
ALBEF paper : http://arxiv.org/abs/2107.07651
BLIP paper : http://arxiv.org/abs/2201.12086
BLIP code : https://github.com/salesforce/BLIP
ALBEF
网络结构如下,这篇算得上BLIP/BLIP2的前身了,其三个Loss一直延续至今(当然MLM变成了LM)。具体三个Loss的介绍可以看BLIP2 - JJJYmmm Blog,有以下几个特别点:
- ITC Loss采用了MOCO的形式,即通过一个momentum encoder来扩大负样本的数量,这也是多了一个momentum model的原因。论文还从模型蒸馏的角度对momentum model做了进一步改进,例如在计算ITC和MLM时引入了伪标签
- 这里对于文本理解任务,采用的是MLM而不是LM,可能是因为MLM任务相比于LM任务更简单,因为模型只需要预测被mask的单词即可
- 在计算ITC时得到的Image-Text Similarity可以挑选出hard negatives,专门去做ITM;这个方法在BLIP和BLIP2都用到
- 在这里三个Encoder都不共享参数,算是典型的双流模型

BLIP

网络结构如上,可以看到不同Encoder之间共享参数。loss则与ALBEF没什么区别。其他值得注意的点有:
- 对于单模态Encoder,无论是文本还是图片,都是采用self attention提取特征;对于Image-grounded Text Encoder,主要添加了一个cross attention层,KVs是Image Embedding;对于Image-grounded Text Decoder,替换了self attention层(其实就是mask改成casual mask吧~) ; 三个text相关的encoder/decoder都共用FFN;关于参数共享的细节,可以看消融实验
- 其实一直都有一个问题,为什么Image-grounded要让Image Embeddings作为cross attention的KVs呢?这样text作为query,cross attn的结果不就是通过text加权得到的image features?这样得到的特征应该更多与image有关而不是text有关吧(我能想到的一个原因是auto-regressive限制了decoder的input必须是text)
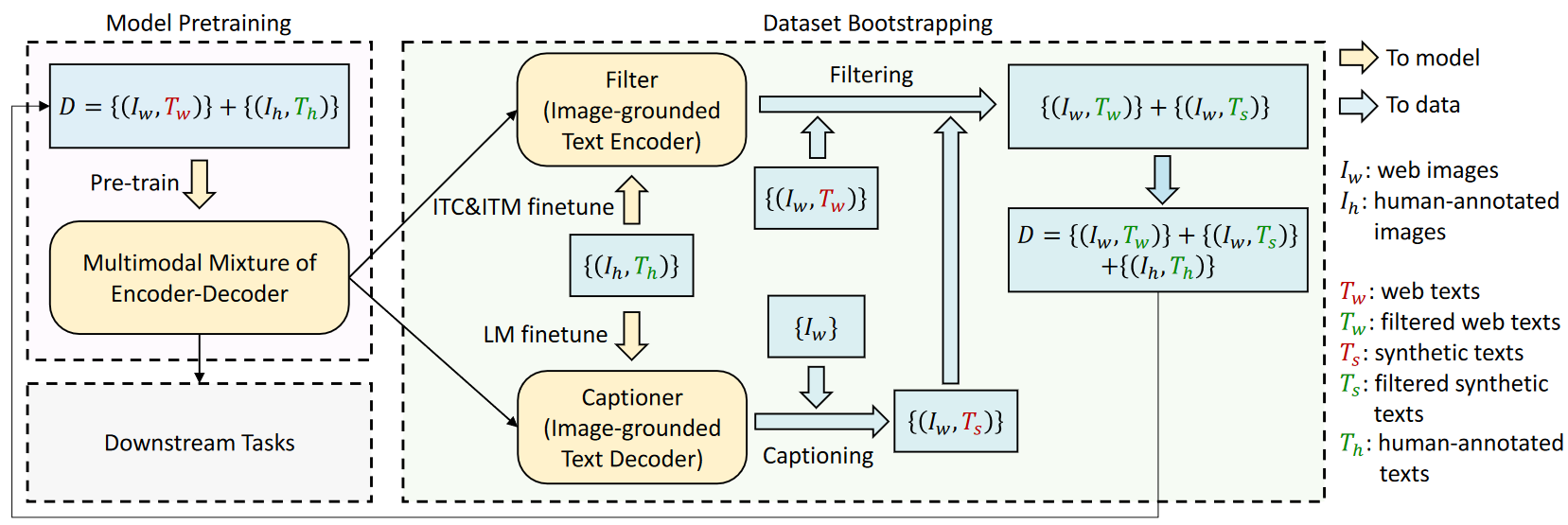
- BLIP的主要亮点是对数据集的处理,这里引入了半监督bootstrap的做法,具体看下面这张图就懂了~这里论文同样从模型蒸馏的角度来说明bootstrap的有效性,在后续的实验中也表明,每次对于清洗/扩充后的数据集,都应该从头对模型进行pre-train,这符合模型蒸馏中的学生模型不应该继承教师模型参数的常识。
评论
偶尔看到去年这篇博客,回复问题2:“这样得到的特征应该更多与image有关而不是text有关吧”这句话不一定准确,因为有residual connection存在,原本的text特征其实也完全保留了。不过最近确实有些工作使用一个长的self-attention来做特征融合(比如InteractDiffusion),至于两者怎么选我认为还是看实验结果吧。“auto-regressive限制了decoder的input必须是text”这一句也存在局限性,现在绝大多数GPT-arch做image generation不就用的自回归吗哈哈哈。
偶尔回头看看自己的博客也是一件好事。