
相较于RCNN的改进
-
Fast RCNN仍然使用selective search选取2000个建议框,但是这里不是将这么多建议框都输入卷积网络中,而是将原始图片输入卷积网络中得到特征图,再使用建议框对特征图提取特征框。这样做的好处是,原来建议框重合部分非常多,卷积重复计算严重,而这里每个位置都只计算了一次卷积,大大减少了计算量
-
由于建议框大小不一,得到的特征框需要转化为相同大小,这一步是通过ROI池化层(region of interest)来实现的
-
Fast RCNN里没有SVM分类器和回归器了,分类和预测框的位置大小都是通过卷积神经网络输出的
-
为了提高计算速度,网络最后使用SVD代替全连接层
算法流程
- 输入一张图片,使用Selective Search获取建议框(region proposal)
- 将原始图片输入卷积神经网络之中,获取特征图
- 对每个建议框,从特征图中找到对应位置(按照比例映射),截取出特征框(深度保持不变)
- 将每个特征框划分为 HxW个网格(论文中是 7×7 ),在每个网格内进行最大池化(即每个网格内取最大值),这就是ROI池化。这样每个特征框就被转化为了 7×7×C 的矩阵
- 对每个矩阵展平为一个向量,分别作为之后的全连接层的输入
- 全连接层的输出有两个,计算class得分和bounding box回归。前者是sotfmax的21类分类器(假设有20个类别+背景类),输出属于每一类的概率(所有建议框的输出构成得分矩阵);后者是输出一个 20×4 的矩阵,4表示(x, y, w, h),20表示20个类,这里是对20个类分别计算了框的位置和大小
- 对输出的得分矩阵使用非极大抑制方法选出少数框,对每一个框选择概率最大的类作为标注的类,根据网络结构的第二个输出,选择对应类下的位置和大小对图像进行标注
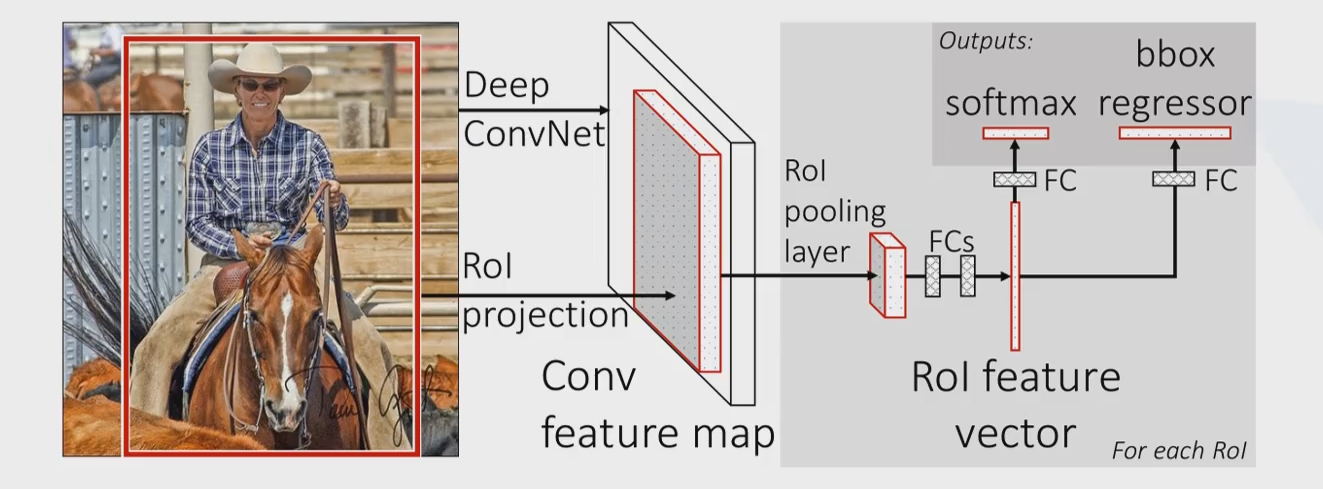
网络结构
网络backbone采用VGG-16,不用resnet是因为那个时候还没有resnet
最开始仍然是在ImageNet数据集上训练一个1000类的分类网络,随后将模型进行以下改动
- 最后一个最大池化层换成ROI池化层
- 将最后一个全连接层和后面的softmax1000分类器换成两个并行层,一个是全连接层1+21分类器,另一个是全连接层2+表示每个类预测框位置的输出
使用变动后的模型,在标注过的图像数据上fine-tuning,训练时要输入图像、标注(这里将人为标注的框称为ground truth)和建议框信息。这里为了提高训练速度,采取了小批量梯度下降的方式,每次使用2张图片的128张建议框(每张图片取64个建议框)更新参数。
训练网络
每次更新参数的训练步骤如下
- 2张图像直接经过前面的卷积层获得特征图
- 根据ground truth标注所有建议框的类别。具体步骤为,对每一个类别的ground truth,与它的iou大于0.5的建议框标记为groud truth的类别(正样本),对于与ground truth的iou介于0.1到0.5之间的建议框,标注为背景类别(负样本)
- 每张图片随机选取64个建议框(要控制背景类的建议框占75%),提取出特征框
- 特征框继续向下计算,进入两个并行层计算损失函数
- 反向传播更新参数(关于ROI池化的反向传播细节可以参考这篇博客)

损失函数
跟YOLO系列类似(其实应该是YOLO与rcnn类似),损失函数分成两部分——分类损失和回归损失。
- 对类别输出按照softmax正常计算损失(交叉熵损失)
- 对框的位置的损失方面,标注为背景类的建议框(负样本)不增加损失(体现在下面公式中的 [u>1] 艾弗森括号)。对于标注为物体类别的建议框(正样本)来说,先计算ground truth的四个标注参数,再和网络的预测值来计算loss(采用smoothL1 loss)
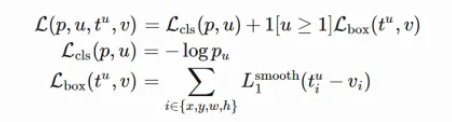
论文中的其他
- 在全连接层使用SVD分解来减少计算时间
- 模型在各种数据集上的测试效果及对比
- 在fine-tuning基础上更新哪些层的参数实验
- SVM V.S. softmax,输入多种规格的图片,更多训练数据等等

评论
розкрутка сайту в гугле