
OFD(Open Fixed-layout Document)
OFD 是开放版式文档(Open Fixed-layout Document )的英文缩写,是我国国家版式文档格式标准,通俗来说,也有人称这格式为国产PDF。但是在很多方面的性能优于PDF的同类文档。OFD也逐渐开始在电子发票、电子公文、电子证照等等的领域中应用。
JJJYmmm目前有把OFD转换成txt的需求,但是网上大多是OFD<--->PDF的方法。所以决定自己动手,丰衣足食(bushi)
OFD格式
OFD其实一个压缩文件,如果我们尝试解压,将会得到如下的目录结构。
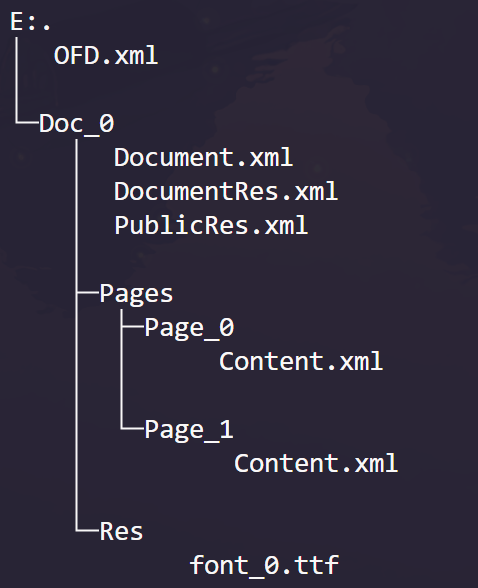
- OFD.xml里面一般是文档的描述信息,比如创建时间、最迟修改时间、作者等等
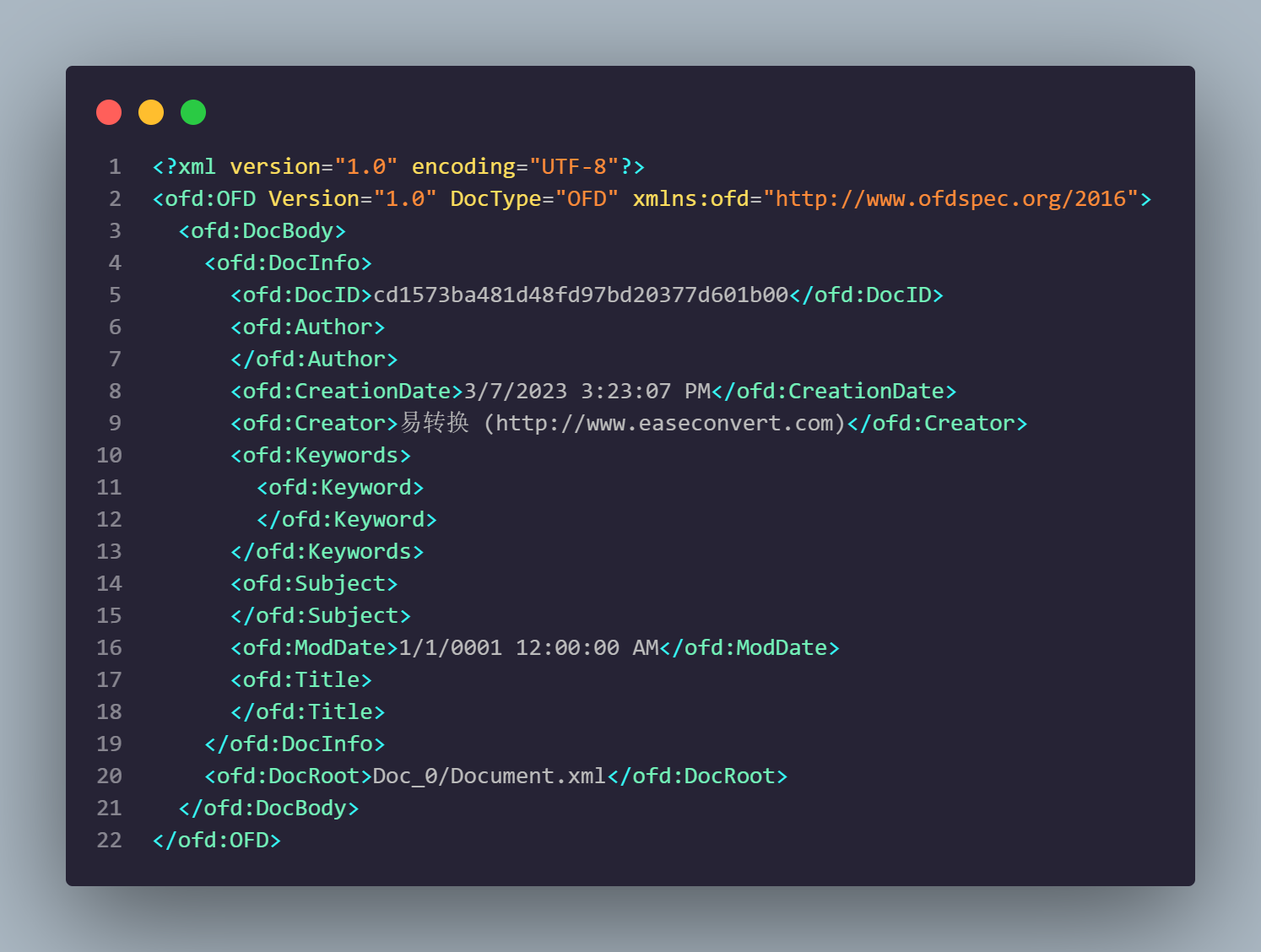
- Doc_0里保存的是具体文档信息,我们主要关注Pages文件夹中的内容Content.xml,这里面保存的是文档主体内容,也就是我们需要提取的.
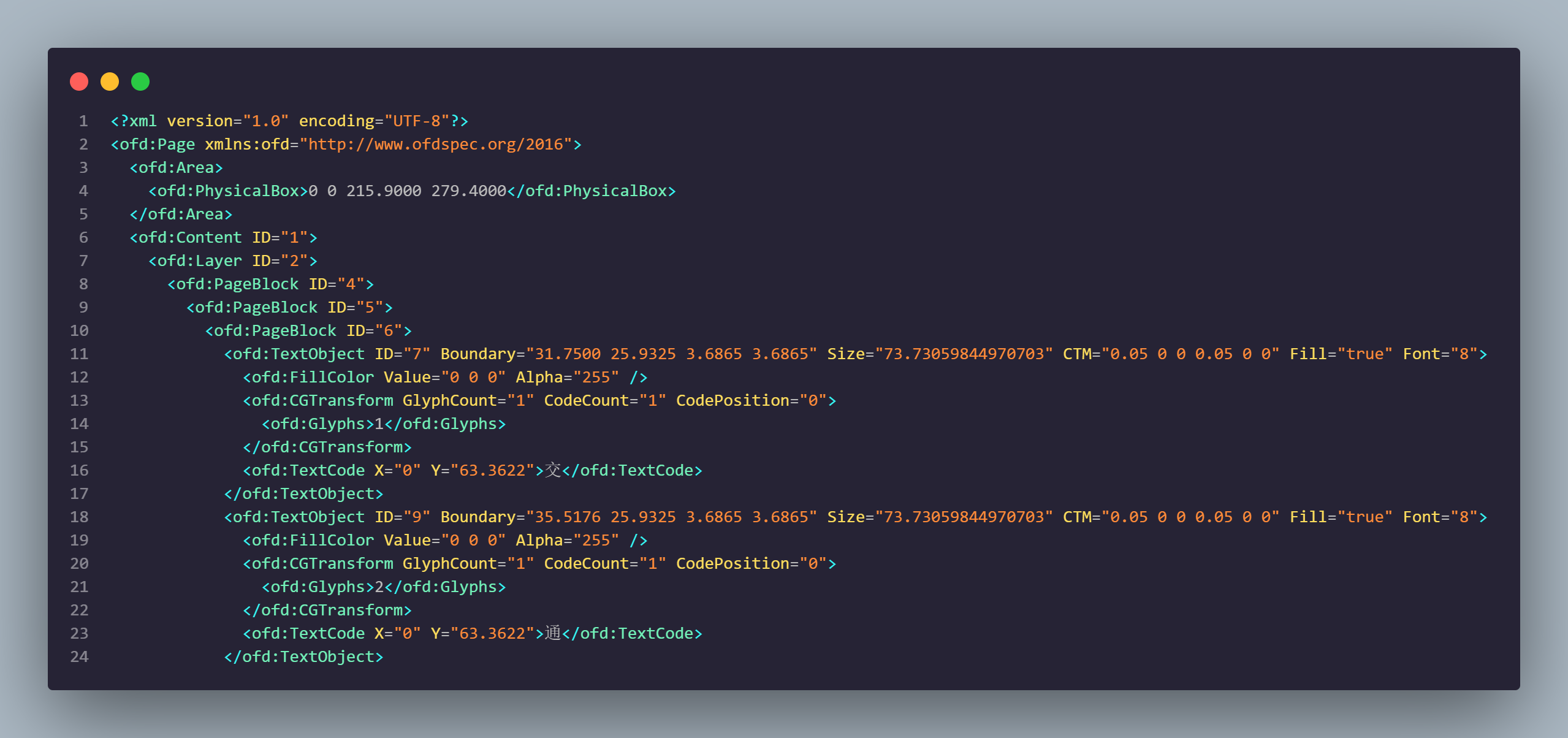
- 观察Content.xml里的内容,可以发现 : 字符在\<ofd:TextCode>字段中,而\<ofd:TextCode>嵌套在\<ofd:TextObject>对象里,众多TextObject封装在\<ofd:PageBlock>,外层还有\<ofd:PageBlock>/\<ofd:Layer>等字段
Python脚本处理xml
接下来可以编写Python脚本来处理xml了!!!
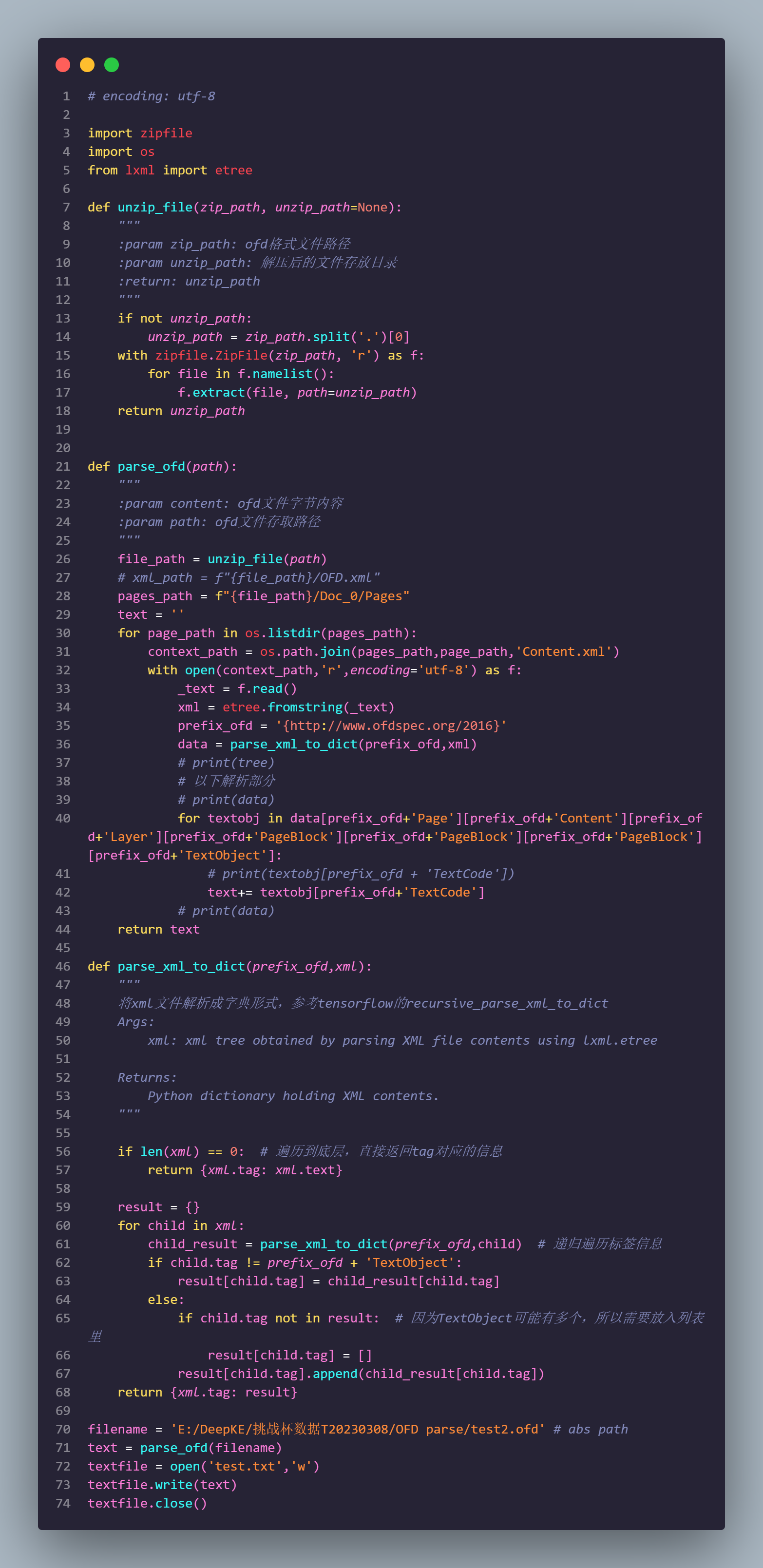
首先就是解压OFD,直接当成普通压缩文件解压即可.
def unzip_file(zip_path, unzip_path=None):
"""
:param zip_path: ofd格式文件路径
:param unzip_path: 解压后的文件存放目录
:return: unzip_path
"""
if not unzip_path:
unzip_path = zip_path.split('.')[0]
with zipfile.ZipFile(zip_path, 'r') as f:
for file in f.namelist():
f.extract(file, path=unzip_path)
return unzip_path解析XML则借鉴之前FasterRCNN源码中的解析方法.因为TextObjcect对象和目标检测中的Bounding Box类似,有很多实例,故思路是一致的,即通过递归方法解析XML为dict,遇到TextObject对象时value值用列表保存.代码如下:
def parse_xml_to_dict(prefix_ofd,xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(prefix_ofd,child) # 递归遍历标签信息
if child.tag != prefix_ofd + 'TextObject':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为TextObject可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}这里存在一个 prefix_ofd 前缀,具体来说,这取决于xml第一个字段Page中的xmlns:ofd字段,在使用etree进行解析时,键值中的ofd:会被替换成xmlns:ofd字段,具体原理JJJYmmm暂时也不太清楚,是在debug时发现的()
将XML解析成字典后,就可以遍历字典取出我们想要的结果了~具体代码如下,还是比较简单的
pages_path = f"{file_path}/Doc_0/Pages"
text = ''
for page_path in os.listdir(pages_path):
context_path = os.path.join(pages_path,page_path,'Content.xml')
with open(context_path,'r',encoding='utf-8') as f:
_text = f.read()
xml = etree.fromstring(_text)
prefix_ofd = '{http://www.ofdspec.org/2016}'
# xml to dict
data = parse_xml_to_dict(prefix_ofd,xml)
# 遍历TextObject
for textobj in data[prefix_ofd+'Page'][prefix_ofd+'Content'][prefix_ofd+'Layer'][prefix_ofd+'PageBlock'][prefix_ofd+'PageBlock'][prefix_ofd+'PageBlock'][prefix_ofd+'TextObject']:
# print(textobj[prefix_ofd + 'TextCode'])
text+= textobj[prefix_ofd+'TextCode']效果展示
以一份政府公文为例,首先用OFD查看器查看内容.

执行脚本,demo如下图.
最后保存得到的txt如下.可以发现文章内容都提取出来力.

TODO
- 第一个问题是最后提取出来的txt没有换行符.这个问题在于OFD的xml文件里本来就没有保存换行符,是直接通过坐标进行渲染的(详见TextObject的Boundary字段).
- 第二个小问题是没有封装成批量处理脚本,但是这个问题不大(单纯是不想写 咕了)
评论