
网络
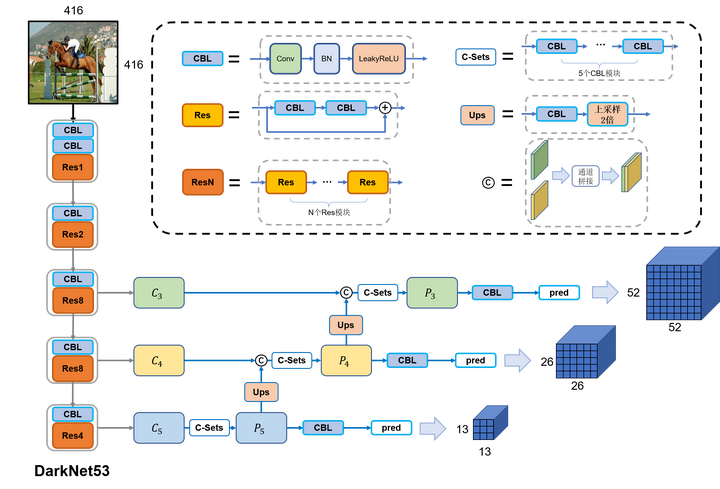
网络整体框图如下。
- 输入为416*416*3的图像,经过若干卷积三件套和ResN残差结构抽取图像特征。并通过控制卷积stride实现下采样,最终将图片下采样32倍
- 在下采样8倍/16倍/32倍产生的特征图上进行多尺度的预测,特征图大小分别为52x52、26x26、13x13。最终*通道数都是255 = (3(80+5))**
- 和SSD类似采用多级检测方法。在三个尺度上进行预测,尺寸越大的特征图负责检测小物体,尺寸越小的特征图负责检测大物体(related to 感受野)
- 负责预测的浅层特征图还使用了深层特征图的特征(也就是所谓的特征金字塔FPN),通过上采样和通道融合实现。这个好处是让浅层特征图预测小(或者说复杂)物体时更容易(因为深层特征图提取的大多是语义特征,容易区分复杂目标)
具体解读
主干网络backbone:DarkNet-53
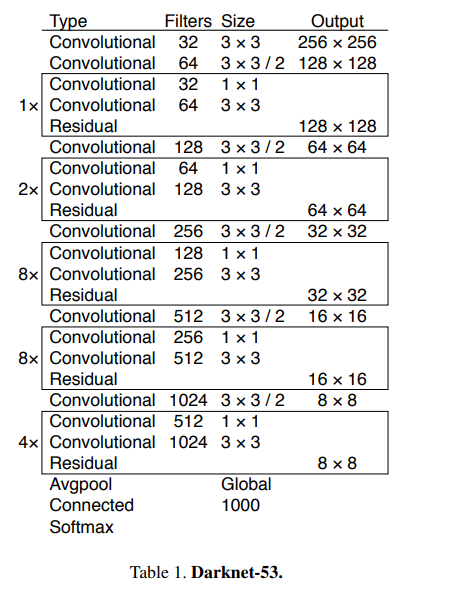
相较于YOLOv2中所使用的DarkNet19,新的网络使用了更多的卷积——52层卷积(外加一个全连接层),同时,添加了残差网络中的残差连结结构,以提升网络的性能。DarkNet53网络中的降采样操作没有使用Maxpooling层,而是由stride=2的卷积来实现。卷积层仍旧是线性卷积、BN层以及LeakyReLU激活函数的串联组合。
FPN与多级检测
FPN的最早是在2017年的CVPR会议上提出的,其创新点在于提出了一种自底向上(bottom-up)的结构,融合多个不同尺度的特征图去进行目标预测。FPN工作认为网络浅层的特征图包含更多的细节信息,但语义信息较少,而深层的特征图则恰恰相反。原因之一便是卷积神经网络的降采样操作,降采样对小目标的损害显著大于大目标,直观的理解便是小目标的像素少于大目标,也就越难以经得住降采样操作的取舍,而大目标具有更多的像素,也就更容易引起网络的“关注”,在YOLOv1+和YOLOv2+的工作中我们也发现了,相较于小目标,大目标的检测结果要好很多。
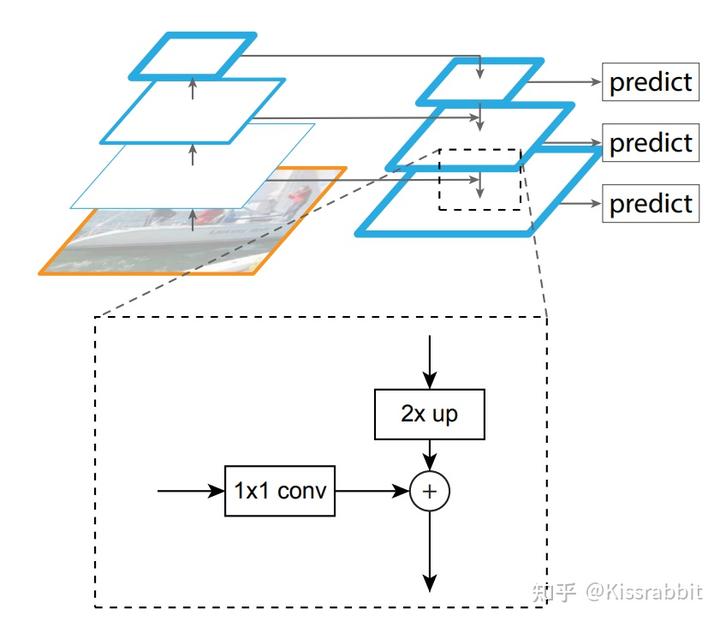
从网格的角度来看,越浅层的网格,划分出的网格也越精细,以416的输入尺寸为例,经过8倍降采样得到的特征图C3相当于是一个52x52的网格,这要比经过32倍降采样得到的特征图C5所划分13x13的网格精细得多,也就更容易去检测小物体。同时,更加精细的网格,也就更能避免先前所提到的“语义歧义”的问题。
多级检测方法最早可以追溯到SSD网络,SSD正是使用不同大小的特征图来检测不同尺度的目标,不过当时并没有结合FPN网络来做,这一方法的思想内核便是用不同尺度的物体由不同尺度的特征图去做检测,而不是像YOLOv2那样,都堆在最后的C5特征图上去做检测。而FPN正是在这个基础上,让不同尺度的特征图先融合一遍,再去做检测。
单级检测(single-level detection),比如早期的YOLOv1和YOLOv2,便是最为经典的单级检测工作。只不过,主流普遍认为这种只在C5特征图上去单级检测的检测器,小目标检测效果是不行的,尽管这一点被ECCV2020的DeTR和CVPR2021的YOLOF工作否决了,却依旧难以扭转这一根深蒂固的观念,前者似乎只被关注了Transformer这一点上,而后者似乎被认为是“开历史倒车”。
还有一类单级检测工作则另辟蹊径,借鉴人体关键点检测工作的思想,使用高分辨率的特征图如只经过4倍降采样得到的特征图C2来检测物体,典型的工作包括CornerNet和脍炙人口的CenterNet。以512的输入尺寸为例,只经过4倍降采样得到的特征图C2相当于是一个128×128的网格,要比C5的16×16精细的多,然后再将所有尺度的信息都融合到这一张特征图来,使得这样一张具有精细的网格的特征图既具备足够的细节信息,又具备足够的语义信息。不难想象,这样的网络只需要一张特征图便可以去检测所有的物体。这一类工作具有典型的encoder和decoder的结构,通常encoder由常用的ResNet组成,decoder由简单的FPN结构或者反卷积(叫成转置卷积层比较好)组成,当然,也可以使用Hourglass网络。这一类的单级检测很轻松的得到了研究学者们的认可,毕竟,相较于在粗糙的C5上做检测,直观上便很认同分辨率高得多的C2特征图检测方式。只不过,C2特征图的尺寸太大,会带来很大的计算量,但是,这类工作不需要诸如800×1333的输入尺寸,仅仅512×512的尺寸便可以达到与之相当的性能。
YOLOv3训练/检测时,在每个网格处放置3个先验框。由于YOLOv3一共使用3个尺度,因此,YOLOv3一共设定了9个先验框,这9个先验框仍旧是使用kmeans聚类的方法获得的。在COCO上,这9个先验框的宽高分别是(10, 13)、(16, 30)、(33, 23)、(30, 61)、(62, 45)、(59, 119)、(116, 90)、(156, 198)、(373, 326)。注意,YOLOv3的先验框尺寸不同于YOLOv2,后者是除以了32,而前者是在原图尺寸上获得的,没有除以32。
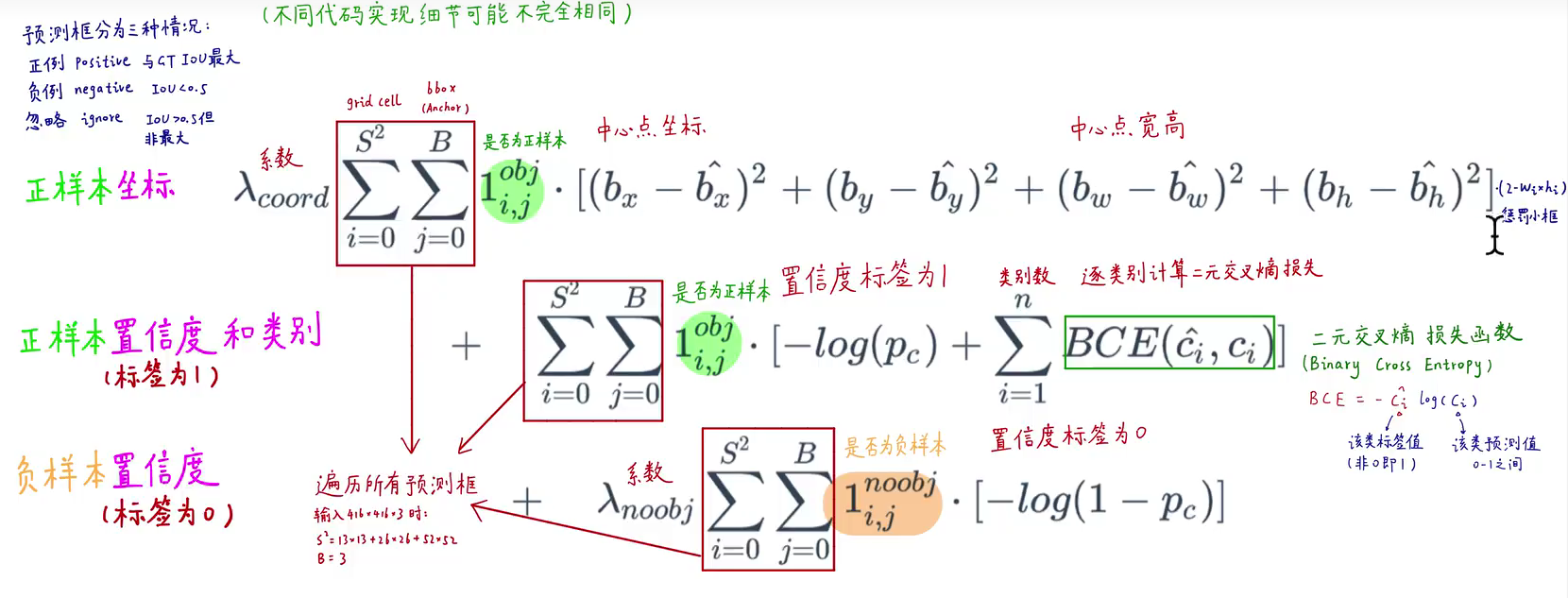
损失函数
损失函数较之前没有大的改动,比较重要的一点是类别预测不再使用softmax进行预测,因为softmax处理后各类别概率是互斥的。而实际上有些标签是可以共存的(比如"max"和"woman"),所以作者抛弃了softmax,改用sigmod对每个类别进行单独预测。损失也使用BCE对各个类别单独计算。
置信度objectness也使用交叉熵函数(之前当成回归问题处理)

当然,作者也只是说softmax不会表现更好,所以代码里还是用的softmax加MSE
Q&A
这一栏是问题与知乎大佬的回复
- Q1
- Q:多尺度训练中的先验框设置这方面一直不是很懂,无论除不除32(下采样倍数)都是相较于数据集中固定大小的图片的尺度。那采用多尺度训练的时候,先验框大小是否需要进行对应的缩放呢? 比如先验框都是基于416x416的图片聚类得到的,多尺度训练时输入换成了608x608,先验框的尺度应该扩大到608/416倍吧
- A:不需要随之改变的。多尺度训练的一个作用就是在训练过程中,让一些原本较大的物体变小,让一些原本较小的物体变大,这个目的就是为了增加数据集里不同大小的物体的数量,相当于人,对数据集做了一次扩展,如果anchor box 也跟着变,那就和多尺度训练的目的背道而驰了。但多尺度训练是一个比较强的训练技巧,不是那种一加上就好使的。你可以使用我的强化版yolo v1项目,里面也实现了一整套的yolo ,训练更稳定一些
复现
代码与先前YOLOv1、YOLOv2差异不大,主要添加了残差结构、多级预测、FPN特征金字塔、backbone改进等一些trick;训练、测试以及评估(mAP)代码基本没有修改.
详见JJJYmmm‘s YOLOv3
预测效果
在小物体和密集物体预测上有所改进。主要原因如下:
- 多级预测使网络在浅层特征图上也进行预测,浅层特征图首先尺寸较大,每个grid cell都预测B个box(v3中B=3),box的数量相比于前代(v1里是98个box,v2里是845个box)有了数量级的提升(num = (52x52+26x26+13x13)*3 = 10647)。自然更容易捕捉到小物体,提升整体的召回率(recall)
- 在浅层特征图进行预测时,还使用了FPN特征金字塔,融合了深层特征图的语义信息。
- backbone使用了残差连接,起到了和FPN差不多效果(应该
- 损失函数里有惩罚小框项,在之前的YOLOv2中有提到


评估
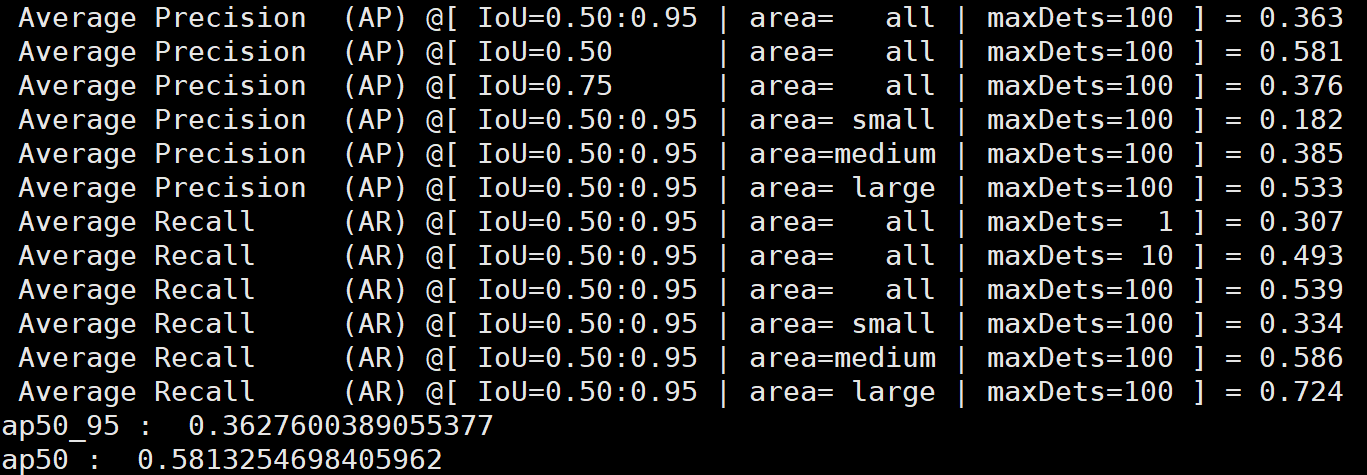
在输入图片大小为416x416情况下,AP50达到0.58,mAP@0.5:0.95达到0.36。与论文里的效果相差不大。
损失函数里的类别损失代码里使用的是SOFTMAX+MSE,并不是论文里提到的BCE。事实上,使用BCE,从mAP衡量的话其实效果是变差了的。当然,对于作者来说,mAP并不是好的评价指标,详情见yolov3论文最后一部分Rebuttal

附录
YOLO系列与RetinaNet的对比
目前来看,目标检测领域的baseline几乎已经被RetinaNet工作统治了,很多增量式的改进也都是在RetinaNet的基础上做的,往往Mask R-CNN和Faster R-CNN也会用上,毕竟是双阶段检测器的经典之作。之所以会采用RetinaNet作为baseline,一个原因是RetinaNet的网络十分简洁,训练起来也没有太tricky的东西。也许有人会说,YOLO也很简洁呀,确实,YOLO正因为其网络十分简洁,因而有着较好的泛化性,没有设计过多的trick来在COCO上刷性能(有可能过拟合)。但另一个很重要的原因便是RetinaNet的训练时间很短,通常只需要在COCO上训练12个epoch,数据增强也只需要使用随机水平翻转即可。相反,YOLOv3往往需要在COCO上训练超过200个epoch,并且使用包括随机水平翻转、颜色扰动、随机剪裁和多尺度训练在内等大量的数据增强手段。因此,就训练时间而言,YOLOv3往往会需要多得多的时间,这对于没有太多显卡的研究员来说并不友好。尤其是当今又是一个“拼手速”的时代,我们往往急于求成,快点拿到涨点的结果然后写到实验里,发出论文来,因此,训练耗时更少的RetinaNet显然是个更好的选择。不过,在解决实际问题时,YOLO系列更加受欢迎,毕竟在实际任务里,“实时性”是个很重要的指标,这一点恰恰是RetinaNet的劣势。YOLO性能强、速度快、计算量也要远小于RetinaNet,因此更适合用在实际部署中,无非是训练成本大了些。所以孰优孰劣,不能一概而论。
评论