模型预测时,首先将样本重建,通过判断重建后的样本与样本库之间的相似性确定其类别。
制作对抗样本则采用在"替代"模型上应用I-FGSM方法(源码中还使用了PGD)。最后在编码器输出上还使用了ILA。
ILA aims to enlarge intermediate-level perturbations in the direction of guiding examples,by maximizing projections on their mid-layer representations
训练策略
目标:假设良性样本$x_0$被扰动,使得被错误分类到其他标签中。我们的目标是在一个小型的数据集$\textstyle{\mathcal{X}}:=\{(x_{i},y_{i})\}_{i=0}^{n-1}$上训练一个判别(替代)模型,包括扰动的实例$x_0$。我们首先考虑仅涉及两个类的数据集,即,$y_i ∈ \{0,1\}$。在本文中,如果没有其他说明,限制n ≤ 20,从而满足few-shot的条件。
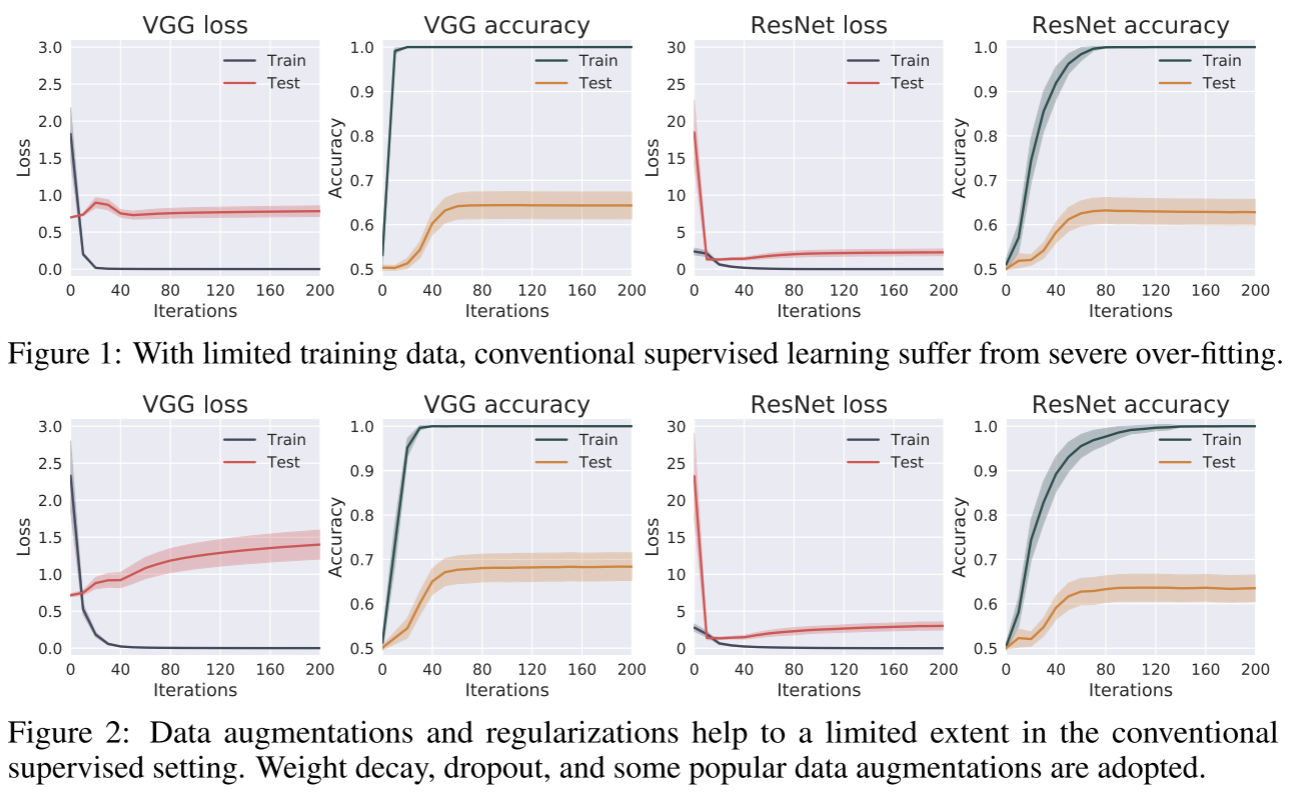
对于传统监督学习来说,比如交叉熵损失+Softmax的分类DNN,少样本训练很容易带来过拟合的问题。模型的train loss会很快下降收敛,但是valid loss下降到一定程度就进入平台期(极端一点来说,就是模型记住了每张训练集图像,并没有从训练集中学到有用的特征拿来分类)。
虽然可以通过数据增广、权重衰退、BN层等正则化手段弥补少样本的不足,但是在无框假设下这些手段还是不能很好地训练替代模型。(毕竟才20张图片,实在是太少了)
下图是传统监督学习(以VGG/Resnet为例)在小型数据集的表现,第二行加入了各种正则化手段,基本没什么效果。(最近打比赛深刻认识到数据质量/数量的重要性
在传统监督学习效果有限的情况下,作者采用了image to image方法,它在建模数据的内部分布比较成功,可能适合无框攻击的假设。在这种情况下,作者提出了他的受害者替代模型:编码器-解码器架构的image-to-image auto-encoding models。并在此基础上提出了三种训练策略(传统的交叉熵损失在这里不适用)。
Reconstruction from chaos
前两种方法属于自监督学习。一个是预测图像旋转角度,另一个是拼图重建,这两种方法已经证明可以提高DNN的辨别能力。这两个人物的学习目标可以表述为:
$$
{\cal L}_{\mathrm{rotation/jigsaw}}={\frac{1}{n}}\sum_{i=0}^{n-1}\left|\right|\mathrm{Dec}(\mathrm{Enc}(T(x_{i})))-x_{i}|^{2}
$$
其中$T(.)$指旋转操作或裁剪拼接操作。虽然学习任务仍然是无监督的,但pretext information(前置任务的语义信息)是与内容相关的,应该有利于分类。
Prototypical image reconstruction
原型图像重建是一种监督学习。具体策略是:鼓励模型重建特定类的原型,例如输入属于1类的样本,模型的输出应该更靠近1类的图像。形式化上是最小化以下公式
$$
{\cal L}_{\mathrm{prototypical}}=\frac{1}{n}\sum_{i=0}^{n-1}((1-y_{i})||\mathrm{Dec}(\mathrm{Enc}(x_{i}))-x^{(0)}||^{2}+y_{i}||\mathrm{Dec}(\mathrm{Enc}(x_{i}))-x^{(1)}||^{2})
$$
其中$x^{(0)}∈ {x_i|y_i = 0}$和$x^{(1)}∈ {x_i|y_i = 1}$是分别是从两个类中随机选择的图像原型。这种训练策略迫使模型必须区分具有不同标签的样本,从而达到分类的效果。上式采用的是一个编码器的情况,其实也可以将模型拓展到多个解码器,将在实验中提及。
模型分类
当使用训练好的模型分类时,由于模型输出同样是张图片,所以无法使用softmax等基于概率的分类方法。这里借鉴无监督学习的思想,首先将预测样本输入模型得到重建图像,通过比对重建图像与样本库每张图片的距离(如欧式距离或余弦距离),将最接近的那张图像的标签作为预测值。形式化表示为
$$
\hat{y}=\arg\mathrm{min}||\mathrm{Dec}(\mathrm{Enc}(x))-x^{(y)}||.
$$
通过这种预测方法,实验证明它相比于传统的监督学习方法更少收到过拟合的影响,并且在此基础上生成的对抗样本更具有迁移性。
对抗样本生成
在image-to-image auto-encoding models采用基于梯度的攻击如I-FSGM、PGD来生成对抗样本。形式化来说就是最大化下式
$$
L_{\mathrm{adverarial}}=-\log p(y_{i}|x_{i})\quad{\mathrm{where}}\quad p(y_{i}|x_{i})={\frac{\exp{(-\lambda||\mathrm{Dec}(\mathrm{Enc}(x_{i}))}-{\tilde{x}_{i}}||^{2})}{\sum_{j}\exp{(-\lambda||\mathrm{Dec}(\mathrm{Enc}(x_{i}))-{\tilde{x}}_{j}}||^{2})}}
$$
其中$\lambda$是缩放因子,使用I-FSGM时取$\lambda=1$.其中$\tilde{x}_{i}$是正类样本,$\tilde{x}_{j}$是负类样本。上式的含义就是最大化对抗样本与正样本之间的距离,最小化对抗样本与负类样本之间的距离。在encoders输出后,还结合了ILA进行攻击。ILA通过最大化中间层表示的投影,在指导样本的方向上扩大中间层的扰动。(不是很了解)
总结来说,首先对模型应用基于梯度的基线攻击(例如I-FGSM)最大化$L_{adversarial}$,然后对编码器的输出执行ILA。
实验
论文在两个任务上进行了实验,图片分类与人脸识别。
对于图像分类,我们基于良性ImageNet图像,在最大扰动($L_\inf$)不大于0.1或0.08的约束下制作对抗样本。这些图像是从ImageNet验证集中选择的。从一半的ImageNet类中随机选择了5000张图像(即,500个类和每个类10个图像)来生成对抗样本。
对于人脸验证,首先在LFW数据集上攻击开源模型,最大扰动不超过0.1,然后使用clarifai.com拥有的商业系统进行测试。我们从LFW的400多个身份中随机抽取了2110张图像,这些图像保证尚未用于训练所有相关的受害者模型。
实验配置
- 采用CycleGAN 的生成器作为替代模型,即上文提到的auto-encoding models
- 使用来自两个类的不超过20个图像(即n ≤ 20)来训练每个替代模型,并在此基础上执行像I-FGSM的基于梯度的基线攻击。
- 训练策略总结为两个无监督(根据旋转和拼图的重构)和一个受监督的(原型重建)训练机制。其中旋转只考虑了四个方向:0°、90°、180°和270°;对于拼图,将原始图像均匀地切割成四个图块,然后进行洗牌。
- 所有模型都使用ADAM进行了最多15000次迭代的训练,固定学习率为0.001。如果在每个小训练集上达到性能平台期,训练可以提前停止。
- 替代模型训练结束,首先运行基线攻击(I-FGSM)进行200次迭代,然后再迭代100次运行ILA。对于所有实验,λ简单地设定为1。其中I-FGSM的优化步长为1/255(ImageNet和LFW都一样)。
对比模型
共对比了以下四种模型做替代模型的效果。
- naive †:是传统监督学习的Resnet,使用数据增强和正则化进行训练
- naive ‡:是无监督学习的自动编码器(网络架构和原型重建一致,但是只使用旋转和拼图两种无监督学习的训练方式)
- Beyonder:是大规模预训练的模型,甚至可能与受害者模型共享数据集(传统基于迁移的黑盒攻击)
- Prototypical:论文中提到的基于图像重建的监督学习方法。
攻击模型
在以下模型上测试了对抗样本的迁移性与攻击成功率。
在ImageNet上测试了非常不同的受害者模型,包括带BN的VGG-19 、Inception v3 、ResNet-152 、DenseNet 、SENet 、广域ResNet(WRN)、PNASNet和MobileNet v2。
对于人脸验证,我们采用了FaceNet 和Cosface。
实验效果
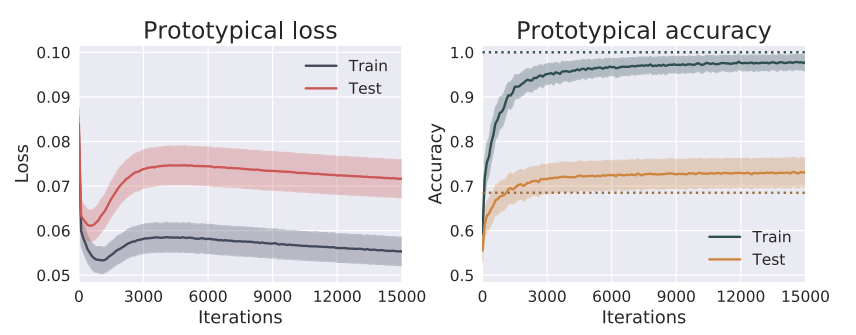
首先是Prototypical模型的训练效果。观察loss可知,相比于之前的迅速收敛,这里Test Loss还有下降的趋势,可以说受到过拟合的影响较小。Test的精度较传统VGG来说也有所提升。
还对比了不同解码器数量的Prototypical模型表现,当使用多个解码器时,模型预测的标签表示为
$$
\hat{y}=\mathrm{arg\space min}\,\frac{1}{K}\sum_{k=0}^{K-1}||\mathrm{Dec}_{k}{\big(}\mathrm{E}\mathrm{n}{\mathrm{c}}{\big(}x{\big)}{\big)}-x_{k}^{(y)}||
$$
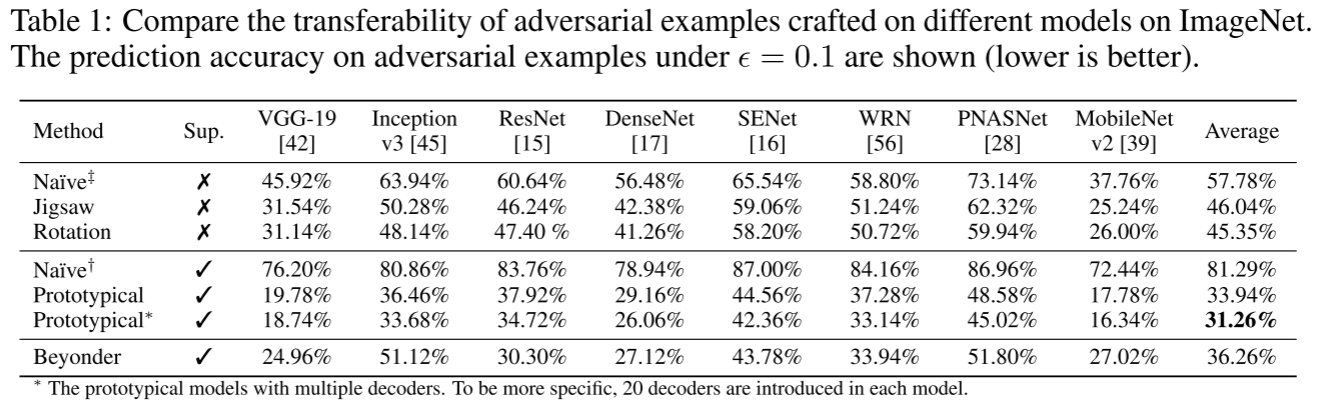
其效果与单个解码器相比也有提升。受害者模型的预测精度如下图,*可以发现$Prototypical$产生的对抗样本平均攻击效果最好**。
对于人脸验证攻击,展示了不同攻击方式下受害者模型的ROC曲线。可以发现有时候基于图像重建的方式甚至效果比大规模的预训练模型Beyonder还好。
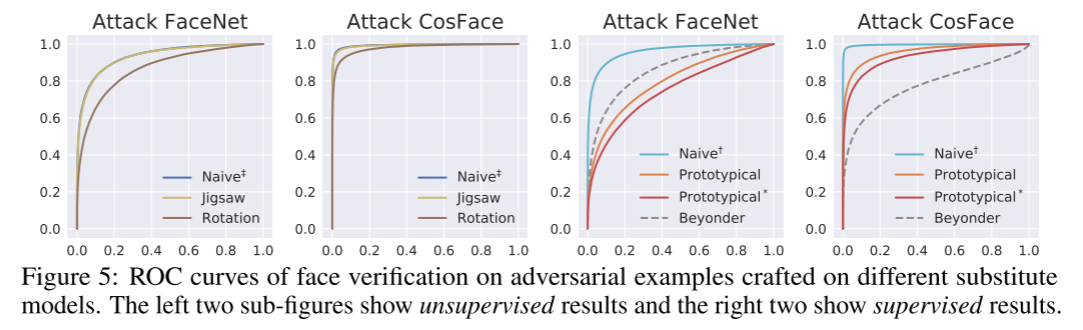
对于人脸验证的对抗样本生成,对抗损失需要稍作修改,因为一对面孔通常通过计算嵌入空间中的余弦相似度来进行比较。
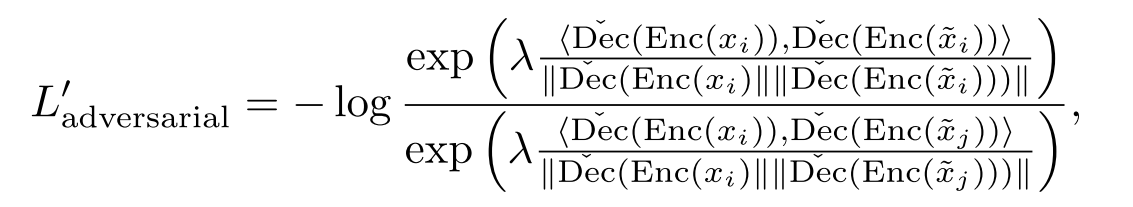
结论
文章考虑了一个现实的威胁模型来执行对抗攻击,基于无框的假设,查询模型和大规模训练、获取受害者模型的内部信息等方式都被禁止。
文章设法使用有限的数据来训练模型(few-shot),基于这些数据可以制作可转移的对抗样本。具体提出了无框设置中的替代模型训练的不同机制(3种)。其中表现最好的是有监督的图像重建,它产生的对抗样本可以很好地转移到各种先进分类器上。
这种基于few-shot和Self-Supervised Learning的方法的有效性在图像分类和人脸验证上进行了测试。实验结果表明,该方法的性能优于传统的监督学习方法,有时甚至可以与传统基于黑盒的攻击(共享训练集)相媲美。
评论