
基本概念
K折交叉验证用于评估一个模型的泛化性能,那么网格搜索通过调参来提高模型的泛化性能.
简单的网格搜索实现
提前划分好训练集和测试集,简单通过两个for循环寻找最佳参数,评估效果直接使用模型自带的score.
# naive grid search implementation
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, random_state=0)
print("Size of training set: {} size of test set: {}".format(
X_train.shape[0], X_test.shape[0]))
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
# for each combination of parameters, train an SVC
svm = SVC(gamma=gamma, C=C)
svm.fit(X_train, y_train)
# evaluate the SVC on the test set
score = svm.score(X_test, y_test)
# if we got a better score, store the score and parameters
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
print("Best score: {:.2f}".format(best_score))
print("Best parameters: {}".format(best_parameters))验证集的引进
上节实现的简单网格搜索存在一个致命问题:将用来调整参数的测试集用于评估模型的好坏!
换句话说,我们是在测试集上选择出来的最佳参数,整个参数不能保证对于新数据也work well.所以需要引入一组新数据.那么数据总共就被分为三份:
- 用于训练模型的训练集
- 用于调整超参数的验证集
- 用于评估模型的测试集
测试集模型训练阶段从未见过,只在评估时使用.
验证集用来衡量训练集训练出来的模型好坏
最后评估时,模型会选择表现最好的超参,用训练集+验证集重新训练,再用测试集进行评估.这一步主要是充分利用验证集数据.
from sklearn.svm import SVC
# split data into train+validation set and test set
X_trainval, X_test, y_trainval, y_test = train_test_split(
iris.data, iris.target, random_state=0)
# split train+validation set into training and validation sets
X_train, X_valid, y_train, y_valid = train_test_split(
X_trainval, y_trainval, random_state=1)
print("Size of training set: {} size of validation set: {} size of test set:"
" {}\n".format(X_train.shape[0], X_valid.shape[0], X_test.shape[0]))
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
# for each combination of parameters, train an SVC
svm = SVC(gamma=gamma, C=C)
svm.fit(X_train, y_train)
# evaluate the SVC on the validation set
score = svm.score(X_valid, y_valid)
# if we got a better score, store the score and parameters
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
# rebuild a model on the combined training and validation set,
# and evaluate it on the test set
svm = SVC(**best_parameters)
svm.fit(X_trainval, y_trainval)
test_score = svm.score(X_test, y_test)
print("Best score on validation set: {:.2f}".format(best_score))
print("Best parameters: ", best_parameters)
print("Test set score with best parameters: {:.2f}".format(test_score))带交叉验证的网格搜索
上一节中人为分出了测试集\训练集\验证集,这钟方法对于数据的划分也比较敏感.因此可以在划分训练集/验证集时使用交叉验证,更好的评估模型的泛化能力.
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
# for each combination of parameters,
# train an SVC
svm = SVC(gamma=gamma, C=C)
# perform cross-validation
scores = cross_val_score(svm, X_trainval, y_trainval, cv=5)
# compute mean cross-validation accuracy
score = np.mean(scores)
# if we got a better score, store the score and parameters
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
# rebuild a model on the combined training and validation set
svm = SVC(**best_parameters)
svm.fit(X_trainval, y_trainval)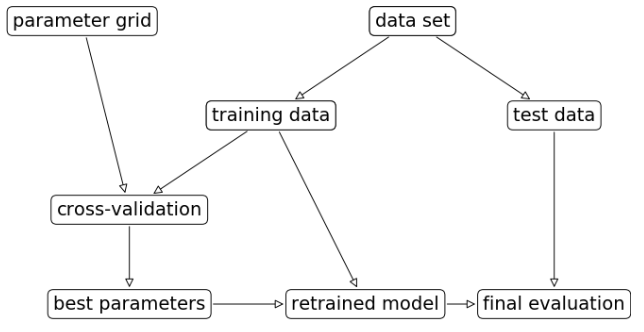
GridSearchCV 热图可视化
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
grid_search = GridSearchCV(SVC(), param_grid, cv=5,
return_train_score=True)
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, random_state=0)
grid_search.fit(X_train, y_train)
scores = np.array(results.mean_test_score).reshape(6, 6)
# plot the mean cross-validation scores
mglearn.tools.heatmap(scores, xlabel='gamma', xticklabels=param_grid['gamma'],
ylabel='C', yticklabels=param_grid['C'], cmap="viridis")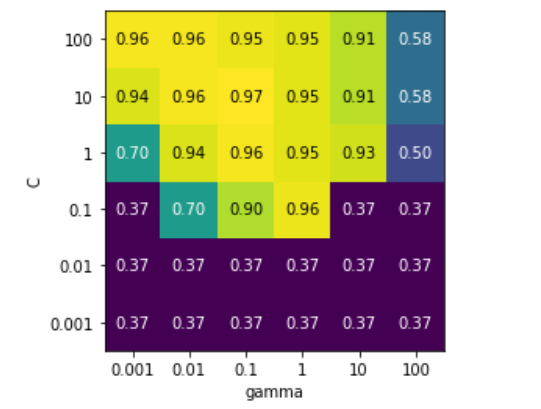
不同的交叉验证策略
嵌套交叉验证
在交叉验证的网格搜索中,我们使用交叉验证来完成训练集/验证集的划分,测试集的划分我们还是手动的.嵌套交叉验证让我们测试集的划分也使用交叉验证.这会使结果更合理,当然需要训练模型的个数也upup~(比如36个模型超参数组合,嵌套交叉验证都是5折,那就需要训练900个模型)
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
scores = cross_val_score(GridSearchCV(SVC(), param_grid, cv=5),
iris.data, iris.target, cv=5)
print("Cross-validation scores: ", scores)
print("Mean cross-validation score: ", scores.mean())
评论