
论文地址
[1706.03762] Attention Is All You Need (arxiv.org)
Abstract
目前的主流序列转译模型基本是编码器-解码器架构的复杂RNN或CNN网络(当然现在已经是Transformer了),本文提出了一个简单的网络结构——Transformer。Transformer完全基于注意力机制,在机器翻译上可以达到比RNN/CNN更好的效果,同时并行化效率更高,训练时间更少。作者测试了模型在英翻德/英翻法翻译任务的效果,并尝试证明了Transformer对其它任务的泛化能力。
Introduction
简单介绍了一下当前序列建模和预测的主流方法——LSTM/GRU。
RNN在每个时间步都会生成一个隐状态Ht,Ht中保存了以往单词的历史信息,使RNN在序列任务上表现较好。当然,Ht需要按时间步依次计算,并行度比较低,计算效率比较低。同时历史信息是逐步传递的,对于序列比较长的输入,较早时间步的信息有可能被遗忘,当然这个可以通过增加隐藏层单元来缓解,不过这也会进一步导致内存过大的问题。
Attention机制其实已经应用在序列模型中,不过依旧是结合RNN在做。
本文提出完全基于Attention机制的Transformer,并行度比较高。
Model Architecture
Transformer整体架构如下图。接下来将逐层介绍。
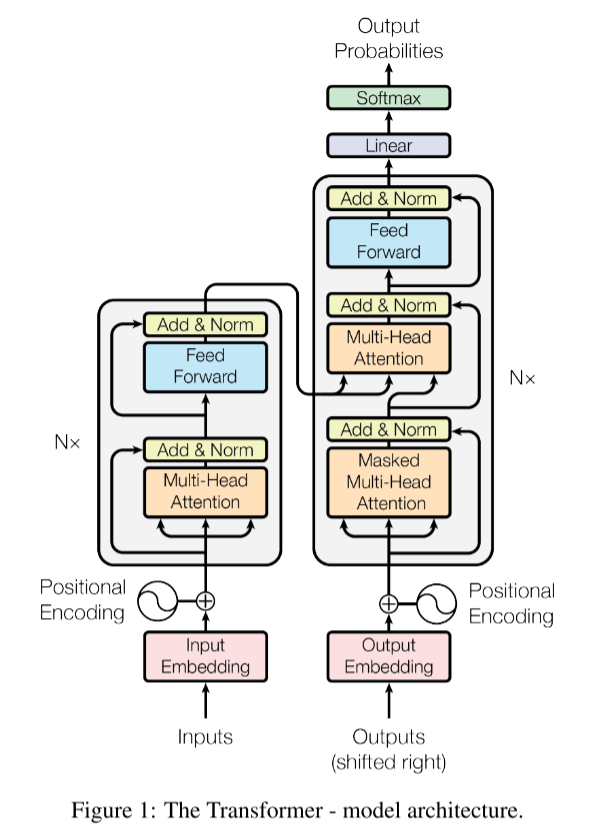
Encoder
编码器由N=6个层组成,每层由两个子层组成。第一个子层是多头注意力,第二个子层是FeedForward层(就是一个隐藏层的MLP)。每个子层都使用了残差链接和LayerNorm。
$$
LayerNorm(x + Sublayer(x))
$$
Decoder
解码器同样由N=6个层组成,每层由三个子层组成。除了Encoder中的两个子层外,还有一个Masked Multi-Head Attention层。这里之所以要Mask是因为在训练时,t时刻需要保证Decoder无法看到t时刻以后的输入,保证训练和预测行为是一致的。
Attention
注意力简单来说由K(key) Q(query) V(value)三部分组成,对于每个query,根据query和每个key的相似度算对应value的加权和。
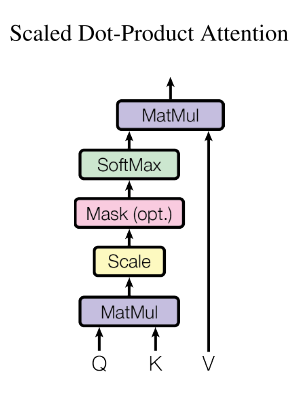
Scaled Dot-Product Attention
本篇论文中计算query和key的相似度采用内积的方法,根据内积的值来作为对应value的权重(加权前需要做一次softmax)。
实际应用中,做完内积后需要除以sqrt($d_k$)。主要原因是当$d_k$比较大时,做完内积后的值会比较大,那么不同内积值之间的绝对差距就会比较大,这会影响softmax的输出,即softmax的输出会向两边分散(0/1),那么反向传播的时候,就会难以训练。(因为softmax一般是跟1/0的label去比较)。所以需要÷$d_k$来缩小绝对差距。
mask操作也比较简单,在t时刻计算完内积后,将t+1时刻及往后的key对应的内积值换成很小的负数,那么之后做softmax并加权计算得到的value中那些“不应该出现的key-value”所占的比例就很小了。
$$
Attention(Q,K, V) = softmax(QK^T/sqrt(d_k))V
$$
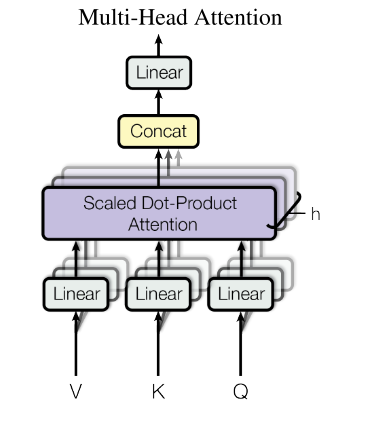
Multi-Head Attention
来自CNN多通道识别不同模式的灵感,做多头注意力。
具体操作是先把KQV映射到比较低的维度(具体维度大小就是$d_{model}/h$),分别做h次注意力机制,将结果concat起来并映射回原尺度。
$$
MultiHead(Q,K, V) = Concat(head1, ..., headh)W^O
\\where headi = Attention(QW^Q_i ,KW^K_i , VW^V_i )
$$

Applications of Attention in our Model
总共在三个部分用到了多头注意力机制。
- 第一个应用在Encoder中,KQV都是输入本身。
- 第二个是在Decoder中的Masked Multi-Head Attention,跟第一个相比多了一个Mask操作,KQV同样是输入本身。
- 第三个也在Decoder中,其K和V是来自Encoder的输出;Q则来自Masked Multi-Head Attention的输出。也就是把编码器的输出根据Mask注意力的输出(想要的东西)抽出来。
FeedForward
其实就是一个带有一个隐藏层的MLP,将MLP对于每个词都作用一次。这个的作用跟RNN中的MLP效果很像,就是把注意力抓取(aggregation)得到的信息(包括了序列信息)做一次投影,映射到更合适的语义空间,或者说利用MLP做语义转换
$$
FFN(x) = max(0, xW1 + b1)W2 + b2
$$

Embeddings and Softmax
Embedding就是把token映射到一个向量。编码器和解码器用的Embedding用的权重一致,方便训练。最后Embedding的结果乘了一个sqrt($d_{model}$),这是为了和之后的Positional Encoding做scale适配。
Positional Encoding
因为Attention机制只记录序列信息,而不记录时序信息。通过在输入加入位置编码信息,来增加时序信息。具体编码方式如下。
$$
PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}})
\\PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}})
$$
Why Self-Attention
本节介绍了为什么要用自注意力机制。主要总结了一下这张表。
从计算复杂度/序列计算复杂度/最大路径复杂度。
最大路径可以理解成获得任意两个点的关系最少需要的步数

Train
具体详见论文/源码。
-
使用Adam,β1=0.9,β2=0.98
-
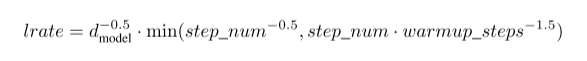
-
正则化手段
- Residual Dropout P=0.1
- Label Smoothing
Different Variations on the Transformer architecture
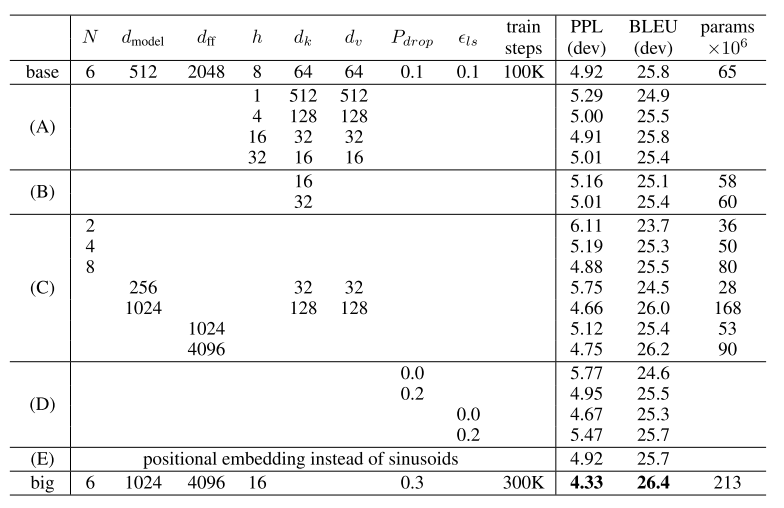
Conclusion
本篇论文提出了一个完全基于注意力机制的序列转译模型,用多头注意力代替了以往常用的RNN。对于机器翻译任务,Transformer有明显的训练速度和准确率优势。同时Transformer有可能应用在图片/视频等其他媒体,实现多模态的输入,
评论