
整体思路
创建DataSet首先需要继承torch.utils.data.Dataset这个类,然后再init函数中完成数据的一些预处理,比如xml文件的解析/类与序号的映射/图片路径的存储等。
接下来需要重载__len__和__getitem__两个方法,分别返回数据长度和某个序号对应的图片(包括图片本身和标注)
如果用到多GPU训练,按照Pytorch官方的建议,最好再实现
get_height_and_wight这个方法,节约内存.(因为这样可以避免pytorch将所有图片读入计算宽高)
源码细节
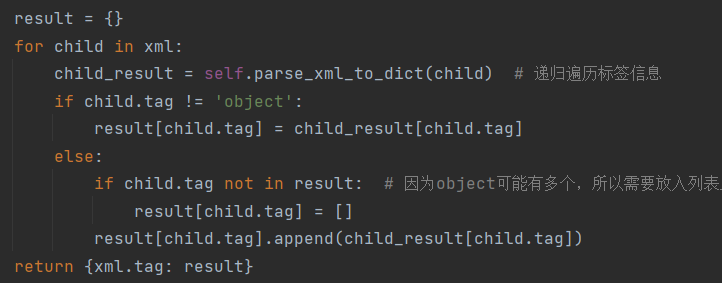
1. xml解析
在init方法中调用了parse_xml_to_dict方法解析xml文件,获取其中的object信息.(物体的类别/位置/边界框)

而parse_xml_to_dict具体使用递归的方法遍历标签信息,返回字典类型的数据
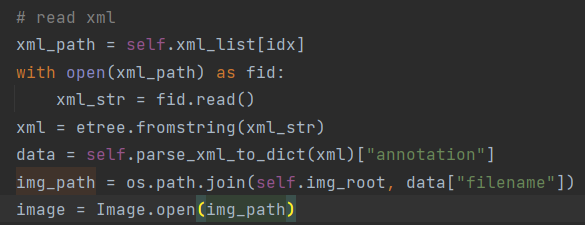
2.__getitem__方法
首先通过上述的给出的xml解析方法解析图片对应的xml文件,将结果存入data变量.图片也通过Image.open打开
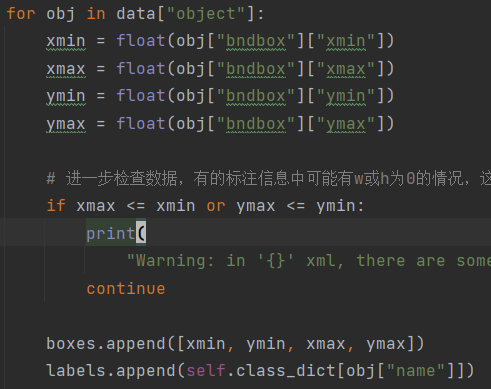
接下来将data中的边界框和类别数据进行读取,丢到boxes和labels列表中.
之后注意将这些数据转换成Tensor类型
最后将信息都整理到target中,作为整体的标签返回.
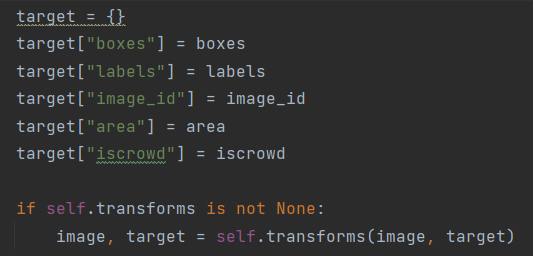
最后还需要判断是否对图片进行data augmentation
3.Transform
transform有很多类型,这里简单介绍一下水平翻转的实现.需要注意的是图片翻转之后,边界框的标注位置也需要翻转.
对于水平翻转: y坐标不需要改变,xmax变为width-xmin,xmin变为width-xmax
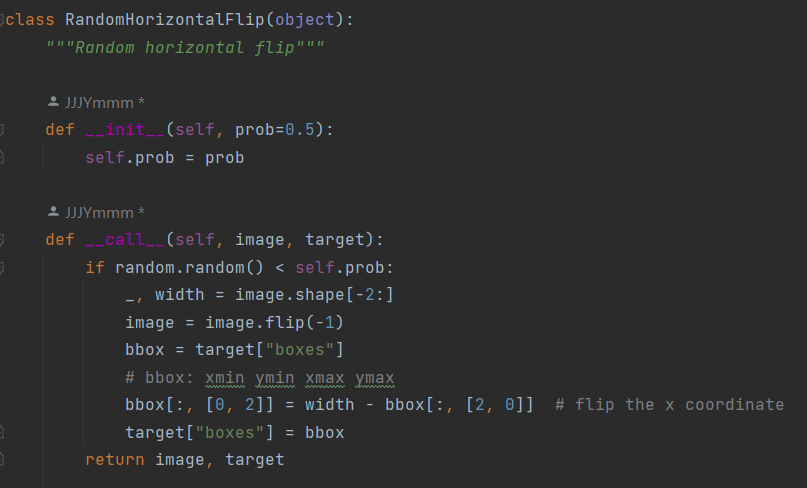
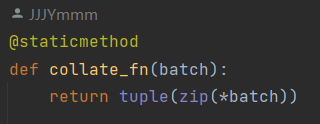
4.collate_fn
为了之后实现dataloaer,这里需要实现collate_fn函数.
不同于分类网络中dataset只返回一张图片和一个label(形式比较固定),目标识别网络中需要返回图片加标注,而标注是不等长的,使用默认的stack有可能出现问题.所以需要手动用collate_fn方法进行堆叠.
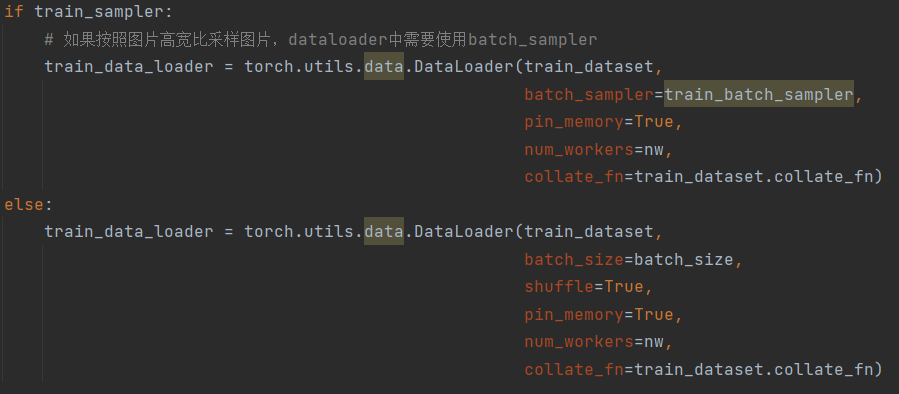
下图是dataloader的实现,这里传入了collate_fn.不传入这个参数默认使用torch.stack()对
__getitem__的每个返回值进行堆叠
评论