MathJax的inline解析炸了...
突然发现MathJax的inline parse没用了?不知道是不是和更新的主题有关,大家看到$JJJY_{mmm}$就先自我脑补下标吧...
突然发现MathJax的inline parse没用了?不知道是不是和更新的主题有关,大家看到$JJJY_{mmm}$就先自我脑补下标吧...
这两天在看PyTorch DistributedDataParallel(DDP)相关文章,发现有个系列写的还不错。
虽然讲的是torch.distributed.launch(快被torchrun替代),但是整个思路应该还是有参考意义的。
看的过程中遇到一些问题,顺便补几个知识点。
补充SyncBN里的一个问题:2.1.5 eval部分,在torch 1.13版本里,只要满足eval模式或track_running_stats=True,就会使用统计量(
running_mean, running_var)进行计算了。源码如下:# torch.nn.modules.batchnorm return F.batch_norm( input, # If buffers are not to be tracked, ensure that they won't be updated self.running_mean if not self.training or self.track_running_stats else None, self.running_var if not self.training or self.track_running_stats else None, self.weight, self.bias, bn_training, exponential_average_factor, self.eps,)
Typecho使用Markdown语法解析文档,而Markdown默认图片靠左显示,且没有比较方便的居中方案(现在常用的方法是利用html语法解析,如使用img和div标签来设置居中)。
如果使用内嵌html来设置居中,对JJJYmmm来说工作量太大。换个角度思考,可以修改网页渲染的css文件。(如果使用了主题,则在主题对应的css文件修改)
使用以下代码,就可以实现所有文章的图片一键居中了~
.your_class #your_id img {
max-width:100%;
margin:0 auto;
display:block;
}后来发现,这个方案已经有人提出:https://zhuanlan.zhihu.com/p/474859854
最近写的一个Multi-task框架~
项目地址:https://github.com/JJJYmmm/Pix2SeqV2-Pytorch
Simple PyTorch implementation of Pix2SeqV2. This project references moein-shariatnia's Pix2Seq and the paper A Unified Sequence Interface for Vision Tasks.

Pix2Seq is a generalized framework for solving visual tasks proposed by Google. Essentially it treats visual tasks as language tasks, generating sequences of tokens by auto-regression, and obtaining the output of many visual tasks(e.g., object detection, segmentation, captioning, keypoint, etc.) by decoding the tokens.
The official implementation of Pix2Seq google-research/pix2seq: Pix2Seq codebase is written in TensorFlow. I wish there was a PyTorch implementation. Then Shariatnia gave me a simple implementation of Pix2SeqV1(just for object detection, no multi-task training). I followed his project and added something new below:
Something notes:
If you have more questions about this project, feel free to issues and PRs!
I use anaconda to manage my python environment. You can clone my environment by doing this:
# change to root dir
cd Pix2SeqV2
# create a new python 3.8 env
conda create -n your_env_name python=3.8
# install essential packages
pip install -r ./requirements.txtIf you want to run the project, you need to have at least one GPU with more than 12G memory. Of course, the more GPUs the better!
I haven't written the code for multi-GPU training, but it's coming soon.
All configurations can be modified in CFG class in Pix2SeqV2/config.py. Most of my training configurations come from Shariatnia's tutorials.
I use relative paths for other configs like weights and other required files. The only thing you need to change is the path of the dataset.
To fetch VOC dataset, just
cd downloadandbash download_voc.shTo fetch COCO2017 dataset, download here
# For VOC dataset, you need to change the following two var
img_path = '../download/VOCdevkit/VOC2012/JPEGImages'
xml_path = '../download/VOCdevkit/VOC2012/Annotations'
# For COCO dataset, you need to change dir_root
dir_root = '/mnt/MSCOCO'I trained some weights for different tasks, you can fetch them here. Put them in folder Pix2SeqV2/weights, so that you don't need to change corresponding configs.
Before diving into the formal Train&Infer session, let me show a small demo for the multi-task processing.
I just trained the multi-task model weight for 2 epochs in 11 hours, including four tasks(instance segmentation, object detection, image captioning and keypoint detection). So the results are unsurprisingly poor, forgive me =v=. The weight can be download here.
I random choose a picture(No.6471) from COCO validation dataset for visualization.

Next, you can run the following code to get the results of the four tasks.
# mask sure you're in the root directory and set the right weight path(multi_task_weight_path) in CFG
cd infer
python infer_single_image_multi_task.py --image ../images/baseball.jpg > result.txtAfter that you can see three images(instance_segmentation.png, keypoint_detection.png, object_detection.png) and a txt file(result.txt) in the infer directory.
result.txt shows all the predictions,
skipping pos_embed...
skipping pos_embed...
<All keys matched successfully>
Captioning:
[['baseball', 'player', 'swinging', 'his', 'bat', 'at', 'home', 'plate', '.']]
[['batter', 'during', 'the', 'game', 'of', 'baseball', 'game', '.']]
[['baseball', 'players', 'are', 'playing', 'baseball', 'in', 'a', 'field', '.']]
Bounding boxes:
[[ 15.665796 134.68234 130.5483 191.906 ]
[262.4021 69.40819 90.07831 232.37599 ]
[ 0. 94.21238 15.665796 53.524773]
[ 96.60574 78.54657 44.38643 61.357697]
[206.26633 223.45518 28.720627 37.859024]
[259.79114 72.01914 75.71802 229.76505 ]
[ 97.911224 180.37425 137.07573 140.99214 ]
[ 0. 95.51784 19.582247 53.52481 ]]
Labels:
['person', 'person', 'person', 'person', 'baseball glove', 'person', 'person', 'person']
Keypoint list:
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 176, 125, 198, 117, 168, 145, 237, 157, 0, 0, 261, 167, 180, 184, 205, 183, 173, 208, 204, 210, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]Three images visualize the results of the different visual tasks.
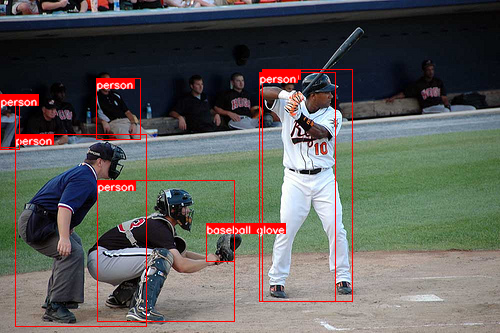


The low recall of object detection task may be due to poor data augmentation and not enough training epochs.
The segmentation task performed OK given the object detection box, as it was given the maximum training weight and I followed the settings of the original paper: repeat the prediction eight times to ensure recall.
The keypoint detection task performed very poorly, I think there are a few reasons for this: firstly it has the lowest weight in the multi-task training; secondly the bounding box I used in data augmentation seems to be too big (twice as big of a detection box, following the original paper's setup), resulting more than one person in the bbox.
Anyway, JJJymmm's pix2seqV2 has taken the first step !!!

For object detection, you can run the following code to train Pix2Seq from scratch. Hyperparameters such as training epochs, learning rate, etc. can be set in ./config.py. And the weights are saved in the directory ./train.
# mask sure you're in the root directory
cd train
python train_coco_object_detection.py # train on COCO2017
python train_voc_object_detection.py # train on VOCOnce the weights are obtained, you can run the code to infer a single image.
# mask sure you're in the root directory
cd infer
python infer_single_image_object_detection.py --image your_image_path # COCO2017
python infer_single_image_voc.py --image your_image_path # VOCThe predictions(bounding boxes and labels) are printed in terminal and the results of visualization are saved in object_detection.png.
Training and prediction for the other tasks did not differ much from this task.

Code for training.
# mask sure you're in the root directory
cd train
python train_coco_segmentation.pyCode for inference.
# mask sure you're in the root directory
cd infer
python infer_single_image_segmentation.py --image your_image_path --box selected_area(format:xywh)The results of visualization are saved in instance_segmentation.png.

Code for training.
# mask sure you're in the root directory
cd dataset
python build_captioning_vocab.py # generate vocab.pkl
# put the vocab.pkl to train folder or set the vocab_path in CFG
cd ../train
python train_coco_img_captioning.pyCode for inference.
# mask sure you're in the root directory
cd infer
python infer_single_image_caption.py --imageThe results are printed in terminal.

Code for training.
# mask sure you're in the root directory
cd train
python train_coco_segmentation.pyCode for inference.
# mask sure you're in the root directory
cd infer
python infer_single_image_segmentation.py --image your_image_path --box selected_area(format:xywh)The results of visualization are saved in keypoint_detection.png.
Code for training.
# mask sure you're in the root directory
cd train
python train_multi_task.py --task task1,task2,task3...
# supported tasks: detection,keypoint,segmentation,captioningCode for inference.
# mask sure you're in the root directory
cd infer
python infer_single_image_segmentation.py --image your_image_path --box selected_area(format:xywh)The text results are printed in terminal and the results of visualization are saved in object_detection.png, keypoint_detection.png, instance_segmentation.png.




@article{chen2021pix2seq,
title={Pix2seq: A language modeling framework for object detection},
author={Chen, Ting and Saxena, Saurabh and Li, Lala and Fleet, David J and Hinton, Geoffrey},
journal={arXiv preprint arXiv:2109.10852},
year={2021}
}@article{chen2022unified,
title={A Unified Sequence Interface for Vision Tasks},
author={Chen, Ting and Saxena, Saurabh and Li, Lala and Lin, Tsung-Yi and Fleet, David J. and Hinton, Geoffrey},
journal={arXiv preprint arXiv:2206.07669},
year={2022}
}坐上那飞机去拉萨(civi粉丝版)
pix2seq implement by Pytorch

source code : moein-shariatnia/Pix2Seq
paper : http://arxiv.org/abs/2109.10852
这次解析的源码是非官方实现的Pix2Seq,项目地址如上。教程直接看作者的Readme或者Object Detection w/ Transformers Pix2Seq in Pytorch | Towards AI,总体还是比较详细的。
模型即训练源码基本没什么问题,不过推荐先看完原始论文,不然可能在一些细节方面卡住。代码问题主要出现在测试文件中,问题如下。
2023.8.30
Tokenizer类的max_len参数用于限制单张图片的Obejct个数
labels = labels.astype('int')[:self.max_len]
bboxes = self.quantize(bboxes)[:self.max_len]而get_loaders中的collate_fn,把max_len作为输入序列的最大长度,这两处地方出现了矛盾(因为一个Object对应5个token,[x1, y1, x2, y2, class] )
if max_len: # [B,max_seq_len,dim] -> [B,max_len,dim]
pad = torch.ones(seq_batch.size(0), max_len -
seq_batch.size(1)).fill_(pad_idx).long()
seq_batch = torch.cat([seq_batch, pad], dim=1)2023.8.31
test.py中的postprocess函数存在问题,没有考虑model未检出object的情况。导致会将一个空序列(即\<EOS\>\<BOS\>)输入tokenizer的decoder方法,从而引发错误
for i, EOS_idx in enumerate(EOS_idxs.tolist()):
if EOS_idx == 0:
all_bboxes.append(None)
all_labels.append(None)
all_confs.append(None)
continue修正如下,考虑空序列的情况
for i, EOS_idx in enumerate(EOS_idxs.tolist()):
if EOS_idx == 0 or EOS_idx ==1: # invalid idx which EOS_idx = 0 or the model detect nothing when EOS_idx = 1
all_bboxes.append(None)
all_labels.append(None)
all_confs.append(None)
continue2023.8.31
test.py 中的第125行,发生类型判断错误。这里是剔除没有检测出物体的图片,但是此时lambda表达式中的x是array类型,所以isinstance函数参数不应该是list。否则过滤后preds_df会是空表
# preds_df = preds_df[preds_df['bbox'].map(lambda x: isinstance(x, list))].reset_index(drop=True)
# fix : list -> np.ndarray
preds_df = preds_df[preds_df['bbox'].map(lambda x: isinstance(x, np.ndarray))].reset_index(drop=True)2023.9.1 按道理这个很影响结果啊,毕竟图片之间的映射都错了。加上Issue 3,感觉作者写完教程,整理源码后,并没有再测试test.py这个文件了。
test.py第117行开始,保存预测结果。这里的原意应该是把预测结果对应回每张图片的id,但是源码直接对valid_df做了截断,这里很明显导致了部分图片的id被trunc了(这是因为valid_df将同一图片中的不同物体分成了若干行,如果直接按照总的图片数目进行截断,后面的一些图片id就会被截掉)。使用valid_df['id'].unique()进行修改,正好与133行代码对应。能这么做也是因为data loader的shuffle=False。
# preds_df = pd.DataFrame()
# valid_df = valid_df.iloc[:len(all_bboxes)]
# preds_df['id'] = valid_df['id'].copy()
# preds_df['bbox'] = all_bboxes
# preds_df['label'] = all_labels
# preds_df['conf'] = all_confs
# I think there is some bug above, because the code \
# do not consider the corresponding id of image, \
# it just trunc the valid_df with len(all_bboxes)!!!
preds_df = pd.DataFrame()
preds_df['id'] = valid_df['id'].unique().copy()
preds_df['bbox'] = all_bboxes
preds_df['label'] = all_labels
preds_df['conf'] = all_confs
# line_133 : valid_df = df[df['id'].isin(preds_df['id'].unique())].reset_index(drop=True)使用作者提供的权重文件,跑出来的结果确实比原作者给出的结果(mAP=0.264399)高出7%左右,而且由于上述逻辑错误,作者的结果其实只在基本一半数量的box做了mAP的计算(因为测试图片就少了快一半),如果使用全量数据,他的效果应该会更差。

2023.9.1
TODO : 之后把这些问题跟作者反馈一下,下一步考虑使用DDP,方便以后多卡训练。
https://github.com/moein-shariatnia/Pix2Seq/issues/6