
摘要
Faster RCNN在Fast RCNN的基础上增加了RPN网络来代替比较耗时的Selective Search。RPN网络和检测网络共享同一张卷积特征图,他同时预测每个位置的前景(背景)概率和每一类相对于锚框的偏移,得到的预测框将送入Fast RCNN的检测头进行进一步的分类和BBOX回归。
对于非常深的VGG-16模型,Faster RCNN在GPU上的帧速率为5fps(包括所有步骤),同时在PASCAL VOC 2007、2012和MS COCO数据集上实现了最先进的对象检测精度,每张图像只有300个建议框。在ILSVRC和COCO 2015竞赛中,Faster R-CNN和RPN是多个赛道第一名获奖作品的基础。
算法流程

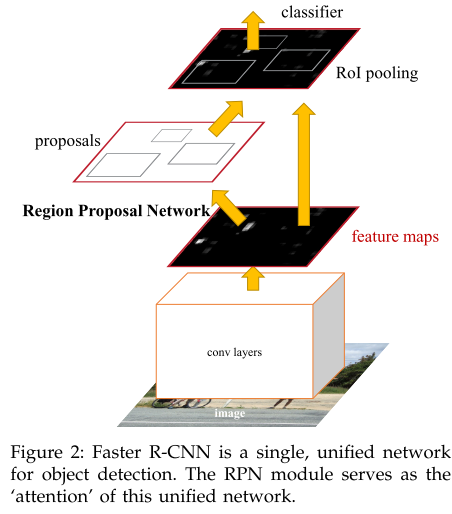
RPN网络结构
正向传播
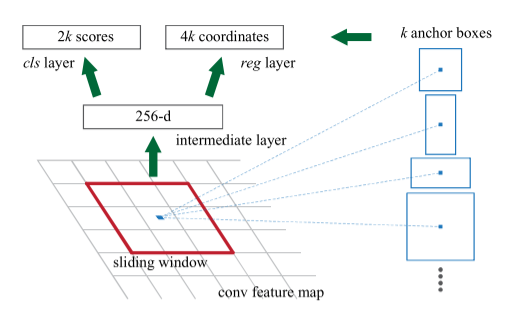
对于特征图上的每个3x3的滑动窗口(实际实现就是用conv3x3 p1 s1),首先计算窗口中心点在原图上的位置,并计算出k个anchor box
对于anchor的选择,共有三种比例,三种尺度,即每个位置都有9个anchor

感受野
对于特征图上的感受野,骨干网络为ZFNet时,感受野为171;骨干网络为VGG16时,感受野为228(具体计算如下)
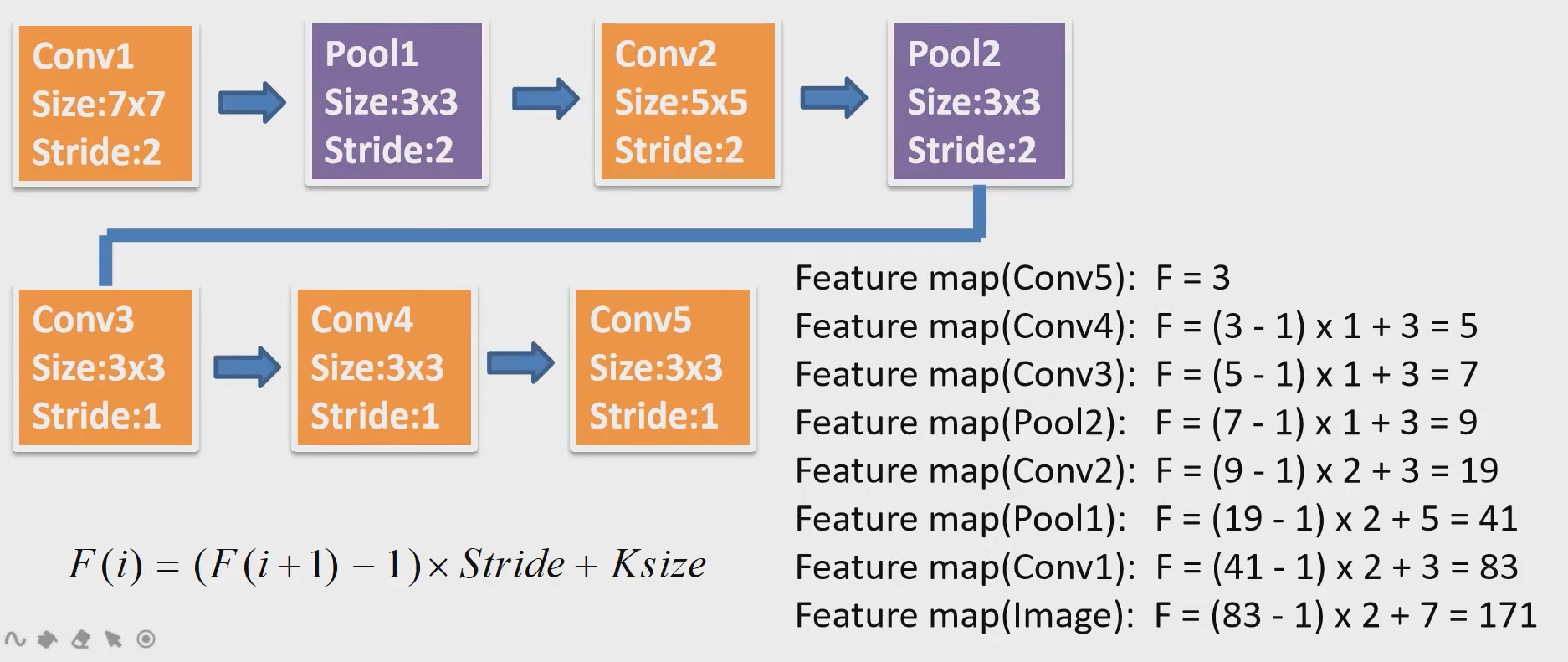
有个问题是,无论是VGG/ZF骨干网络,一个位置的感受野最多也就是228x228,那为什么anchor box的尺寸可以设置到256x256甚至512x512? 在论文中解释是说,通过物体的局部来预测物体是有可能的,实际上这么设置表现也确实有所提升(

anchor->proposal

正负样本选择
训练时,每个mini-batch,即每张图片随机选择256个anchor,这些anchor中正负样本比例大约是1:1。如果正样本数目不足128,那就用负样本补足到256.

正负样本定义如下:
正样本:①和某个GT Box的IoU大于0.7
②是和某个GT Box的IoU最大的anchor(就是对第一条规则的补充,避免出现某个GT Box没有分配anchor)
负样本:和所有的GT Box的IoU都小于0.3
RPN 损失
RPN网络的损失分为两部分,分类损失和边界框损失。分类主要是衡量预测框中是否含有物体(类似于YOLO系列中的objectness),边界框损失就是简单的回归损失。


分类损失有两种实现:
如果每个anchor只有一个预测值,那么就使用BCE二元交叉熵损失;
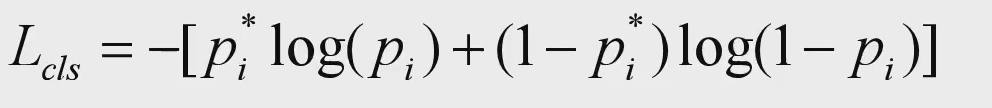
如果每个anchor有两个预测值,那么就使用Softmax Cross Entropy。
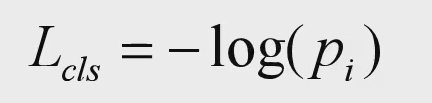
边界框回归损失和Fast RCNN一样,都是用SmoothL1 Loss.*标注值t的计算参考RCNN中的实现。**
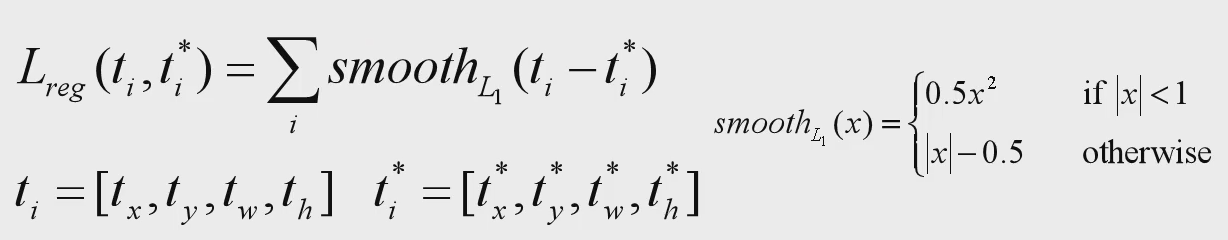
Detect Loss
检测网络的损失和Faster-RCNN网络的损失一摸一样。这里不再赘述。
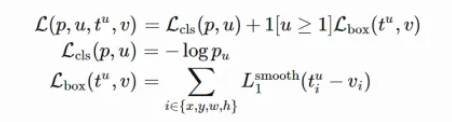
网络训练

现在可以直接采用RPN loss+Fast R-CNN Loss联合训练网络

自己的一点理解
从损失函数来看,Faster R-CNN和YOLO挺像的(应该是YOLO借鉴的ROI思想)。
在YOLO系列中,对于每个grid cell会预测k个anchor(since v2),对于每个anchor会预测一个置信度(objectness),边界框偏移和类别预测。这里的类别预测同v1一样,是条件概率,即在置信度基础上的概率。
而在Faster R-CNN中,置信度和类别预测被拆开成了两个网络,RPN网络负责预测置信度和边界框偏移;Fast R-CNN网络负责预测类别和边界框偏移。
RPN网络提供Proposal,其实就是在置信度的基础上筛选出一些质量高的锚框(当然还需要根据边界偏移调整获得最后的region proposal)。
Fast R-CNN接到Proposal后,根据它在特征图上的映射获得特征矩阵,再通过RoI pooling层获得获得固定大小的矩阵,送入全连接层预测类别和bbox回归。那么这里的类别同样可以理解成条件概率,因为得到的候选框是经过RPN网络筛选过的,即在置信度满足一定条件时预测出的概率。
所以YOLO系列其实就是将RPN网络和Fast R-CNN网络进行了合并。至于锚框生成,区别于RPN网络在特征图上通过滑动窗口生成,YOLO更加简单粗暴,直接将原图分割并在每个单元上生成锚框。
评论