作品说明
对AssaultCube 1.3.0.2进行攻击,实现透视、自瞄类的作弊功能。
实验环境
调试工具:x64dbg(使用32位版本x32dbg)、Cheat Engineer
开发工具:Visual Studio 2019
准备工作
1.定位玩家基地址和相关结构
1)首先通过CE附加到AssaultCube(以下统称AC),通过多次扫描得到玩家的位置/视角信息。
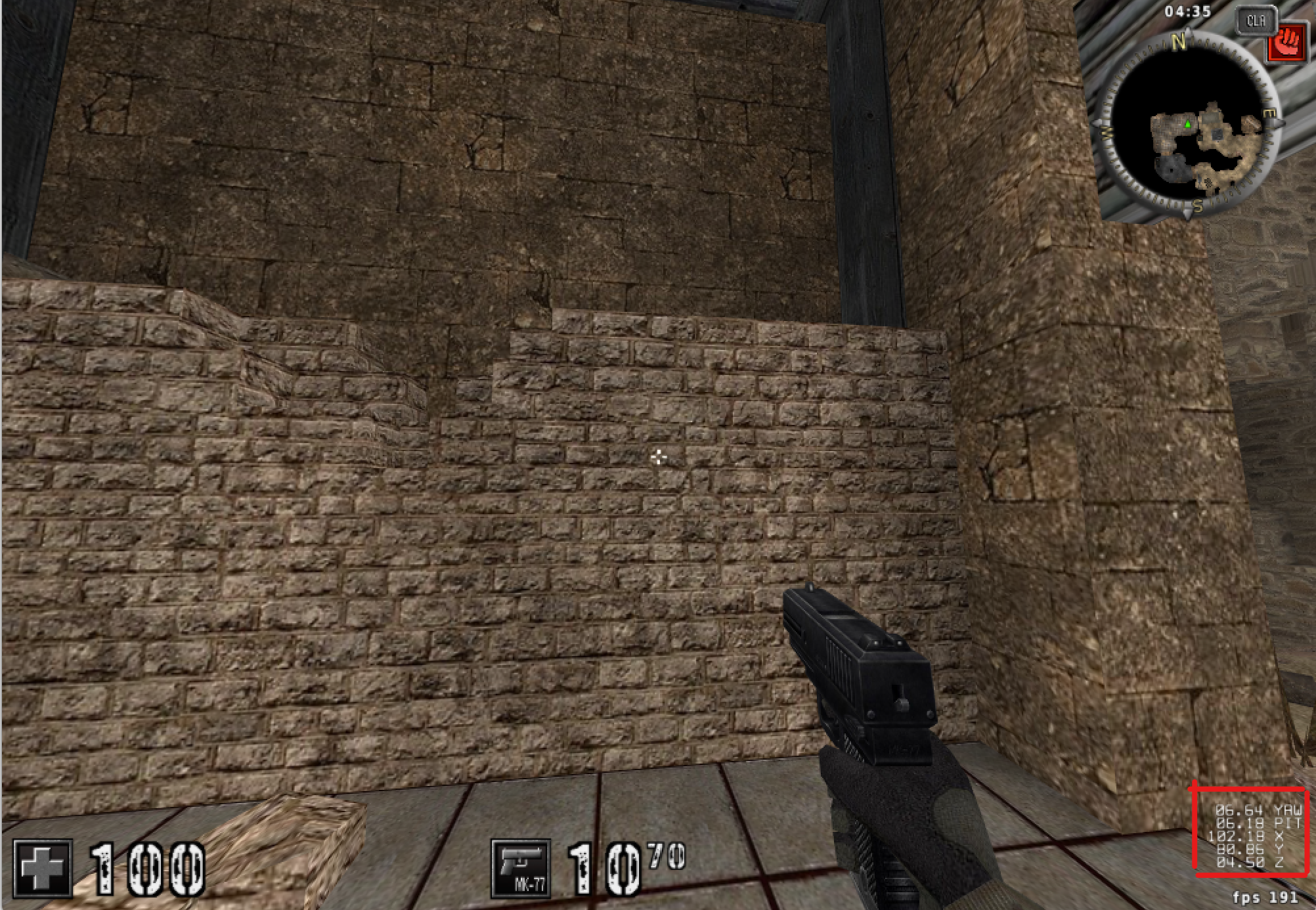
注1:可以在多次扫描中穿插扫描变化/不变的值,进一步缩小选择范围。或者使用AC自带的控制台功能(~),使用dbgpos 1得到玩家当前的位置信息和视角信息。如下图右下角所示。
注2:为了方便调试之后的内容(透视/自瞄),可以使用控制台 idlebots 1禁用机器人移动和射击。
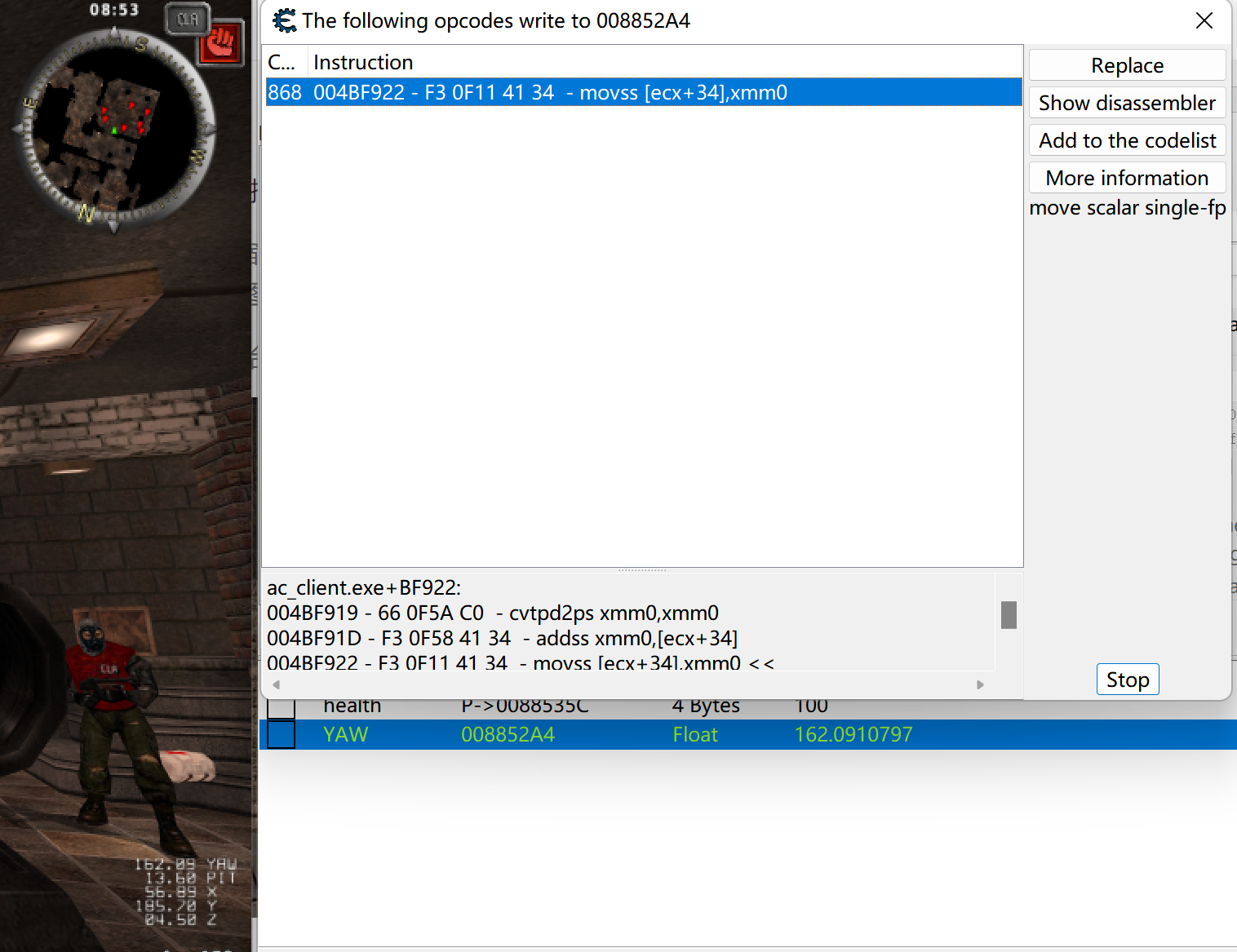
2)找到YAW信息后,查找是哪条指令向其写入数据,得到0x4BF922。使用x32dbg进行反汇编。
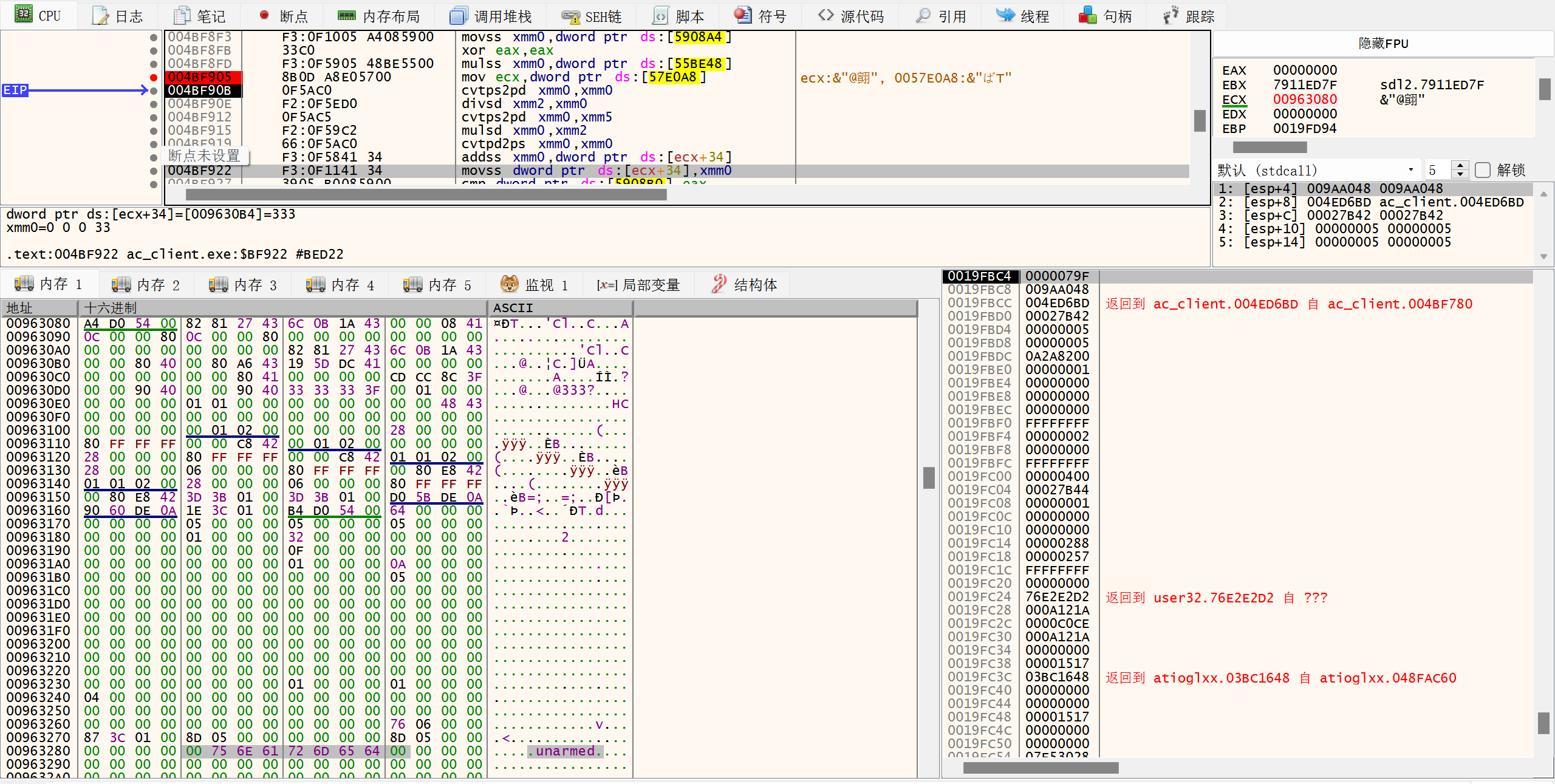
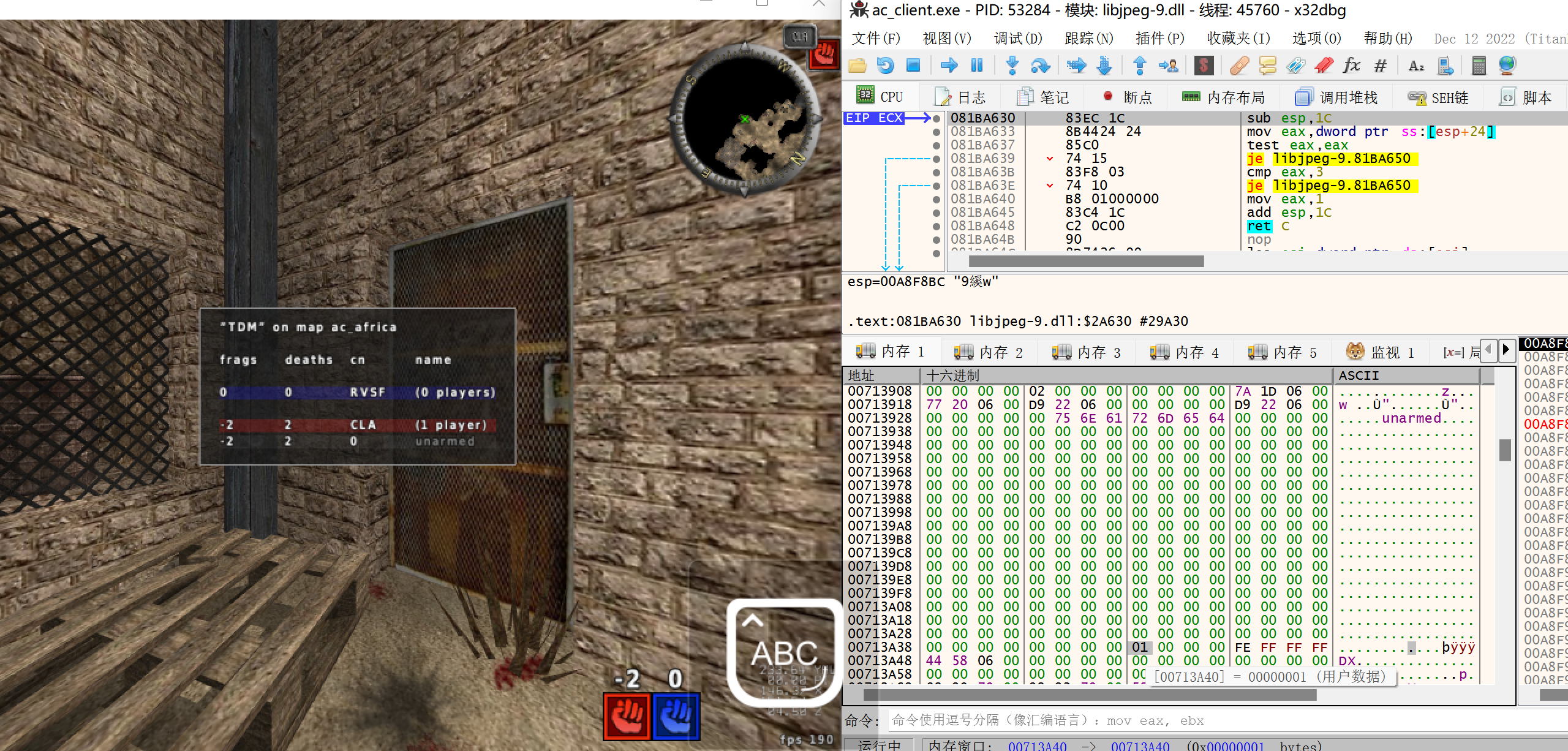
3)0x4BF922处的指令是movss,数据来源于ecx+34指向的地址,向上翻找汇编代码,可以看到ecx在0x4BF905被赋值(数据来源于数据段的指针0x57E0A8),打下断点,查看此时ecx的值为0x00963080。查看这块内存,可以看到这片内存中包含了玩家的名字unarmed,可以推测这片内存就是存放了玩家的结构信息。
4)我们知道游戏必须在内存中存储有关每个玩家的数据。此数据通常位于内存的连续部分中。在 C 或 C++ 中,这将表示为结构或类。例如,游戏可以定义玩家结构,如下所示:
struct Player {
float x;
float y;
float z;
float yaw;
float pitch;
char model_texture_path[128];
char name[128];
bool alive;
}
5)在 x64dbg 中查看时,我们可以将内存换成浮点数表示,可以直接看到玩家的坐标信息就在0x963084开头的3个32位浮点数中。
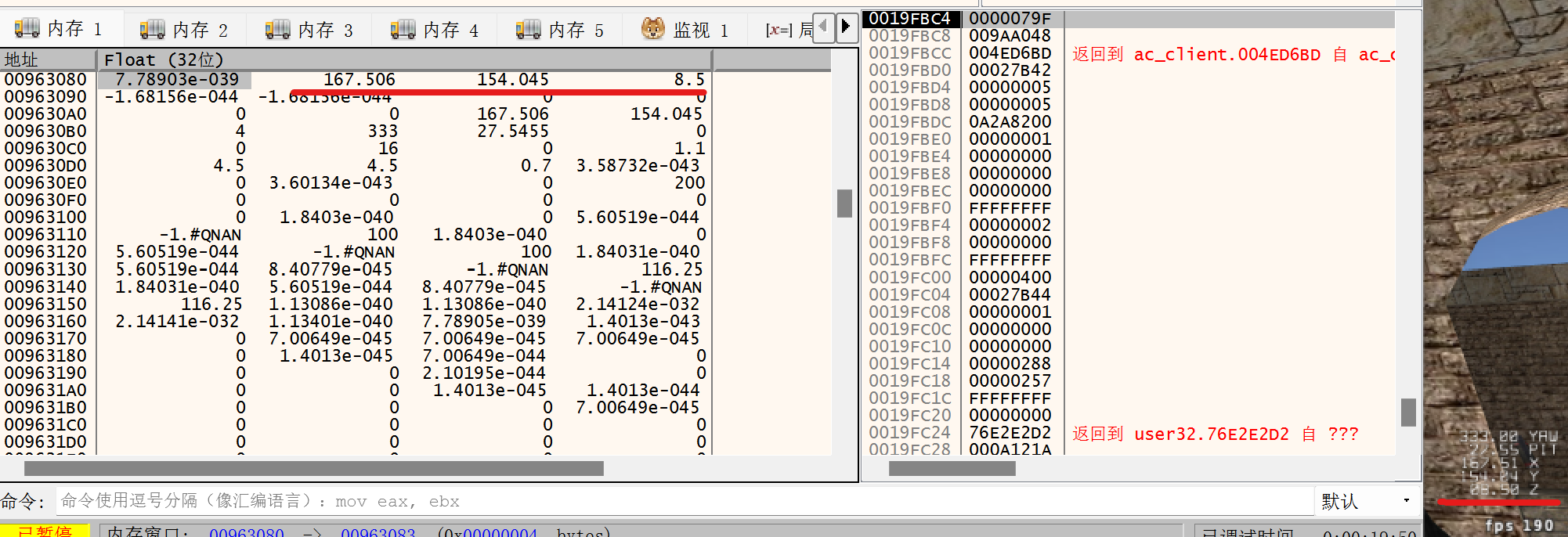
6)同时也可以找到偏仰角和偏转角的位置。
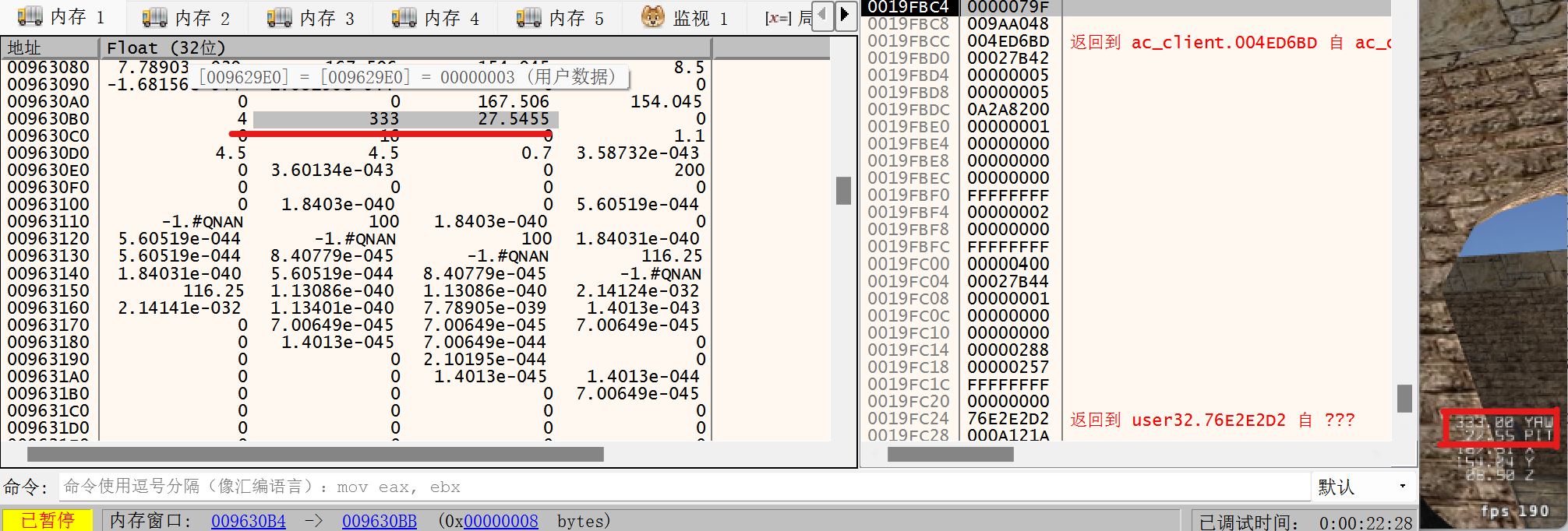
7)这个时候我们就找到了玩家自己的位置信息和视角信息相对于玩家基址的偏移量了。根据偏移信息重写player类结构。同时由3)知道指向玩家基地址的指针为0x57E0A8
struct Player {
char unknown[4];
float x;
float y;
float z;
char unknown[36];
float yaw;
float pitch;
}
2.定位敌方玩家列表
1)在游戏中定位敌方玩家,可以创建一个包含 8 个机器人的游戏。一般来说游戏会将敌人存储在内存某个列表中。那怎么获得列表的基地址呢?首先我们注意到当鼠标悬停在玩家上时,屏幕左下角将显示该玩家的名称。那么游戏必须有一段函数用于遍历游戏中的玩家并寻找其名称。通过这个信息获得敌方玩家所在!
2)使用CE查找字符串,查看真正改变玩家名字的内存。并在这个内存上打上访问断点,查看访问次数最多的指令0x481B02.
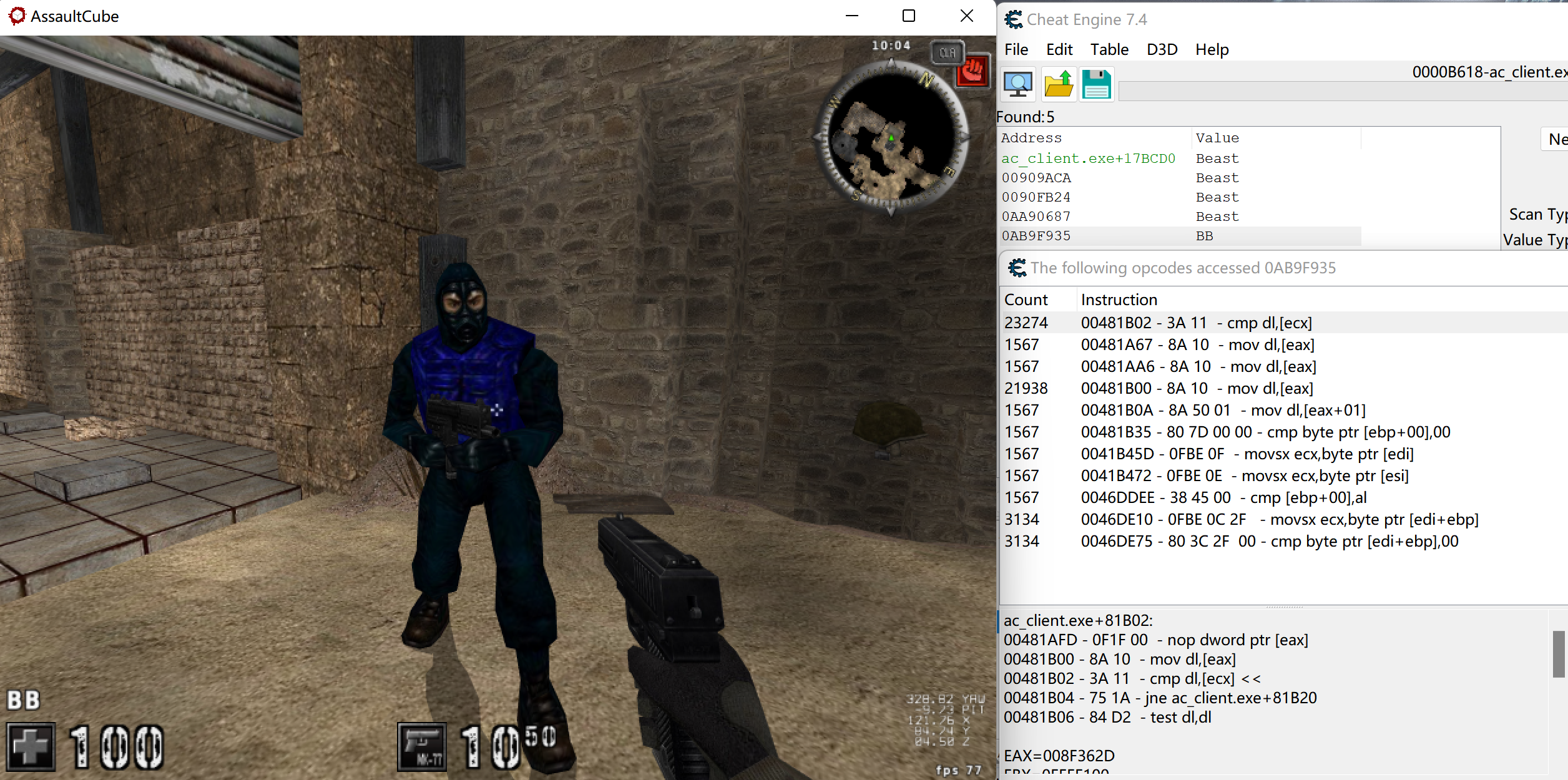
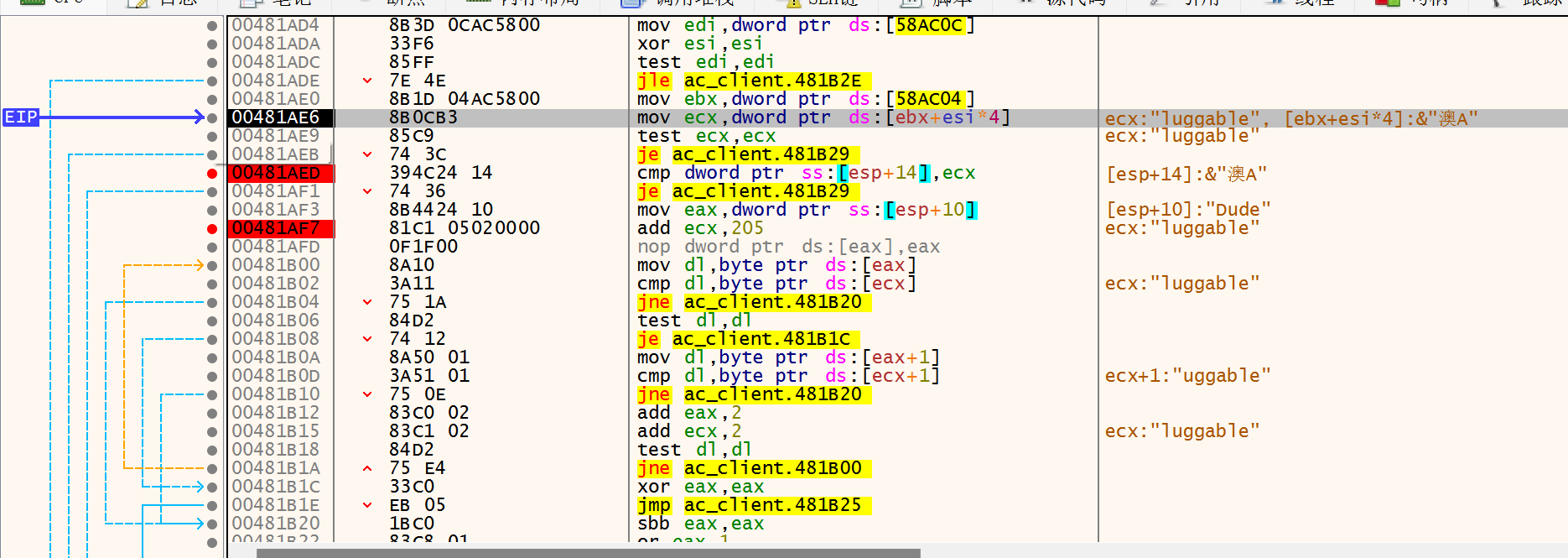
3)该语句在循环中,调试发现ecx先定位到每个玩家的基址,再通过0x481AF7的add ecx,205移到该玩家的名字字符串处。进行向上查找,很容易发现0x481AE6的语句,ebx+esi*4很像循环遍历元素,基本确定此时ebx的值就是玩家(机器人)链表基址。而基址存放在数据段0x58AC04的指针中(且第一个玩家在基址+4处),同时edi中存放了当前游戏总人数0x10,所以玩家人数应该是通过数据段0x58AC0C这个指针得到。且add ecx,205表示名字相对于基址的偏移是0x205.
3.获取玩家名字/存活状态/阵营
1)上节我们获得了玩家的名字相对于基地址的偏移0x205,那怎么获得名字的最大长度呢?比较简单的方法就是取名试试,在设置中我们发现最多给名字取15个字符,加上字符串尾部的'\0',名字字段分配16个字节即可。
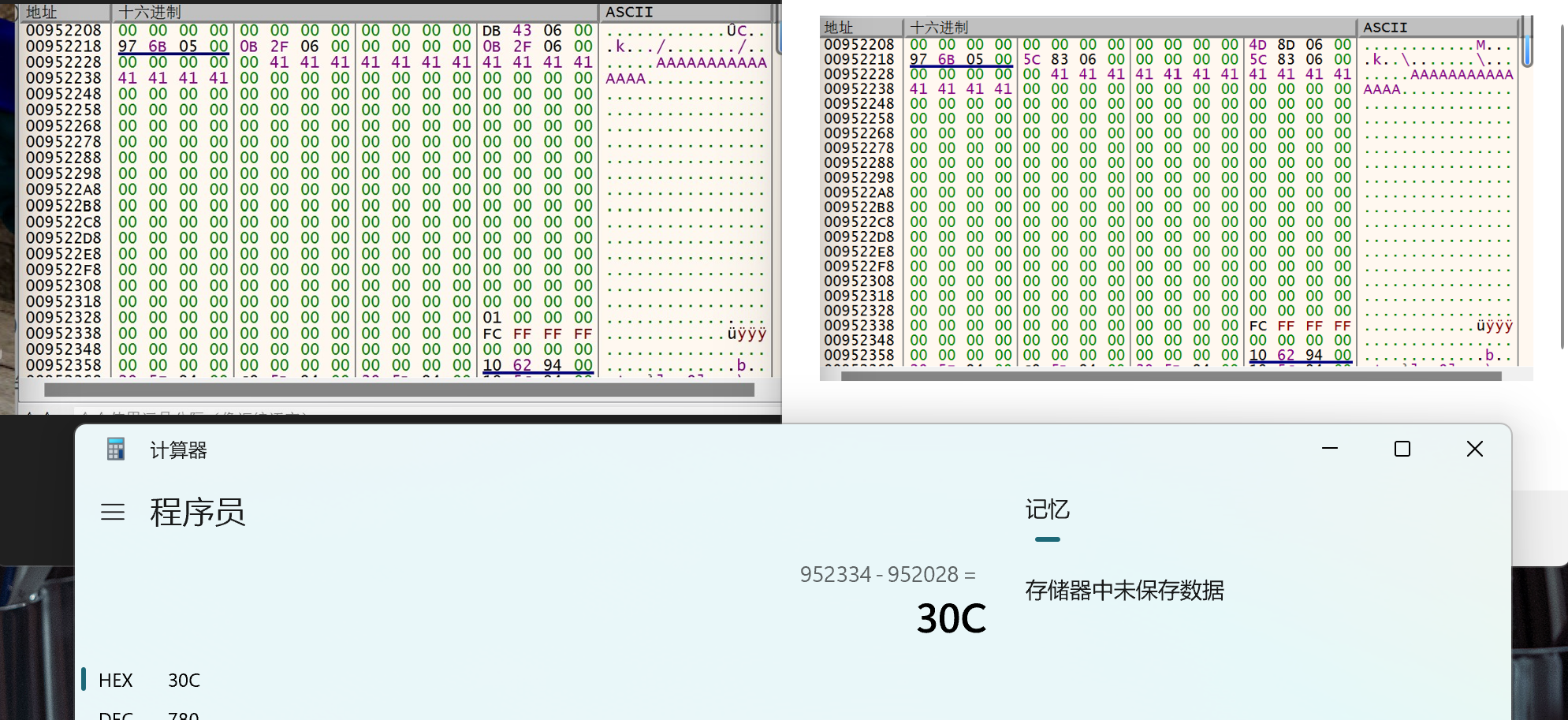
2)玩家多次自杀,查看内存变化,可以发现有一个字节在玩家死后从0->1,合理猜测这就是标志玩家是否死亡的字段,距离角色基地址的偏移为+318。
3)寻找玩家阵营字段,通过修改settings->game settings->change to the enemy team,观察角色内存变化,可以找到一个值在0/1来回变化,可以猜测它就表示阵营字段,其对于角色基地址的偏移为+30c。
准备工作总结
经过以上对玩家本身和其他玩家的逆向分析,我们得到了以下数据:
默认程序装载地址为0x400000,即ac_client.exe=0x400000
- 存放玩家自身基地址的指针0x57E0A8(ac_client.exe+0x17E0A8)
- 存放本局游戏玩家总数的指针0x58AC0C(ac_client.exe+0x18AC0C)
- 存放玩家列表基地址的指针0x基址存放在数据段0x58AC04的指针中(ac_client.exe+0x18AC04,且第一个玩家在基址+4处)
- 玩家的坐标(x,y,z),当前视角(yaw,pitch),存活状态(died),名字(named)和阵营信息(team)相对于基地址的偏移关系如下,通过struct结构来表示。unknown是我们不需要的填充字段。
struct Player {
char unknown1[4];
float x;
float y;
float z;
char unknown2[0x24];
float yaw;
float pitch;
char unknown3[0x1C9];
char name[16];
char unknown4[0xF7];
int team;
char unknown5[0x8];
int dead;
};
DLL/注射器模板
注射器模板
实现透视/自瞄两个功能都通过DLL注入来实现,这里采用的是远程线程注入方法,具体实现方法已经在作业二中详细说明,以下给出注射器关键代码。
代码模板参考 微软官方文档
#include <windows.h>
#include <tlhelp32.h>
#include<stdio.h>
// The full path to the DLL to be injected.
const char* dll_path = "C:\\YourDLLPath\\test.dll";
int main(int argc, char** argv) {
HANDLE snapshot = 0;
PROCESSENTRY32 pe32 = { 0 };
DWORD exitCode = 0;
pe32.dwSize = sizeof(PROCESSENTRY32);
snapshot = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
Process32First(snapshot, &pe32);
do {
// 确认进程名
if (wcscmp(pe32.szExeFile, L"ac_client.exe") == 0) {
printf("%d", pe32.th32ProcessID);//打印pid
//获得进程句柄
HANDLE process = OpenProcess(PROCESS_ALL_ACCESS, true, pe32.th32ProcessID);
// 创建内存存放dllPath
void* lpBaseAddress = VirtualAllocEx(process, NULL, strlen(dll_path) + 1, MEM_COMMIT, PAGE_READWRITE);
// 写入dllPath
WriteProcessMemory(process, lpBaseAddress, dll_path, strlen(dll_path) + 1, NULL);
// 远程线程注入
HMODULE kernel32base = GetModuleHandle(L"kernel32.dll");
HANDLE thread = CreateRemoteThread(process, NULL, 0, (LPTHREAD_START_ROUTINE)GetProcAddress(kernel32base, "LoadLibraryA"), lpBaseAddress, 0, NULL);
WaitForSingleObject(thread, INFINITE);
GetExitCodeThread(thread, &exitCode);
VirtualFreeEx(process, lpBaseAddress, 0, MEM_RELEASE);
CloseHandle(thread);
CloseHandle(process);
break;
}
} while (Process32Next(snapshot, &pe32));
return 0;
}
DLL模板
无论是自瞄或者透视,都需要实时获取所有玩家的信息,那么就需要一个永真循环包裹住外挂代码。其次因为是永真循环,需要创建子线程完成外挂功能,否则会导致游戏卡死。模板如下。
#include <Windows.h>
void injected_thread() {
while (true) {
//your cheat code
Sleep(1);
}
}
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved) {
if (fdwReason == DLL_PROCESS_ATTACH) {
CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)injected_thread, NULL, 0, NULL);
}
return true;
}
自瞄实现
实现自瞄主要是需要修改玩家的视角信息,即偏航角(yaw)和仰角(pitch)。
偏航角
获取偏航角,首先需要得到这两个玩家的相对距离,直接将对应的x,y坐标相减即可。再通过atan2f函数得到上图θ角的弧度制,稍加转换就可以得到其角度值。
需要注意的是,对于偏航角yaw。AssaultCube的初值就是90°,因此计算得到的yaw还需要+90才是正确的值
float abspos_x = enemy->x - player->x;
float abspos_y = enemy->y - player->y;
float azimuth_xy = atan2f(abspos_y, abspos_x);
float yaw = (float)(azimuth_xy * (180.0 / M_PI));
yaw = yaw + 90;
俯仰角
仰角同样也可以通过atan2f函数得到仰角的弧度制,稍加转换就可以得到其角度值。
float abspos_z = enemy->z - player->z;
float temp_distance = euclidean_distance(abspos_x, abspos_y);//计算斜边
float azimuth_z = atan2f(abspos_z, temp_distance);
pitch = (float)(azimuth_z * (180.0 / M_PI));
确定自瞄目标
以上都是对于单个敌人计算的。在多人对战里面,需要需要遍历所有敌人,确定自瞄的目标。如何确定目标呢,我们可以先暂时认为距离最近的敌人就是我们下一个需要自瞄的目标。遍历代码如下。
注1:这个判断逻辑其实是有瑕疵的,比如距离我们最近的敌人在一堵墙后面,我们就没办法杀死对方。更好的方法是,寻找距离屏幕的十字准星最近的敌人,这涉及到视角矩阵方面的知识,刚好透视也需要用到。到时候再对自瞄敌人选择算法进行改良。整个代码框架是基本一致的。改良见自瞄选择优化
注2:这里遍历的i从1开始,原因在准备工作2中提到过。玩家列表的基地址+4的内容才是第一个玩家的基址
DWORD* player_offset = (DWORD*)(0x57E0A8);
player = (Player*)(*player_offset); //获得玩家基地址
int* current_players = (int*)(0x58AC0C); //获得当前玩家人数
for (int i = 1; i < *current_players; i++) {
DWORD* enemy_list = (DWORD*)(0x50F4F8); //存放玩家列表的指针
DWORD* enemy_offset = (DWORD*)(*enemy_list + (i*4));
Player* enemy = (Player*)(*enemy_offset);
if(enemy->team == player->team) continue; //同阵营是队友
float temp_distance = euclidean_distance(abspos_x, abspos_y);
if (closest_player == -1.0f || temp_distance < closest_player) {
closest_player = temp_distance;
...
closest_yaw = yaw + 90;
...
closest_pitch = (float)(azimuth_z * (180.0 / M_PI));
}
}
//迭代完成
player->yaw = closest_yaw;
player->pitch = closest_pitch;
Sleep(1);
自瞄效果
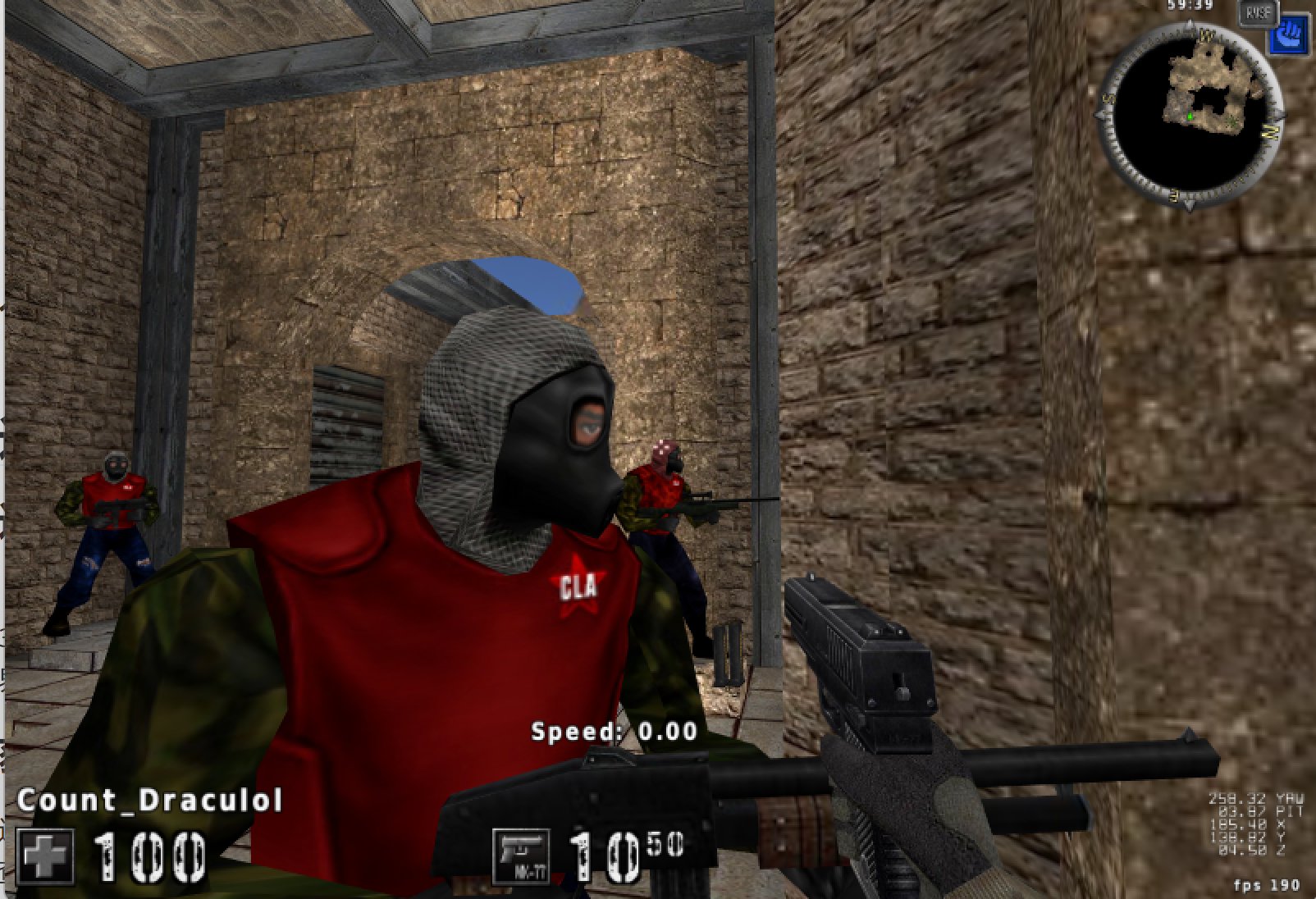
将以上代码填入DLL模板中,并使用注射器注入到游戏中(具体代码见上文),可以看到此时视角已经不能由鼠标控制,直接指向了最近的一个敌人的头部,杀死敌人后视角会转向另一个存活的最近的敌人,符合预期。杀死敌人前后视角的转换见以下两图。我们已经实现了自瞄功能!
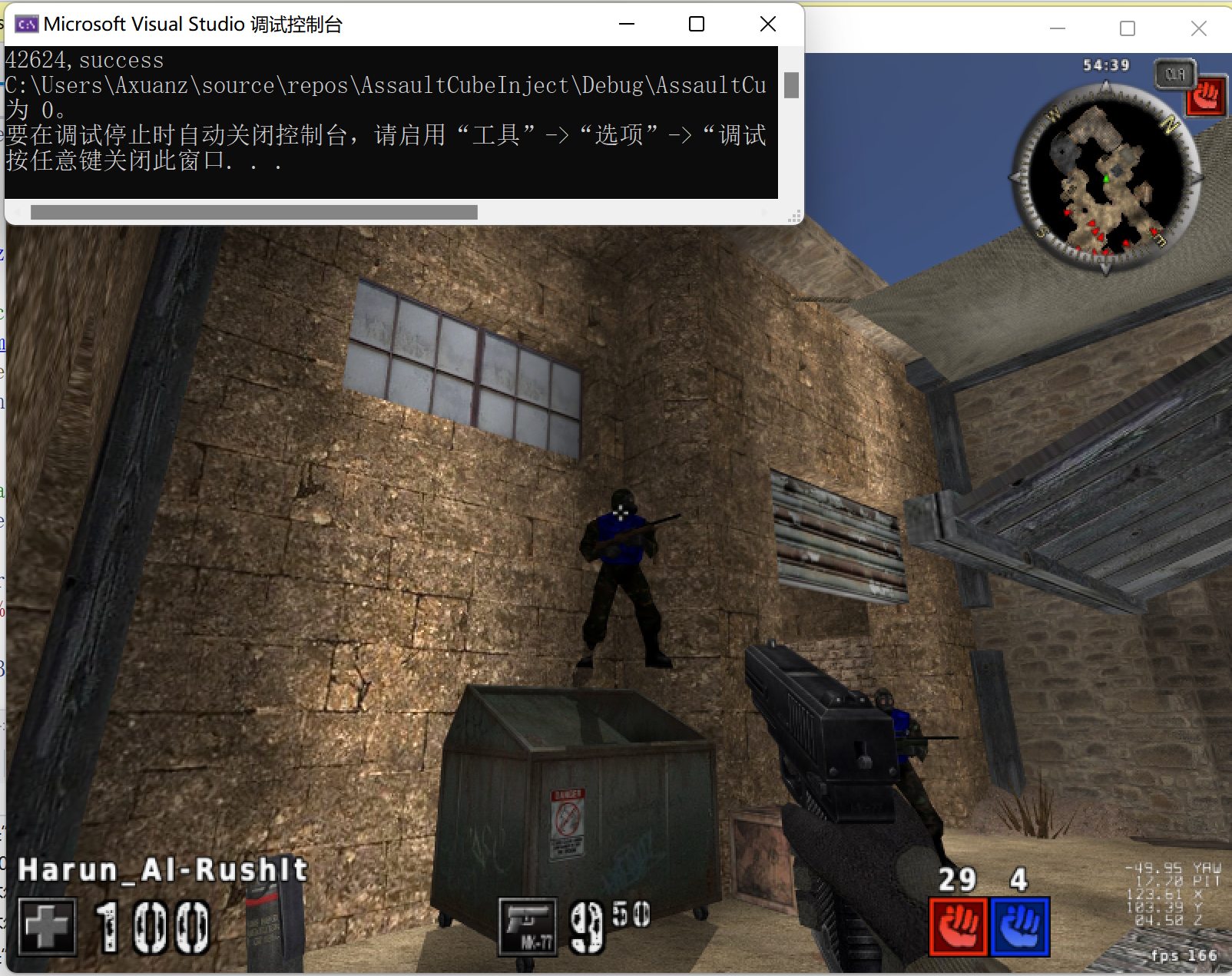
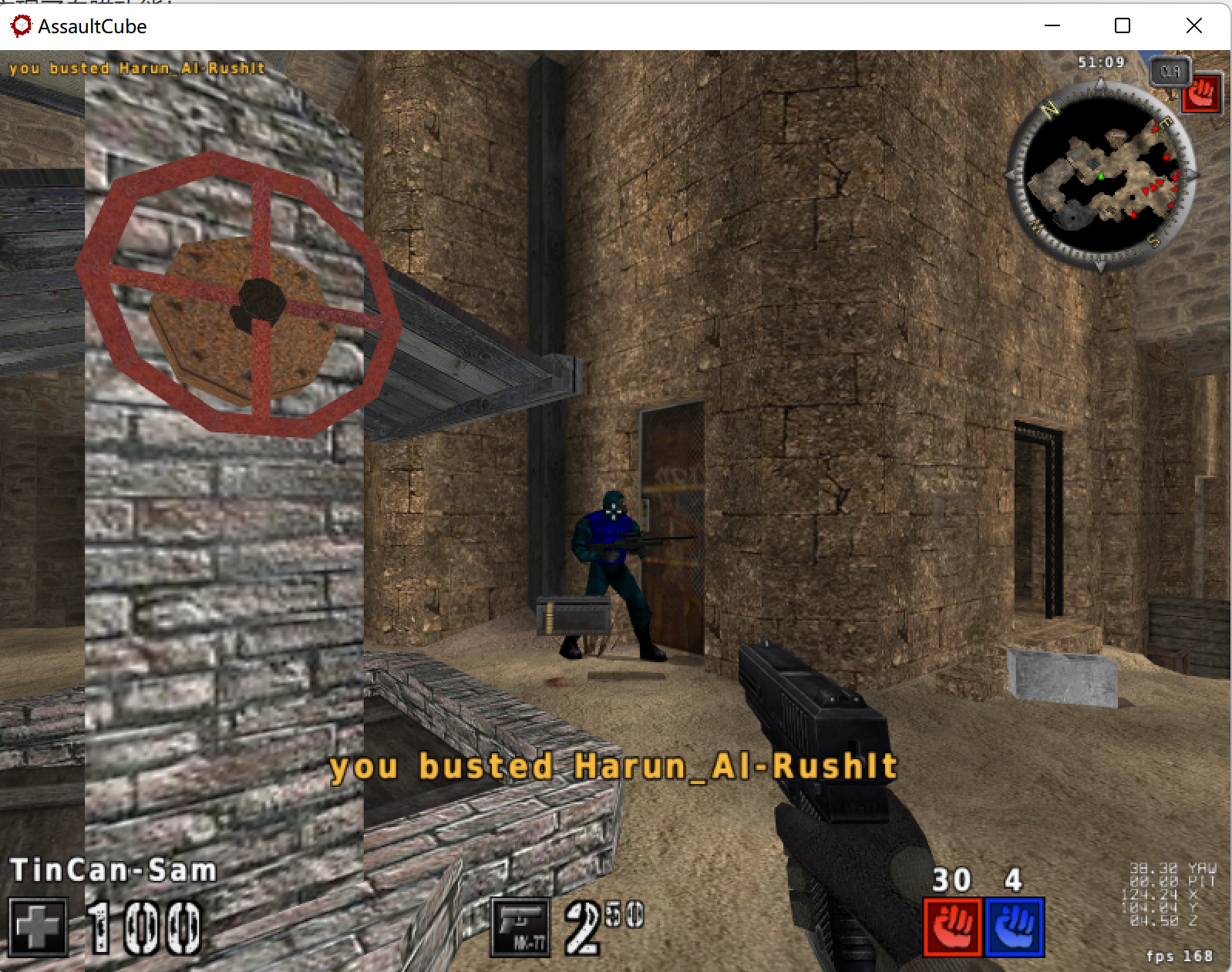
注:在之后完成透视功能的实现后,将对自瞄选择算法进行优化。并且将实现自瞄和透视两个功能的整合,并通过快捷键实现功能的开启/关闭
自瞄优化
之前自瞄选择算法的思想是选出距离最近的敌人,我们将改良为选择距离十字准星最近的敌人。视角矩阵转换算法在此处中已经提到,我们可以利用WorldToScreen算法中screenW是否为正数来判断敌人是否在视场范围内,如果不在视角范围内就不考虑这个敌人(如果当前视场没有敌人,用户可以移动鼠标直到视场出现其他敌人,恢复自瞄功能,这一点考虑是为了优化用户体验)。
在视场中的敌人,将继续计算得到他们在屏幕上的坐标,通过这个坐标和准星坐标(默认在屏幕中心)计算敌人和准星之间的距离。最后同样是遍历所有敌人,找到在视场中并且离准星最近的敌人作为自瞄目标。
判断代码如下。外面再套一层循环遍历敌人即可。
bool Seen(ViewMatrix* view,Player *enemy,int width, int height,float &dis) {
//得到相机xyw
float screenX = (view->m11 * enemy->x) + (view->m21 * enemy->y) + (view->m31 * enemy->z) + view->m41;
float screenY = (view->m12 * enemy->x) + (view->m22 * enemy->y) + (view->m32 * enemy->z) + view->m42;
float screenW = (view->m14 * enemy->x) + (view->m24 * enemy->y) + (view->m34 * enemy->z) + view->m44;
if (screenW <= 0.001f) { //敌人不在视场范围内
return false;
}
//准心在屏幕的位置
float camX = width / 2.0f;
float camY = height / 2.0f;
//计算敌人坐标和准星坐标的差值
float deltax = (camX * screenX / screenW);
float deltay = (camY * screenY / screenW);
dis = euclidean_distance(deltax, deltay); //计算敌人和准星的距离
return true;
}
优化后自瞄效果如下。开启自瞄功能后,我们将优先射击距离准星最近的敌人,而不是直线距离最近的敌人。这很好的控制了视角的稳定,既保护了眼镜,也减少了开挂被发现的风险(人物模型基本不会抽搐旋转)。
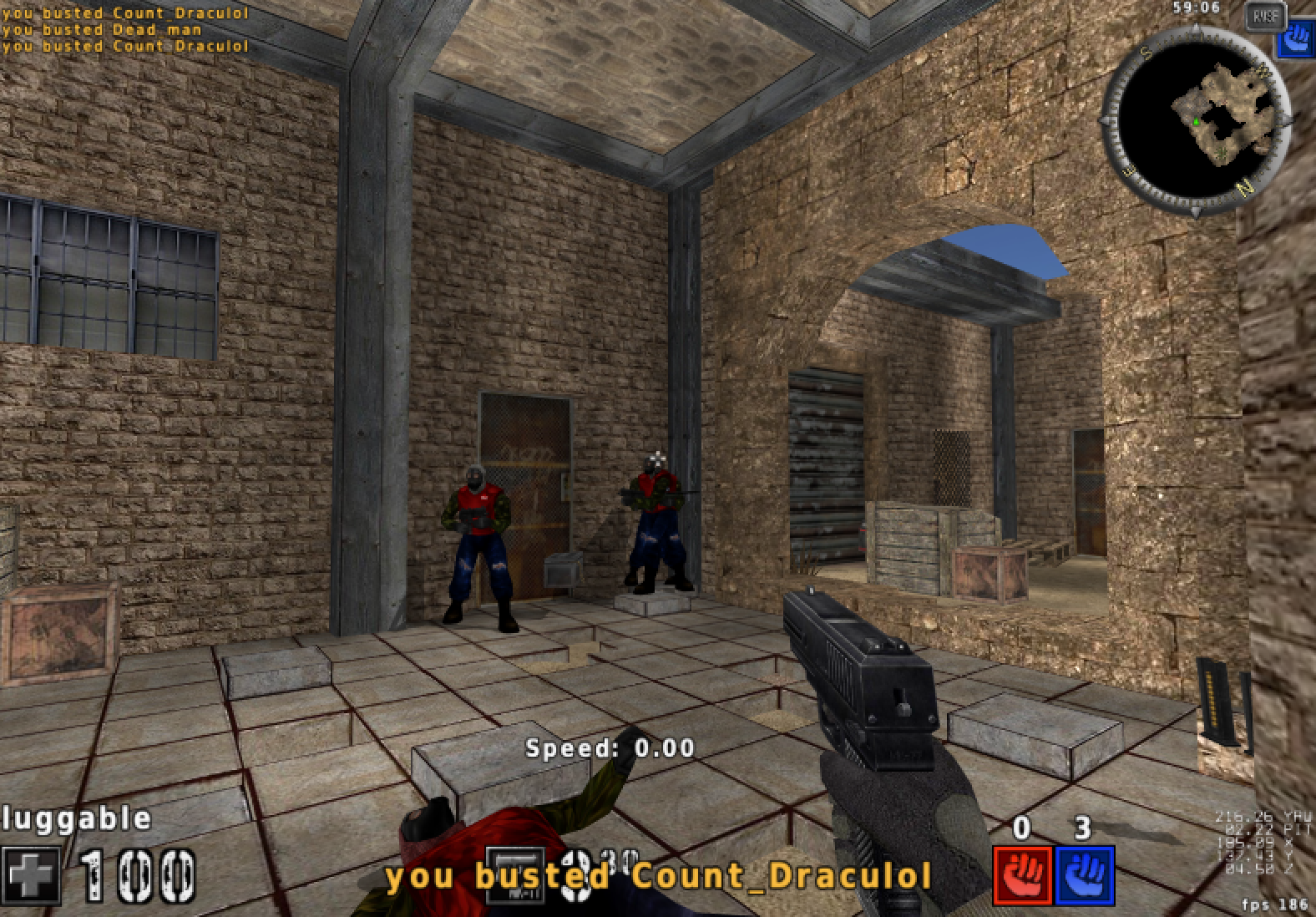
透视实现
透视原理
透视原理需要用到投影方面的知识,简单来说就是游戏是3D的,需要通过2D屏幕来反馈信息,这就涉及到了3D->2D的算法,一般来说FPS游戏使用视角矩阵来描述玩家视角的信息,通过对这个矩阵进行计算可以得到3D世界中的某个点在屏幕上的横纵坐标。
获取视角矩阵
通过CE先查找初始值未知的值,再逐遍扫描变化的值。在这期间可以移动、打开狙击枪扫描镜使视角变化,缩小查找范围,最后找到了一块变动的4*4矩阵区域,最后一行数值很大,其他数值不超过2,开镜、跳跃时的数值特征与视角矩阵一致。可以猜测这就是视角矩阵,基址为0x57DFD0.
根据视角矩阵的特征可以更快定位,对于横矩阵,最后一行的数值(Float表示)会非常大,而前几行一般在-2~2之间。纵矩阵则是最后一列的数值会非常大。除此之外矩阵中第三行第一列(或者第一行第三列)一般是定值0.0。根据这几个特征就可以更快找到视角矩阵的内存位置。

WorldToScreen转换
我们得到的视角矩阵是4*4的横矩阵,所以采用横矩阵的算法(伪代码)如下。其中Pos是敌人的坐标信息,width和height分别是屏幕的宽和高。算法返回值x和y是敌人在屏幕上的二维坐标,screenW则是判断敌人是否在视角范围内(如果screenW>0,则Pos在视角范围内)
屏幕宽度width在0x591ED8处
屏幕高度height在0x591EDC处
struct ViewMatrix{
//视角矩阵 X, Y, Z, W
float m11, m12, m13, m14; //00, 01, 02, 03
float m21, m22, m23, m24; //04, 05, 06, 07
float m31, m32, m33, m34; //08, 09, 10, 11
float m41, m42, m43, m44; //12, 13, 14, 15
}
Vector3 WorldToScreen(Vector3 Pos, int width, int height){
//得到相机xyw
float screenX = (m11 * Pos.x) + (m21 * Pos.y) + (m31 * Pos.z) + m41;
float screenY = (m12 * Pos.x) + (m22 * Pos.y) + (m32 * Pos.z) + m42;
float screenW = (m14 * Pos.x) + (m24 * Pos.y) + (m34 * Pos.z) + m44;
//准心在屏幕的位置
float camX = width / 2f;
float camY = height / 2f;
//转换成敌人在屏幕的坐标
float x = camX + (camX * screenX / screenW);
float y = camY - (camY * screenY / screenW);
return x,y,screenW;
}
绘制方框
我们找到了视角矩阵,在之前的准备工作中也知道了敌人的位置坐标,经过横矩阵转换算法可以得到敌人在屏幕中的二维坐标,现在需要将敌人的位置绘制出来。这里采用基于透明窗口的方框绘制,使用的图形库是GDI。
首先是透明窗口的构建,关键代码如下。流程是先获取游戏的窗口句柄window,根据窗口句柄获得窗口大小和位置(GetClientRect and ClientToScreen)。根据这些参数通过CreateWindowEx创建新窗口,新窗口大小位置和游戏窗口一致,且需要配置成透明(config中设置)。
Window = FindWindowA("SDL_app", "AssaultCube");
GetClientRect(Window, &rc);
WNDCLASSEX wincl;
//.....some confing
RegisterClassEx(&wincl);
POINT point;
point.x = rc.left;
point.y = rc.top;
ClientToScreen(Window, &point);
NewWindow = CreateWindowEx(
(WS_EX_TOPMOST|WS_EX_TRANSPARENT|WS_EX_LAYERED),
(L"lookaway"),
(L"lookaway"),
(WS_POPUP|WS_CLIPCHILDREN),
point.x,
point.y,
width,
height,
0,0,wincl.hInstance,0
);
窗口创建后,就利用GDI的API进行图形绘制。首先通过GetDC检索一指定窗口的客户区域或整个屏幕的显示 设备上下文环境的句柄,便于之后的画图。
hDC = GetDC(NewWindow);
COLORREF bkcolor = GetBkColor(hDC);
SetLayeredWindowAttributes(NewWindow, bkcolor, 0, LWA_COLORKEY);
ShowWindow(NewWindow, SW_SHOWNORMAL);
UpdateWindow(NewWindow);
接下来设置画图信号,每当接收到VM_PAINT信号后将执行Draw函数。VM_PAINT信号由UpdateWindow(NewWindow)发出
LRESULT CALLBACK WindowProcedure(HWND hwnd, UINT message, WPARAM wParam, LPARAM lParam)
{
switch (message)
{
case WM_DESTROY:
PostQuitMessage(0);
break;
case WM_LBUTTONDOWN:
break;
case WM_PAINT:
Draw(); //绘制方框
break;
default:
return DefWindowProc(hwnd, message, wParam, lParam);
}
return 0;
}
Draw函数实现如下,为了防止图像闪烁问题,这里采用双缓冲机制绘制。首先绘制方框,再绘制每个人的名字,其中敌人的边框和字体颜色为红色,友军的边框字体颜色为绿色。
为了方框可以自适应敌人大小,这里采用两个坐标绘制。除了敌人的头部坐标外,还有脚部坐标(敌人头部坐标z值减4.5)。
void Draw() {
HBITMAP hbitmap = CreateCompatibleBitmap(hDC, width, height);
HGDIOBJ oldbitmap = SelectObject(memDC, hbitmap);
BitBlt(memDC, 0, 0, width, height, 0, 0, 0, WHITENESS);
for (int i = 1; i < *current_players; i++) {
int offset = (val_yfoot[i] - val_yhead[i]) / 6;
//绘制边框
SelectObject(memDC, GetStockObject(DC_PEN));
is_enemy[i] ?SetDCPenColor(memDC, rgbRed) : SetDCPenColor(memDC, rgbGreen);
Rectangle(memDC, val_xhead[i]-2*offset, val_yhead[i]-offset, val_xfoot[i]+2*offset, val_yfoot[i]);
//绘制名字
is_enemy[i] ? SetTextColor(memDC, rgbRed) : SetTextColor(memDC,rgbGreen);
SelectObject(memDC, font);
TextOutA(memDC, val_xhead[i], val_yhead[i],name[i], strlen(name[i]));
}
BitBlt(hDC, 0, 0, width, height, memDC, 0, 0, SRCCOPY);
DeleteObject(hbitmap);
}
透视效果
注入DLL后,开启一把多人对战,可以看到每个人都被方框绘制出来了,同时也显示了名字(也可以选择显示血量等敌人信息,展示为了画面简洁只显示姓名)。敌我双方也用红色/绿色标识。透视功能实现成功!

代码重构和热键实现
代码重构
之前的自瞄和透视功能写在了两个dll中,而两者代码也有部分重叠。可以考虑将代码重构,合并一些共同变量如人物基址、偏移等。两个头文件如下:
#pragma once
#define offset_Player_base_ptr 0x57E0A8
#define offset_Player_num 0x58AC0C
#define offset_Player_list 0x58AC04
#define offset_viewMatrix 0x57DFD0
#define offset_GameWidth 0x591ED8
#define offset_GameHeight 0x591EDC
#pragma once
#include <Windows.h>
#include "offset.h"
struct Player { //逆向得到的玩家类
char unknown1[4];
float x;
float y;
float z;
char unknown2[0x24];
float yaw;
float pitch;
char unknown3[0x1C9];
char name[16];
char unknown4[0xF7];
int team;
char unknown5[0x8];
int dead;
};
struct ViewMatrix {
//视角矩阵 X, Y, Z, W
float m11, m12, m13, m14; //00, 01, 02, 03
float m21, m22, m23, m24; //04, 05, 06, 07
float m31, m32, m33, m34; //08, 09, 10, 11
float m41, m42, m43, m44; //12, 13, 14, 15
};
//开挂函数
void InitPlayer(); //初始化玩家类
float euclidean_distance(float, float); //勾股定理
bool Seen(Player* target); //该敌人是否可见
void ESP(); //透视
void AutoAim(); //自瞄
void UpdateAim(); //更新准星
//绘图
void Draw(); //绘图
LRESULT CALLBACK WindowProcedure(HWND hwnd, UINT message, WPARAM wParam, LPARAM lParam);
void InitWindow(); //初始化窗口
void DeleteWindow(); //删除窗口
热键绑定
接下来实现自瞄/透视功能的开关。这需要用到热键的绑定。比如按下F1实现自瞄的开启/关闭,按下F2实现透视的开启/关闭。这里需要用到GetAsyncKeyState() & 1获取键盘信息。
以透视功能为例,每次按下F1将修改状态modeESP,如果从关到开需要初始化透明窗口,如果从开到关需要关闭透明窗口。同时如果modeESP开着,需要执行ESP()函数进行坐标的计算和绘制。
while (1) {
//Menu();
if (GetAsyncKeyState(VK_F1) & 1) { //按下F1
modeESP = !modeESP;
if (modeESP == true) {
InitWindow();
}
else{
DeleteWindow();
}
}
if (modeESP) ESP();
if (GetAsyncKeyState(VK_F2) & 1) { //按下F2
modeAutoAim = !modeAutoAim;
}
if (modeAutoAim) AutoAim();
Sleep(1);
}
作品最终展示
本作品实现了对Assualt Cube 1.3.0.2这个FPS游戏的逆向分析,并通过DLL远程线程注入的方式下实现了自瞄/透视两个外挂功能。敲击F1开启/关闭透视功能,敲击F2开启/关闭自瞄功能。
透视功能中敌我双方用红(绿)色方框标识,并标记名字。方框大小也随人物远近动态变化。
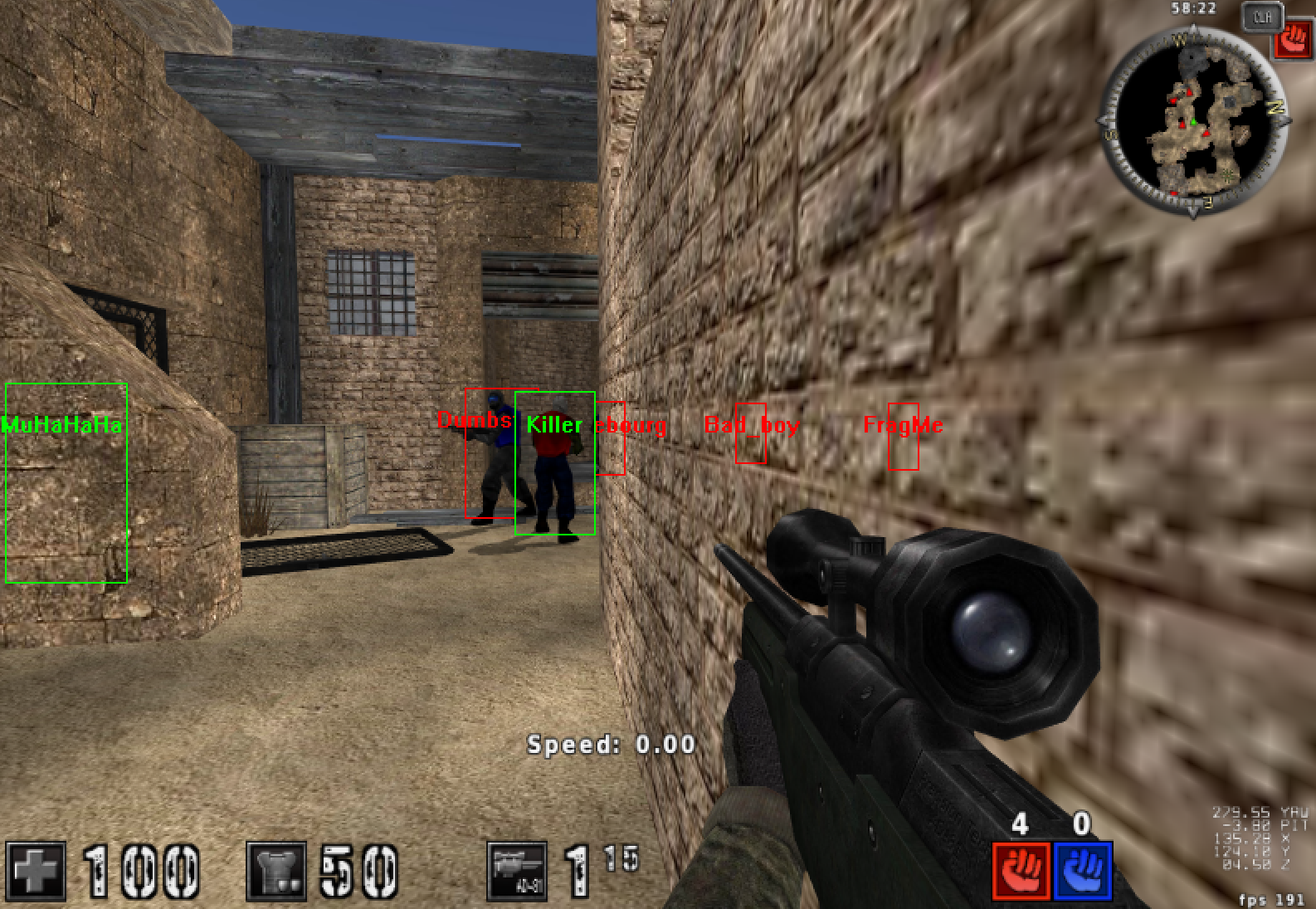
自瞄功能开启后,如果视角范围内存在敌人,准星将自动移到敌人头部。
原本DLL还实现了菜单功能,但是有些许BUG就不展示了....
视频展示见Assault Cube 1.3.0.2 逆向分析 自瞄/透视实现 2023/1/12.
参考博客
About - Game Hacking Academy








")